


第1章 对象导论
1.1 伴随多态的可互换对象
面向对象程序设计语言使用了后期绑定的概念。当向对象发送消息时,被调用的代码直到运行时才能确定。也叫动态绑定。
编译器确保被调用方法的存在,并对调用参数和返回值执行类型检查(Java是强类型的语言,无法提供此类保证的语言被称为是弱类型的),但是并不知道将被执行的确切代码。
在某些语言中,必须明确地声明希望某个方法具备后期绑定属性所带来的灵活性(C++是使用virtual关键字来实现的)。在这些语言中,方法在默认情况下不是动态绑定的。而在Java中,动态绑定是默认行为(Java中除了static方法、final方法和private方法之外,其它所有方法都是动态绑定),不需要添加额外的关键字来实现多态。
把将导出类看做是它的基类的过程称为向上转型(upcasting)
1.2 单根继承结构
在Java中(事实上还包括除C++以外的所有OOP语言),所有的类最终都继承自单一的基类,这个终极基类的名字就是Object。
单根继承结构的好处:
在单根继承结构中所有对象都具有一个共用接口,所以它们归根到底都是相同的基本类型。
单根继承结构保证所有对象都具备某些功能。
单根继承结构使垃圾回收器的实现变得容易得多,而垃圾回收器正是相对C++的重要改进之一。由于所有对象都保证具有其类型信息,因此不会因无法确定对象的类型而陷入僵尸。这对于系统级操作(如异常处理)显得尤其重要,并且给编程带来了更大的灵活性。
1.3 对象的创建和生命期
对象的数据位于何处(作用域):
将对象置于堆栈(它们有时被称为自动变量(automatic variable)或限域变量(scoped variable))或静态存储区域内来实现。这种方式将存储空间分配和释放置于优先考虑的位置,某些情况下这样控制非常有价值。但是,也牺牲了灵活性。
第二种方式是在被称为堆(heap)的内存池中动态地创建对象。在这种方式中,直到运行时才知道需要多少对象,它们的生命周期如何,以及它们的具体类型是什么。
Java完全采用了动态内存分配方式(基本类型只是一种特例)。每当想要创建对象时,就要使用new关键字来构建对象的动态实例。
对象的生命周期:
Java的垃圾回收器被设计用来处理内存释放问题。
第2章 一切都是对象
2.1 特例:基本类型
基本类型是一个并非是引用的“自动”变量。这个变量直接存储“值”,并置于堆栈中,因此更加高效。Java的基本类型所占存储空间大小不随机器硬件架构的变化而变化。这种所占存储空间大小的不变性是Java程序比用其他大多数语言编写的程序更具可移植性的原因之一。
| 基本类型 | 大小 | 最小值 | 最大值 | 包装器类 |
|---|---|---|---|---|
| boolean | - | - | - | Boolean |
| byte | 8 bits | -128 | +127 | Byte |
| char | 16 bits | Unicode 0 | Unicode 216-1 | Character |
| short | 16 bits | -215 | +215-1 | Short |
| int | 32 bits | -232 | +232-1 | Integer |
| float | 32 bits | IEEE754 | IEEE754 | Float |
| long | 64 bits | -263 | +263-1 | Long |
| double | 64 bits | IEEE754 | IEEE754 | Double |
| void | - | - | - | Void |
所有数值类型都有正负号
boolean类型所占存储空间的大小没有明确指定(要看具体虚拟机的实现),仅定义为能够取字面值true或false。
2.2 Java中的数组
Java确保数组会被初始化。而且不能在它的范围之外被访问。这种范围检查,是以每个数组上少量的内存开销及运行时的下标检查为代价的。
《深入理解Java虚拟机》:
Java 语言中对数组的访问比C/C++相对安全是因为:如有一维数组,其元素类型为mypackage.MyClass,则虚拟机会自动生成一个直接继承于java.lang.Object的子类[Lmypackage.MyClass,创建动作由字节码指令newarray触发。这个类代表了一个元素类型为mypackage.MyClass的一维数组,数组中应有的属性和方法(用户可直接使用的只有被修饰为public的length属性和clone()方法)都实现在这个类里。Java语言中对数组的访问比C/C++相对安全就是因为这个类封装了数组元素的访问方法(准确地说,越界检查不是封装在数组元素访问的类中,而是封装在数组访问的xaload、xastore字节码中),而C/C++直接翻译为对数组指针的移动。
// NotInit.javapackage mypackage;
class MyClass{ static{
System.out.println("MyClass Init...");
}
}public class NotInit{ public static void main(String[] args){
MyClass[] a = new MyClass[3];
}
}/*
* 没有输出,说明数组元素没有初始化(虚拟机自动生成了别的类)。
*/数组对象,实际就是一个引用数组,每个元素会被初始化为null。
基本数据类型的数组,编译器会将这种数组所占的内存全部置为零。
在Java语言中,当检查到发生数组越界时会抛出
java.lang.ArrayIndexOutOfBoundsException异常。
2.3 作用域(scope)
1. Java 与 C/C++ 关于作用域的区别:如下,对于Java,非法,而对于 C/C++ 合法。(在 C/C++ 里将一个作用域的变量“隐藏”起来的做法,在Java里是不允许的。因为Java设计者认为这样做会导致程序混乱。)
{ int x = 12;
{ int x = 96; // Illegal for Java, but legal for C/C++
}
}2. Java对象不具备和基本类型一样的生命周期。当用new创建一个Java对象时,它可以存活于作用域之外。如:
{ String s = new String("a string");
} // End of scope引用 s 在作用域终点就消失了。然而,s 指向的 String 对象仍继续占据内存空间。
2.4 import 关键字
import关键字指示编译器导入一个包,也就是一个类库(在其他语言中,一个库不仅包含类,还可能包括方法和数据,但是Java中所有的代码都必须写在类里)。
特定类 java.lang 会被自动导入到每一个Java文件中。
2.5 static 关键字
5.1 通过 static 关键字可以满足以下两方面情形的需要:
只想为某一特定域分配单一存储空间,而不去考虑空间要创建多少对象,甚至根本就不创建任何对象。
希望某个方法不与包含它的类的任何对象关联在一起。也就是说,即使没有创建对象,也能够调用这个方法。
有些面向对象语言采用类数据和类方法两个术语,代表那些数据和方法只是作为整个类,而不是类的某个特定对象而存在的。例:
5.2 static 字段
class StaticTest{
static int i = 47;
} 如下创建两个对象,st1.i 和 st2.i 指向同一存储空间,共享同一个 i ,因此它们具有相同的值47。
StaticTest st1 = new StaticTest(); StaticTest st2 = new StaticTest();
5.3 static 方法
static作用于字段时,会改变数据的创建方式,但作用于方法时,差别却没有那么大。static方法的一个重要用法就是在不创建任何对象的前提下就可以调用它。这一点对定义main()方法很重要(所以main()方法是一个 satic 方法),这个方法是运行一个应用时的入口点。和其它任何方法一样,
static方法可以创建或使用与其类型相同的被命名对象,因此,static方法常常拿来做“牧羊人”的角色,负责看护与其隶属同一类型的实例群。static方法的含义:static方法就是没有this的方法。关于static方法内部是否能调用非静态方法:因为没有this,就没有对象,所以不能直接调用非静态方法,但可以传递一个对象引用到静态方法里,然后通过这个引用(和this效果相同)来调用非静态方法和访问非静态数据成员。有些人认为
static方法不是“面向对象”的,因为它们的确具有全局函数的语义;使用static方法时,由于不存在this,所以不是通过“向对象发送消息”的方式来完成的。
第3章 关系操作符
3.1 测试对象的等价性
==和!=比较的是对象的引用特殊方法
equals()的默认行为也是比较引用
// Equivalence.javapublic class Equivalence{ public static void main(String[] args){
Integer n1 = new Integer(47);
Integer n2 = new Integer(47);
System.out.println(n1 == n2);
System.out.println(n1 != n2);
System.out.println(n1.equals(n2));
Value v1 = new Value();
Value v2 = new Value();
v1.i = v2.i = 47;
System.out.println(v1.equals(v2));
}
}
class Value{ int i;
}/* Output:
* false
* true
* true
* false
*/ 以上,
1. n1 和 n2 是两个不同的引用(明显是两个不同的存储区域),所以二者 !=。
2. equals() 方法是所有对象的特殊方法(继承自Object类),Integer重定义了equals()方法以比较其内容是否相等,所以这里n1.equals(n2) 为 true。equals()不适用于“基本类型”,基本类型直接使用==和!=即可。
3. v1.equals(v2)为 false 验证了 equals()方法默认行为是比较引用,除非在自定义类Value中重定义 equals()方法。
3.2 直接常量
有时直接常量的类型是模棱两可的,这就需要与直接常量相关的某些字符来额外增加一些信息以“指导”编译器,使其能够准确地知道要生成什么样的类型。如果编译器能够正确地识别类型,就不必在数值后增加字符。
在C、C++或者Java中,二进制数没有直接常量表示方法。但是,在使用十六进制和进制的记数法时,以二进制形式显示结果将非常有用。通过使用
Integer和Long类的静态方法toBinaryString()可以很容易地实现这一点。注意,如果将比较小的类型传递给Integer.toBinaryString()方法,则该类型将自动转换为int。
// Literals.javapublic class Literals{ public static void main(String[] args){ int i1 = 0x2f; // Hexadecimal (lowercase)
System.out.println("i1: " + Integer.toBinaryString(i1)); int i2 = 0X2F; // Hexadecimal (uppercase)
System.out.println("i2: " + Integer.toBinaryString(i2)); int i3 = 0177; // Octal (leading zero)
System.out.println("i3: " + Integer.toBinaryString(i3)); char c = 0xffff; // max char hex value
System.out.println("c: " + Integer.toBinaryString(c)); byte b = 0x7f; // max short hex value
System.out.println("b: " + Integer.toBinaryString(b)); short s = 0x7fff; // max short hex value
System.out.println("s: " + Integer.toBinaryString(s)); long n1 = 200L; // long suffix
long n2 = 200l; // long suffix (but can be confusing)
long n3 = 200; float f1 = 1; float f2 = 1F; // float suffix
float f3 = 1f; // float suffix
double d1 = 1d; // double suffix
double d2 = 1D; // dobule suffix
// (Hex and Octal also work with long)
} /* OUtput:
* i1: 101111
* i2: 101111
* i3: 1111111
* c: 1111111111111111
* b: 1111111
* s: 111111111111111
* */}-
指数计数法。在C、C++以及Java中,
e代表“10的幂次”,与科学与工程领域中“e”代表自然对数的基数(约等于2.718,Java中的Math.E给出了更精确的double型的值)不同。根据John Kirkham的描述,Java语言中 e 与 科学工程领域不同,可能跟60年代的FORTRAN有关。
// Exponents.java// "e" means "10 to the power."public class Exponents { public static void main(String[] args){ // Uppercase and lowercase 'e' are the same:
float expFloat = 1.39E-43f;
expFloat = 1.39e-43f;
System.out.println(expFloat); double expDouble = 47e47d; // 'd' is optional
double expDouble2 = 47e47; // Automaticall double
System.out.println(expDouble);
} /* Output:
*1.39E-43
*4.7E48
*/}3.3 类型转换(cast)操作符
Java中布尔类型,不允许进行任何类型的转换处理,其它基本类型都可转换成别的基本数据类型。
-
将float和double转型为整型值时,总是对该数字执行截尾。如果想要得到舍入的结果,就需要使用
java.lang.Math中的round()方法。// CastingNumbers.java// What happens when you cast a float or double to an integral value ?public class CastingNumbers{ public static void main(String[] args){ double above = 0.7, below = 0.4; float fabove = 0.7f, fbelow = 0.4f; System.out.println("(int)above: " + (int)above); System.out.println("(int)below: " + (int)below); System.out.println("(int)fabove: " + (int)fabove); System.out.println("(int)fbelow: " + (int)fbelow); System.out.println("Math.round(above): " + Math.round(above)); System.out.println("Math.round(above): " + Math.round(above)); System.out.println("Math.round(below): " + Math.round(below)); System.out.println("Math.round(fabove): " + Math.round(fabove)); System.out.println("Math.round(fbelow): " + Math.round(fbelow)); } }/* Output: (int)above: 0 (int)below: 0 (int)fabove: 0 (int)fbelow: 0 Math.round(above): 1 Math.round(below): 0 Math.round(fabove): 1 Math.round(fbelow): 0 */ 提升。如果对基本类型执行算术运算或按位运算,只要类型比int小(即
char、byte或者short),那么在运算之前,这些值会自动转换成int。这样一来,最终生成的结果就是int型。如果想把结果赋值给较小的类型,就必须使用类型转换(既然把结果赋给了较小的类型,就可能出现信息丢失)。通常,表达式中出现的最大的数据类型决定了表达式最终结果的数据类型。如果一个float值与一个double值相乘,结果就是double,如果将一个int和一个long值相加,则结果就为long。-
溢出。如果对两个足够大的int值执行乘法运算,结果就会溢出。编译器不会发出错误或警告信息,运行时也不会出现异常。这说明Java虽然是好东西,但也没有那么好!
// Overflow.java// Surprise! Java lets you overflow.public class Overflow{ public static void main(String[] args){ int big = Integer.MAX_VALUE; System.out.println("big = " + big); int big1 = big + 1; System.out.println("big1 = " + big1); int bigger = big * 4; System.out.println("bigger = " + bigger); } }/* Output: big = 2147483647 big1 = -2147483648 bigger = -4 */
3.4 Java没有sizeof()操作符
在C和C++中,sizeof()操作符可以告诉你为数据项分配的字节数。使用这个操作符的最大原因是为了进行一些与存储空间有关的运算,使程序可以在不同平台上“移植”。而Java不需要sizeof()操作符来满足这方面的需要,因为所有数据类型在所有机器中的大小是相同的。我们不必考虑移植问题——它已经被设计在语言中了。
第4章 控制执行流程
4.1 true 和 false
注意Java不允许我们将一个数字作为布尔值使用,这与C和C++ 不同(C/C++中,“真”是非零,而“假”是零)。如果将数字作为布尔表达式,Java编译器会直接报错。
4.2 switch
switch要求使用一个选择因子:
在JDK5之前,选择因子必须是int或char那样的整数值。
JDK1.5开始,Java增加了新特性
enum,使得enum可以与switch协调工作。JDK1.7开始,switch开始支持String作为选择因子。在switch语句中,String的比较用的是
String.equals()。因此,需要注意,传给switch的String变量不能为null,同时switch的case子句中使用的字符串也不能为null。显然是因为:如果switch传入的是null,则在运行时对null对象调用
hashCode(String.equals()会调用)方法会出现NullPointException。如果case写的是null,那么在编译时无法求出hashCode,因此编译时就会报错。
switch支持String只是一个语法糖,由javac来负责生成相应的代码。底层的JVM在switch上并没有进行修改。
第5章 初始化与清理(cleanup)
5.1 方法重载(method overloading)
重载方法,方法名相同,形式参数列表不同(参数列表又叫参数签名,包括参数的类型、参数的个数和参数的顺序,只要有一个不同就叫做参数列表不同)。重载是面向对象的一个基本特性。
声明为final的方法不能被重载
声明为static的方法不能重载,但是能够被再次声明。
重载方法的返回类型可以相同也可以不同,但仅返回类型不同不足以成为方法的重载。
-
编译器根据调用方法的签名逐个匹配,以选择对应方法的过程叫做重载分辨(Overload Resolution,或叫重载决议)。
1. 《深入理解Java虚拟机》:虚拟机(准确地说是编译器)在重载时是通过参数的静态类型(Static Type )或叫外观类型(Apparent Type)而不是实际类型(Actual Type)作为判定依据的。
2. 《深入理解Java虚拟机》:编译期间选择静态分派目标的过程是Java语言实现方法重载的本质。
5.2 this 关键字
`this` 关键字只能在方法内部使用,表示对“**调用方法的那个对象**”的引用。
5.3 清理:终结处理和垃圾回收
5.3.1 finalize()
Java中的
finalize()不等于C++中的析构函数当发生“垃圾回收”时,
finalize()才得到调用Java里的对象并非总是被垃圾回收(因为Java的“垃圾回收”并不能保证一定会发生)
对象可能不被垃圾回收
垃圾回收并不等于“析构”
Java并未提供“析构函数”或相似的概念,Java的“垃圾回收”不保证一定会发生,所以要做类似的清理工作,必须自己动手创建一个执行清理工作的普通方法。
只要程序没有濒临存储空间用完的那一刻,垃圾回收可能就会一直没有发生。这个策略是恰当的,因为垃圾回收本身也有开销,要是不使用它,那就不用支付这部分开销了。
5.3.2 finalize()用途何在
由于垃圾回收器会负责释放对象占据的所有内存,这就将finalize()的需求限制到一种特殊情况,即通过某种创建对象方式以外的方式为对象分配了存储空间。由于Java中一切皆为对象,所以那种特殊情况主要发生在使用“本地方法”的情况下,本地方法是一种在Java中调用非Java代码的方式。
不要过多地使用finalize(),它不是进行普通的清理工作的合适场所。
Joshua Bloch在题为“避免使用终结函数”一节中走得更远,他提到:“终结无法预料,常常是危险的,总之是多余的。”《Effective Java》,第20页,(Addison-Wesley 2001)
5.4 成员初始化
Java尽力保证:所有变量在使用前都能得到恰当的初始化。
对于方法的局部变量,如果使用前没有初始化,Java以编译时错误(注意,如果方法内的局部变量未被使用,将不会编译错误)的形式来贯彻这种保证。
-
对于类的成员变量:
// InitialValues.javapublic class InitialValues{ int j; char c; MyClass mc; public static void main(String[] args){ int i; //i++; // Error -- i not initialized InitialValues obj = new InitialValues(); System.out.println(obj.c); System.out.println(obj.j); System.out.println(obj.mc); } } class MyClass{}// Counter.javapublic class Counter{ int i; Counter(){ i = 7; } } 无法阻止自动初始化的进行,它将在构造器被调用之前发生,如下,
i首先会被置0,然后变成7。成员变量是基本类型,Java会自动初始化初值0;
成员变量是引用类型,Java会自动初始化初值null;
5.5 对象的创建过程
假设有个名为Dog的类:
静态方法或域。当首次创建类对象时(构造器可以看成静态方法,但不是)或类的静态方法/静态域首次被访问时,Java解释器必须查找类路径,以定位Dog.class文件;
载入Dog.class,执行静态初始化的所有动作,且只执行这一次;
当调用
new Dog()时,首先将在堆上分配存储空间;存储空间清零。所以成员变量会置成0或null;
执行所有出现于字段定义处的初始化动作。
执行构造器。
5.6 数组初始化
可以将Java中的数组作为一种数组类型来理解。
如
int[] a;可以认为是a是一个数组引用,初始值为null初始化:
int[] a = new int[3];初始化各元素值为0,对于boolean,初始值为false;int[] a = {1, 2, 3};初始化元素分别为1, 2, 3;
第6章 访问权限控制
6.1 Java解释器的运行过程:
首先,找出环境变量CLASSPATH,用作查找.class文件的根目录。
然后,从根目录开始,解释器获取包的名称并将句点替换成反斜杠(于是,package net.mrliuli.training 就变为 net\mrliuli\training 或 net/mrluli/training 或其他,这一切取决于操作系统)以从CLASSPATH根中获取一个相对路径。
将CLASSPATH根目录与上面获取的相对路径相连接得到一个绝对路径,用来查找.class文件。
Sun 将Java2中的JDK改造得更聪明了一些。在安装后你会发现,即使你未设立CLASSPATH,你也可以编译并运行基本的Java程序。
6.2 类的访问权限的一些限制
同一个.java文件,只能有一个与文件同名的public类,可以有其它非public类;
同一个package内的不同文件中的类,可以互相访问。
不同package中的类,如需访问,需要使用全限定名,如biz.superalloy.MyClass或通过import把biz.superalloy包引进来;
类中的成员变量,不声明访问修饰符时,为“包访问权限”,有时也表示friendly,同一个文件的不同类之间可以互相访问。
如果没能为类访问权限指定一个访问修饰符,它将会默认得到包访问权限。
第7章 复用类
7.1 名称屏蔽
在C++中,如果基类拥有一个已被多次重载的方法名称,那么在其派生类中重新定义该方法名称,就会屏蔽其基类中的任何版本,这叫做名称屏蔽。但是在Java中,就种情况下,不会发生名称屏蔽,即无论在派生类还是在基类中对方法进行定义,重载机制都可以正常工作。
如下C++会产生名称屏蔽:
// Hide.cpp
// #include "Hide.h"#include <iostream>using namespace::std;
// Hide.h startclass Homer {
public: Homer();
~Homer();
void doh(char);
void doh(float);
};class Milhouse {
public: Milhouse();
~Milhouse();
};class Bart : public Homer {
public: Bart();
~Bart();
void doh(Milhouse*);
};
// Hide.h endHomer::Homer(){}Homer::~Homer(){}
void Homer::doh(char c){
cout << "doh(char)" << endl;
}
void Homer::doh(float f){
cout << "doh(float)" << endl;
}Milhouse::Milhouse(){}Milhouse::~Milhouse(){}Bart::Bart(){ Homer();
}Bart::~Bart(){}
void Bart::doh(Milhouse* m){
cout << "doh(Milhouse)" << endl;
}
int main(int argc, char* argv[]){ Bart* b = new Bart();
//b->doh('x'); // error C2664: 'void Bart::doh(Milhouse *)': cannot convert argument 1 from 'char' to 'Milhouse *'
//b->doh(1.0f); // error C2664: 'void Bart::doh(Milhouse *)': cannot convert argument 1 from 'float' to 'Milhouse *'
b->doh(new Milhouse());
return 0;
}
/* Output:
* doh(Milhouse)*/而Java不会产生:
// Hide.javaclass Homer{
void doh(char c){
System.out.println("doh(char)");
} void doh(float f){
System.out.println("doh(float)");
}
}class Milhouse{}class Bart extends Homer{
/* 如果使用这个注解,编译时会报错:
* “方法不会覆盖或实现超类型的方法” -- method does not override a method from its superclass
* 因为你是想要重写的,但却进行了重载。
*/
//@Override
void doh(Milhouse m){
System.out.println("doh(Milhouse)");
}
}public class Hide{
public static void main(String[] args){
Bart b = new Bart();
b.doh('x');
b.doh(1.0f);
b.doh(new Milhouse());
}
}/* Output:
* doh(char)
* doh(float)
* doh(Milhouse)
*/7.2 @Override注解
Java SE5新增加了@Override注解,可以把它当作关键字来用,它的作用是告诉编译器我想重写这个方法,因为Java不会产生名称屏蔽,所以如果我不留心重载了,编译器就会报错来告诉我违背了我的初衷。
7.3 final关键字
根据上下文环境,Java的关键字final的含义存在着细微的区别,但通常它指的是“这是无法改变的。”不想改变可能出于两种理由:设计或效率。可能使用到final的三种情况:数据、方法和类。
7.3.1 final数据
final 基本类型数据
基本类型变量应用final关键字时,将向编译器告之此变量是恒定不变的,即它是编译期常量。这样编译器可在编译时执行计算式,从而减轻了运行时负担(提高效率)。编译期常量在定义(声明)时必须对其赋值(声明时也可以不赋(此时叫空白final),但必须在构造器中赋值,所以final域在使用前总是被初始化。)。final常量常与static一起使用,强调只有一份。编译期常量(带有恒定初始值),即 static final 的基本类型变量全用大写字母命名,并且字与字之间用下划线隔开(这就像C常量一样,C常量是这一命名传统的发源地)。ds
- final 对象引用
用于对象引用,则引用恒定不变,即一旦引用初始化指向一个对象,就无法再把它改变为指向另一个引用,但对象其自身是可以被修改的。这种情形同样适用数组,因为如前面所述,Java数组也可(看作)是引用。
final参数
指明为final的方法参数,意味着方法内只能读而不能修改参数,这一特性主要用来向匿名内部类传递数据。
7.3.2 final方法
使用
final方法的原因有两个:锁定方法,以防任何继承类修改它的含义。这是出于设计的考虑。
效率。在Java早期版本中,方法声明为
final,就是同意编译器针对该方法的所有调用都转为内嵌调用。而在Java SE5/6时,应该让编译器和JVM云处理效率问题,只有在想要明确禁止覆盖时,才将方法设置为final的。final和private关键字类中所有的
private方法都隐式地指定为是final的。由于无法取用private方法,所以也就无法覆盖它。派生类中试图“覆盖”父类中一个
private方法(隐含是final的),似乎奏效,编译器不会出错,但实际上只是在派生类中生成了一个新的方法,此时并没有覆盖父类的private方法。
// FinalOverridingIllusion.javaclass WithFinals{
private final void f(){
System.out.println("WithFinals.f()");
} // Automatically "final"
private void g(){
System.out.println("WithFinals.g()");
}
}class OverridingPrivate extends WithFinals{
public final void f(){
System.out.println("OverridingPrivate.f()");
} public void g(){
System.out.println("OverridingPrivate.g()");
}
}public class FinalOverridingIllusion{
public static void main(String[] args){
OverridingPrivate op = new OverridingPrivate();
op.f();
op.g(); // You can upcast
WithFinals wf = op; // But you can't call the methods:
//wf.f();
//wf.g();
}
}/* Output:
* OverridingPrivate.f()
* OverridingPrivate.g()
* */7.3.3 final类
final类表明对该类的设计永不需要变动,或者出于安全的考虑,你不希望它有子类。因为final类禁止继承,所以final类中所有的方法都隐式指定为是final的,因为无法覆盖它们。在final类中可以给方法添加final修饰词,但这不会增添任何意义。
7.3.4 有关final的忠告
在设计类时,将方法指明是final的,应该说是明智的。
- Java1.0/1.1中Vector类中的方法均没有设计成final的,然后Statck继承了Vector,就是说Stack是个Vector,这从逻辑观点看是不正确的,还有Vector中的addElement()和elementAt()是同步的,导致执行开销大,可能会抹煞final的好处。所以Vector的设计不合理,现代Java的容器ArrayList替代了Vector。ArrayList要合理得多,但遗憾的是仍然存在用旧容器库编写新程序代码的情况。
- Java1.0/1.1中的Hashtable类也是不包含任何final方法。现代Java的容器库用HashMap代替了Hastable。
7.4. 初始化及类的加载
7.4.1 类的加载
Java采用了一种不同的对类加载的方式,Java每个类的编译代码都存在于它自己的独立的文件中(.class文件)。该文件只在其代码需要被使用时才会被加载(That file isn’t loaded until the code is needed)。通常,可以说“类的代码在初次使用时才加载。”这通常是指加载发生于构造类的第一个对象之时,但是当访问static域或static方法时,也会发生加载。(构造器也是static方法,尽管static关键字并没有地写出来。因此更准确地讲,++类是在其任何static成员被访问时加载的++。)
7.4.2 初始化
初次使用之处也是staic初始化发生之处。所有的static对象和static代码段都会在加载时依程序中的顺序(即,定义类时的书写顺序)而依次初始化。当然,定义为static的东西只会被初始化一次。
第8章 多态(Polymorphism)
多态(也称作动态绑定、后期绑定或运行时绑定)。
8.1 方法调用绑定(Method-call binding)
将一个方法调用与一个方法主体关联起来称作绑定。Connecting a mehtod call to a mehtod body is called binding.
-
若在程序执行前进行绑定(如果有的话,由编译器和连接程序实现),叫做前期绑定。它是面向过程语言中不需要选择就默认的绑定方式。例如,C只有一种方法调用,那就是前期绑定。
When binding is performed before the program is run (by the compiler and linker, if there is one), it’s called early binding. You might not have heared the term before because it has never been an option with procedural language. C compilers have only one kind of method call, and that’s early binding.
-
后期绑定,就是在运行时根据对象的类型进行绑定。后期绑定也叫做动态绑定或运行时绑定。如果一种语言想实现后期绑定,就必须具有某种机制,以便在运行时能判断对象的类型,从而调用恰当的方法。也就是说,编译器一直不知道对象的类型,但是方法调用机制能找到正确的方法体,并加以调用。后期绑定机制随编程语言的不同而有所不同,但是只要想一下就会得知,不管怎样都必须在对象中安置某种“类型信息”。
The solution is called late binding, which means that the binding occurs at run time, based on the type of object. Late binding is also called dynamic binding or runtime binding. When a language implements late binding, there must be some mechanism to determine the type of the object at run time and to call the appropriate method. That is, the compiler still doesn’t know the object type, but the mehtod-callmechanism finds out and calls the correct method body. The late-binding mechanism varies from language to language, but you can imagine that some sort of type information must be installd in the objects.
-
再谈final方法。
如Chapter7所说,final方法可以防止其他人覆盖该方法。但更重要的一点是:这样做可以有效地“关闭”动态绑定,或者说,告诉编译器不需要对其进行动态绑定。这样,编译器就可以为final方法调用生成更有效的代码。然而,大多数情况下,这样做对程序的整体性能不会有什么改观。所以,最好根据设计来决定是否使用final,而不是出于试图提高性能的目的来使用final。Why would you declare a method final? As noted in the last chapter, it prevents anyone from overriding that method. Perhaps more important, it effectively “turns off” dynamic binding, or rather it tells the compiler that dynamic binding isn’t necessary.This allows the compiler to generate slightly more efficient code for final method calls. However, in most cases it won’t make any overall performance diffeence in your program, so it’s best to only use final as a design decision, and not as an attempt to improve performance.
8.2 域与静态方法
域是不具有多态性的,只有普通的方法调用是多态的。如果直接访问某个域,这个访问就将在编译期进行解析,即域是静态解析的。
如下,当Sub对象转型为Super引用时,任何域访问操作都将由编译器解析,因此不是多态的。Super.field和Sub.field分配了不同的存储空间。这样,Sub实际上包含两个称为field的域:它自己的和它从Super处得到的。
// FieldAccess.java// Direct field access is determined at compile time.class Super{ public int field = 0; public int getField(){return field;}
}
class Sub extends Super{ public int field = 1; public int getField(){return field;} public int getSuperField(){return super.getField();}
}public class FieldAccess{
public static void main(String[] args){
Super sup = new Sub(); // Upcast
System.out.println("sup.field = " + sup.field + ". sup.getField() = " + sup.getField());
Sub sub = new Sub();
System.out.println("sub.field = " + sub.field + ". sub.getFiled() = " + sub.getField() + ". sub.getSuperField() = " + sub.getSuperField());
}
}/** Output:
* sup.field = 0. sup.getField() = 1
* sub.field = 1. sub.getFiled() = 1. sub.getSuperField() = 0
*/静态方法也是不具有多态性的,如前文所述,静态方法是与类,而非与单个的对象相关联的。
8.3 构造器内部的多态方法的行为
如果在构造器内部调用正在构造的对象的某个动态绑定方法,由于动态绑定是在运行时才决定的,而此时,该对象还正在构造中,所以它不知道自己属于哪个类(父类还是自己),并且方法所操纵的成员可能还未进行初始化,这可能会产生一引起难于发现的隐藏错误。
// PolyConstructors.java// Constructors and polymorphism// don't produce what you might expectclass Glyph{
void draw(){
System.out.println("Glyph.draw()");
}
Glyph(){
System.out.println("Glyph() before draw()");
draw();
System.out.println("Glyph() after draw()");
}
}class RoundGlyph extends Glyph{
RoundGlyph(int r){
radius = r;
System.out.println("RoundGlyph.RoundGlyph(), radius = " + radius);
}
private int radius = 1;
void draw(){
System.out.println("RoundGlyph.draw(), radius = " + radius);
}
}
public class PolyConstructors {
public static void main(String[] args){ new RoundGlyph(5);
}
}/**Output:
* Glyph() before draw()
* RoundGlyph.draw(), radius = 0
* Glyph() after draw()
* RoundGlyph.RoundGlyph(), radius = 5
*/ 以上代码,构造RoundGlyph对象时,先调用父类构造器Glyph(),父类构造器中如我们所期,调用了多态的draw(),但是,由于 子类还没构造完成,所以打印的成员变量radius的值是0,而并不是我们想象的其默认的初始值1。
8.4 初始化的实际过程
在其他任何事物发生之前,将分配给对象的存储空间初始化成二进制的零。
如前所述那样调用构造器。
按照声明的顺序调用成员的初始化方法。
调用导出类(派生类)的构造器主体。
第9章 接口
9.1 在C++中,只有抽象类的概念(没有abstract关键字),没有接口的说法
C++通过
virtual关键字将类内方法声明为虚函数(如virtual void f();)来实现多态(在C++中,派生类只能重写父类的虚函数,而在Java中,除static方法外,其它方法都是可以被重写的,即默认都是多态的。)。除此以外,包含虚函数的类与其它类没有区别。对虚函数如
virtual void f() = 0;声明时,构成纯虚函数。因为纯虚函数没有函数体,不是完整的函数,无法调用,也无法为其分配内存空间,无法实例化,也就无法创建对象,所以在C++中含有纯虚函数的类被称为抽象类(Abstract Class,注意在C++中,没有abstract关键字)。抽象类通常作为基类(叫做抽象基类),让派生类去实现纯虚函数。派生类必须实现纯虚函数才能被实例化。
9.2 在Java中,有abstract 和 interface 关键字,通过它们来定义抽象类和接口
在
class前添加abstract关键字,定义成抽象类。抽象类不能实例化,即不能通过
new生成对象,但注意可以追加{}生成匿名实现类,仍然不是它自己的实例化。抽象类可以有构造函数,但不能直接调用,通常由实现类构造函数调用。
抽象类的方法前添加
abstract关键字,定义抽象方法,相当于C++的纯虚函数,派生类必须重写该方法,然后才能实例化。Java类中如有抽象方法,则类符号前必须也要添加abstract关键字,定义为抽象类(可以没有抽象方法)。抽象类中可以没有抽象方法,即可以全部是含方法体的非抽象方法。
抽象类进一步抽象,即所有方法都没有具体实现,只声明了方法的形式(同C++头文件中函数的声明格式),并且把
class关键字改成interface关键字,这就创建了一个接口。接口可以包含域,且隐式地是
static和final的,显然,接口中的域不能是空final,这些域不是接口的一部分,它们存储在该 接口的静态存储区域内。接口关键字
interface前可以添加public修饰符,不加默认是包访问权限,接口的方法默认都是public的。因为Java接口没有任何具体实现,即没有任何与接口相关的存储,因此可以定义一个Java类来
implements多个接口,达到C++中多重继承的效果。Java可以定义一个接口去
extends另外的一个或多个接口来实现接口的扩展。因为Java接口中的域自动是final和static的,所以接口就成了一种便捷的创建常量组的工具。在Java SE5之前,用这种方式来产生enum的效果。Java SE5之后,Java有了
enum关键字,因此使用接口来群组常量就没意义了。
第10章 内部类
10.1 链接到外部类(Java非static的普通内部类自动拥有对其外围类所有成员的访问权)。
Java普通内部类能访问其外围对象(enclosing object)的所有成员,而不需要任何特殊条件 。C++嵌套类的设计只是单纯的名字隐藏机制,与外围对象没有联系,也没有隐含的访问权。在Java中,当某个类创建一个内部类对象时,此内部类对象必定会秘密地捕获一个指向那个外围类的对象的引用。然后,在你访问此外围类的成员时,就是用那个引用来选择外围类的成员。这些细节是由编译器处理的。Java的迭代器复用了这个特性。
// Sequence.javainterface Selector{ boolean end();
Object current(); void next();
}public class Sequence{
private Object[] items; private int next = 0; public Sequence(int size){ items = new Object[size]; } public void add(Object x){ if(next != items.length) items[next++] = x;
} private class SequenceSelector implements Selector{
private int i = 0; public boolean end(){ return i == items.length; } public Object current(){ return items[i]; } public void next(){ if (i < items.length) i++; }
} public Selector selector(){ return new SequenceSelector(); } public static void main(String[] args){
Sequence sequence = new Sequence(10); for(int i = 0; i < 10; i++){
sequence.add(Integer.toString(i));
}
Selector selector = sequence.selector(); while(!selector.end()){
System.out.print(selector.current() + " ");
selector.next();
}
System.out.println();
}
}/**Output:
* 0 1 2 3 4 5 6 7 8 9
*/10.2 .this 与 .new
Java非static的普通内部类可应用
.this返回其外围对象的引用。外围对象可应用
.new来生成一个内部类对象。
// DotThis.java// Qualifying access to the outer-class object.public class DotThis{ void f(){ System.out.println("DotThis.f()"); } public class Inner{ public DotThis outer(){ return DotThis.this; // a plain "this" would be Inner's "this"
}
} public Inner inner(){ return new Inner(); } public static void main(String[] args){
DotThis dt = new DotThis();
DotThis.Inner dti = dt.inner();
dti.outer().f();
}
}/*Output:
* DotThis.f()
*/10.3 匿名内部类
Anonymous Inner Class.
10.4 Java嵌套类
内部类声明为static时,不再包含外围对象的引用.this,称为嵌套类(与C++嵌套类大致相似,只不过在C++中那些类不能访问私有成员,而在Java中可以访问)。
- 创建嵌套类,不需要外围对象。
- 不能从嵌套类的对象中访问非静态的外围对象。
10.4.1 接口内部的类
嵌套类可以作为接口的一部分(正常情况下,接口内部不能放置任何代码)。放到接口中的任何类都自动是public和static的。因为类是static的,只是将嵌套类置于接口的命名空间内,这并不违反接口的规则
10.4.2 从多层嵌套类中访问外部类的成员
一个内部类被嵌套多少层并不重要——它能透明地访问它所嵌入的外围类的所有成员,如下:
// MultiNestingAccess.javaclass MNA{ private void f(){}
class A{ private void g(){} public class B{ void h(){
g();
f();
}
}
}
}public class MultiNestingAccess{ public static void main(String[] args){
MNA mna = new MNA();
MNA.A mnaa = mna.new A();
MNA.A.B mnaab = mnaa.new B();
mnaab.h();
}
}10.5 为什么需要内部类
内部类继承自某个类或实现某个接口,内部类的代码操作创建它的外围类的对象。所以可以认为内部类提供了某种进入其外围类的窗口。
内部类实现一个接口与外围类实现这个接口有什么区别呢?答案是:后者不是总能享用到接口带来的方便,有时需要用到接口的实现。所以,使用内部类最吸引人的原因是:
每个内部类才能独立地继承自一个(接口的)实现,所以无论外围类是否已经继承了某个(接口的)实现,对于内部类都没有影响。内部类使得多重继承的解决方案变得完整。接口解决了部分问题,而内部类有效地实现了“多重继承”。也就是说,内部类使得Java实现继承多个非接口类型(类或抽象类)。
// MultiInterfaces.java// two ways tha a clas can implement multiple interface.interface A{}interface B{}class X implements A, B {}class Y implements A {
B makeB(){ // Amonymous inner class
return new B() {};
}
}public class MultiInterfaces{
static void takesA(A a){} static void takesB(B b){} public static void main(String[] args){
X x = new X();
Y y = new Y();
takesA(x);
takesB(x);
takesA(y);
takesB(y.makeB());
}
}10.6 闭包与回调
闭包(closure)是一个可调用的对象,它记录了一些信息,这些信息来自于创建它的作用域。通过这个定义可以看出内部类是面向对象的闭包,因为它不仅包含外围类对象(创建内部类的作用域)的信息,还自动拥有一个指向此外围类对象的引用(
.this),在此作用域内,内部类有权操作所有的成员,包括private成员。回调(callback),通过回调,对象能够携带一些信息,这些信息允许它在稍后的某个时刻调用初始的对象。Java中没有指针,通过内部类提供的闭包功能可以实现回调。
// Callbacks.java// using inner classes for callbacksinterface Incrementable{
void increment();
}// Very simple to just implement the interface:class Callee1 implements Incrementable{
private int i = 0; public void increment(){
System.out.println(++i);
}
}class MyIncrement{
public void increment(){ System.out.println("Other operation"); } static void f(MyIncrement mi) { mi.increment(); }
}// If your class must implement increment() in some other way, you must use an inner class:class Callee2 extends MyIncrement{
private int i = 0; public void increment(){ super.increment();
System.out.println(++i);
} private class Closure implements Incrementable{
public void increment(){ // Specify outer-class method, otherwise you'd get an infinite recursion:
Callee2.this.increment();
}
}
Incrementable getCallbackReference(){ return new Closure();
}
}class Caller{
private Incrementable callbackReference;
Caller(Incrementable cbh){ callbackReference = cbh; } void go(){ callbackReference.increment(); }
}public class Callbacks {
public static void main(String[] args){
Callee1 c1 = new Callee1();
Callee2 c2 = new Callee2();
MyIncrement.f(c2);
Caller caller1 = new Caller(c1);
Caller caller2 = new Caller(c2.getCallbackReference());
caller1.go();
caller1.go();
caller2.go();
caller2.go();
}
}/**Uoutput:
* Other operation
* 1
* 1
* 2
* Other operation
* 2
* Other operation
* 3
**/10.7 Java接口和内部类总结
Java的接口和内部类比其他面向对象的概念更深奥复杂,C++没有这些,将两者结合起来,同样能够解决C++中的用多重继承所能解决的问题。
第11章 持有对象
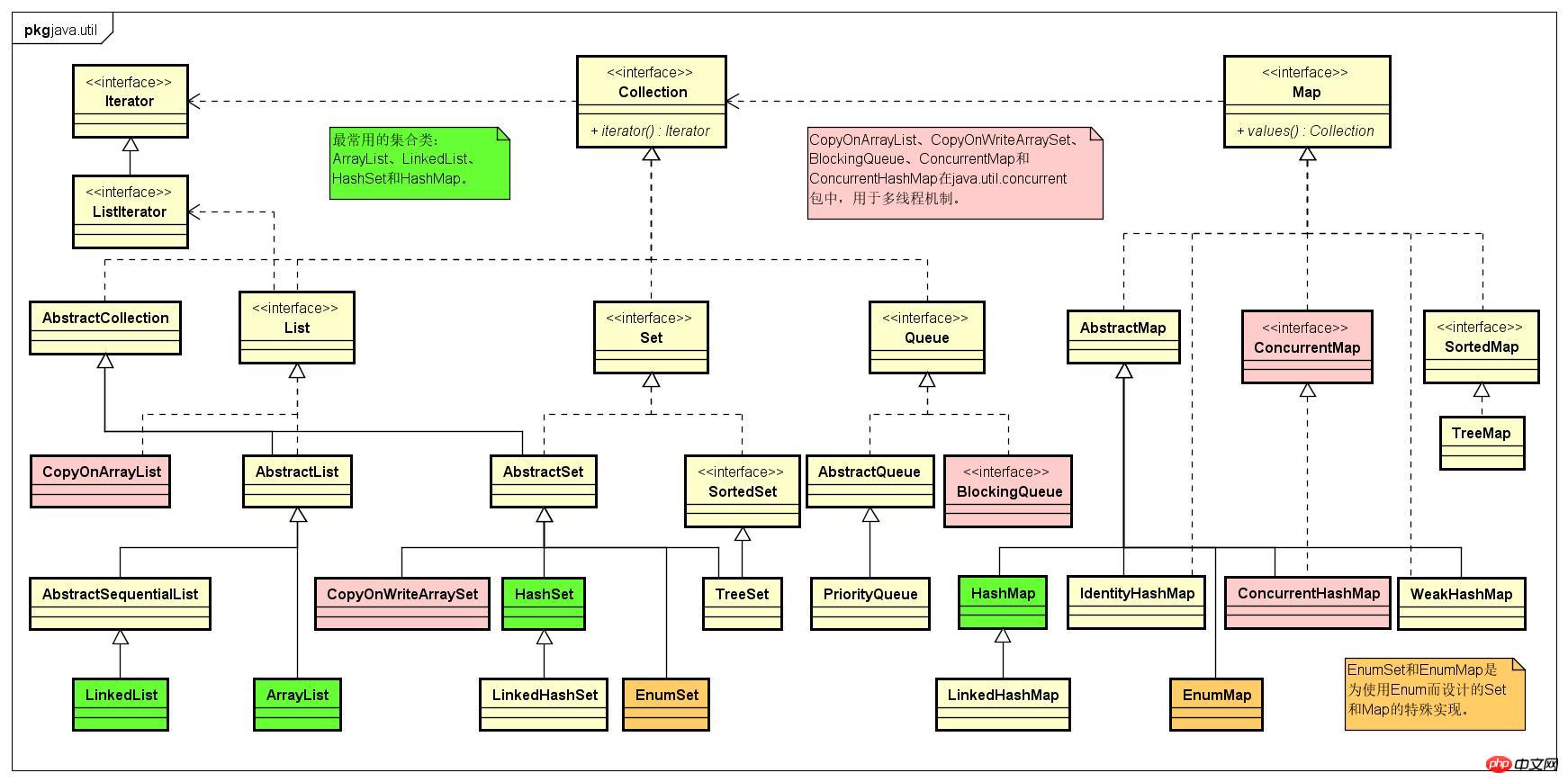
11.1 迭代器(Iterator)
Iterator迭代器使得客户端程序员不必知道或关心容器类的底层结构。ListIterator只能用于各种List类的访问。ListIterator可以双向移动,而Iteraotr只能向前移动。
11.2 ArrayList 和 LinkedList
都可自动扩容。
ArrayList底层是数组结构,即连续存储空间,所以读取元素快。因可自动扩容,所以可以把ArrayList当作“可自动扩充自身尺寸的数组”看待。LinkedList是链表结构,所以插入元素快。LinkedList具有能够直接实现栈(Stack)的所有功能的方法,因此可以直接将LinkedList作为栈使用。LinkdedList也提供了支持队列(Queue)行为的方法,并且实现了Queue接口,所以也可以用作Queue。
11.3 Set 不保存重复元素
11.4 Map 将对象映射到其他对象的能力是一种解决编程问题的杀手锏
11.5 Collection 和 Iterator
在Java中,Collection是描述所有序列容器的共性的根接口,它可能会被 认为是一个“附属接口”,即因为要表示其他若干个接口的共性而出现的接口。而在标准C++类库中并没有其容器的任何公共基类——容器之间的所有共性都是通过迭代器达成的。Java将两种方法绑定到了一起,因为实现Collection就意味着需要提供iterator()方法。
11.5 Foreach与迭代器
foreach语法用于任何实现了Iterable接口的类。Collection接口扩展了Iterable接口,所以所有Collection对象都适用foreach语法。
11.6 容器的元素类型
泛型之前的容器不能持有基本类型元素,显然数组是可以的。但是有了泛型,容器就可以指定并检查它们所持有对象的类型,并且有了自动包装机制,容器看起来还能够持有基本类型。
在Java中,任何基本类型都不能作为类型参数。因此不能创建
ArrayListbd43222e33876353aff11e13a7dc75f6或HashMap4101e4c0559e7df80e541d0df514fd80之类的东西。但是可以利用自动包装机制和基本类型的包装器来解决,自动包装机制将自动地实现int到Integer的双向转换:
// ListOfInt.javaimport java.util.*;public class ListOfInt{ public static void main(String[] args){ // 编译错误:意外的类型
// List<int> li = new ArrayList<int>();
// Map<int, Interger> m = new HashMap<int, Integer>();
List<Integer> li = new ArrayList<Integer>(); for(int i = 0; i < 5; i++){
li.add(i); // int --> Integer
} for(int i : li){ // Integer --> int
System.out.print(i + " ");
}
}
}/* Output:
0 1 2 3 4
*/第12章 通过异常处理错误
12.1 异常
异常允许我们(如果没有其他手段)强制程序停止运行,并告诉我们出现了什么问题,或者(理想状态下)强制程序处理问题,并返回到稳定状态。
12.2 终止与恢复
异常处理理论上有两种基本模型。长久以来,尽管程序员们使用的操作系统支持恢复模型的异常处理,但他们最终还是转向使用类似“终止模型”的代码,并且忽略恢复行为。
Java支持终止模型(它是Java和C++所支持的模型)。这种模型假设错误非常关键,以至于程序无法返回到异常发生的地方继续执行。
另一种模型称为恢复模型。意思是异常处理程序的工作是修正错误,然后重新尝试调用出问题的方法,并认为第二次能成功。
12.3 创建自定义异常
所有标准异常都有两个构造器:一个是默认构造器;另一个是接受字符串作为参数,以便能把相关信息放入异常对象的构造器。
// FullConstructors.javaclass MyException extends Exception{ public MyException(){} public MyException(String msg){ super(msg); }
}public class FullConstructors{ public static void f() throws MyException{
System.out.println("Throwing MyException form f()"); throw new MyException();
} public static void g() throws MyException{
System.out.println("Throwing MyException form g()"); throw new MyException("Originated in g()");
} public static void main(String[] args){ try{
f();
}catch(MyException e){
e.printStackTrace(System.out);
} try{
g();
}catch(MyException e){
e.printStackTrace(System.out);
}
}
}/*Output:
Throwing MyException form f()
MyException
at FullConstructors.f(FullConstructors.java:11)
at FullConstructors.main(FullConstructors.java:19)
Throwing MyException form g()
MyException: Originated in g()
at FullConstructors.g(FullConstructors.java:15)
at FullConstructors.main(FullConstructors.java:24)
*/12.4 printStackTrace()
Throwable类声明了printStackTrace()方法,它将打印“从方法调用处直到异常抛出处”的方法调用序列。printStackTrace()方法所提供的信息可以通过getStackTrace()方法来直接访问,这个方法将返回一个由栈轨迹中的元素所构成的数组,其中每一个元素都表示栈中的一桢。元素0是栈顶元素,并且是调用序列中的最后一个方法调用(这个Throwable被创建和抛出之处)。数组中的最后一个元素和栈底是调用序列中的第一个方法调用。如下:
// WhoCalled.java// Programmatic access to stack trace informationpublic class WhoCalled{ static void f(){ // Generate an exception to fill in the stack trace
try{ throw new Exception();
}catch(Exception e){ for(StackTraceElement ste : e.getStackTrace()){
System.out.println(ste.getMethodName());
}
}
} static void g(){ f(); } static void h(){ g(); } public static void main(String[] args){
f();
System.out.println("-------------------------------");
g();
System.out.println("-------------------------------");
h();
}
}/*Output:
f
main
-------------------------------
f
g
main
-------------------------------
f
g
h
main
*/12.5 为异常先占个位子
可以声明方法将抛出异常,实际上却不抛出。这样做的好处是,为异常先占个位子,以后就可以抛出这种异常而不用修改已有的代码。
在编译时被强制检查的异常称为被检查的异常。
12.6 异常链
常常会想要在捕获一个异常后抛出另一个异常,并且希望把原始异常的信息保存下来,这被称为异常链。JDK1.4以后,所有Throwable的子类在构造器中都可以接受一个cause对象作为参数。这个cause就用来表示原始异常,这样通过把原始异常传递给新的异常,使得即使在当前位置创建并了新的异常,也能通过这个异常链追踪到异常最初发生的位置。
在Throwable的子类中,只有Error(用于Java虚拟机报告系统错误)、Exception以及RuntimeException三种基本的异常提供了带cause参数的构造器。
12.7 Java标准异常
只能在代码中忽略RuntimeException(及其子类)类型的异常,其他类型异常的处理都是由编译器强制实施的。究其原因,RuntimeException代表的是编程错误。
12.8 缺憾:异常丢失
用某些特殊的方式使用finally子句,可能会丢失异常,一种简单的丢失异常的方式是从finally子句中返回。
12.9 finally子句
在异常没有被当前的异常处理程序捕获的情况下,异常处理机制也会在跳到更高一层的异常处理程序之前,执行
finanlly子句。当涉及
break和continue语句的时候,finally子句也会得到执行。finally子句会在执行return语句前执行,即它总是会执行,所以在一个方法中, 可以从多个点返回,并且可以保证重要的清理工作仍旧会执行。
12.10 异常的限制
当要覆盖方法的时候,只能抛出在基类方法的异常说明里列出的那些异常。这个限制很有用,因为这意味着,当基类使用的代码应用到其派生类对象的时候,一样能够工作。
12.11 构造器
如果在构造器内抛出了异常,清理行为也许就不能正常工作了。
12.12 异常匹配
抛出异常的时候,异常处理系统会按照代码的书写顺序抛出“最近”的处理程序。找到匹配的处理程序之后,它就认为异常将得到处理,然后就不再继续查找。
12.13 总结
“报告”功能是异常的精髓所在。Java坚定地强调将所有的错误都以异常形式报告的这一事实,正是它远远超过诸如C++这类语言的长处之一,因为在C++这类语言中,需要以大量不同的方式来报告错误,或者根本就没有提供错误报告功能。
第13章 字符串
13.1 不可变字符串
String对象是不可变的。String类中每个看起来会修改String值的方法,实际上都是创建了一个全新的String对象,以包含修改后的字符串内容。而最初的String对象则丝毫未动。
13.2 重载“+”与 StringBuilder
用于String的“+”与“+=”是Java中仅有的两个重载过的运算符,Java不允许程序员重载任何运算符(但其实Java语言比C++更容易实现运算符的重载)。
String的不可变性带来了一定的效率问题,比如String的“+”运算,每“+”一次都会生成一个新的String对象。Java编译器一般会自动优化,但不同情况下,优化的程度不够。
以下类运行
javap -c Concatenation.class反编译后,可见编译器自动引入了java.lang.StringBuilder类,帮助了优化。
// Concatenation.javapublic class Concatenation{
public static void main(String[] args){
String mango = "mango";
String s = "abc" + mango + "def" + 47;
System.out.println(s);
}
}/**Output:
* abcmangodef47
**/Compiled from "Concatenation.java"public class Concatenation { public Concatenation();
Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code: 0: ldc #2 // String mango
2: astore_1 3: new #3 // class java/lang/StringBuilder
6: dup 7: invokespecial #4 // Method java/lang/StringBuilder."<init>":()V
10: ldc #5 // String abc
12: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
15: aload_1 16: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
19: ldc #7 // String def
21: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
24: bipush 47
26: invokevirtual #8 // Method java/lang/StringBuilder.append:(I)Ljava/lang/StringBuilder;
29: invokevirtual #9 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
32: astore_2 33: getstatic #10 // Field java/lang/System.out:Ljava/io/PrintStream;
36: aload_2 37: invokevirtual #11 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
40: return}但以下情况运行
javap -c WhitherStringBuilder反编译后,显示优化程度不够,方法implicit()显示StringBuilder是在循环之内构造的,这样每经过一次循环就会构造珍上新StringBuilder对象,而explict()只生成一个StringBuilder对象,更优。
// WhitherStringBuilder.javapublic class WhitherStringBuilder{ public String implicit(String[] fields){
String result = ""; for(int i = 0; i < fields.length; i++){
result += fields[i];
} return result;
} public String explicit(String[] fields){
StringBuilder result = new StringBuilder(); for(int i = 0; i < fields.length; i++){
result.append(fields[i]);
} return result.toString();
}
}Compiled from "WhitherStringBuilder.java"public class WhitherStringBuilder { public WhitherStringBuilder();
Code: 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public java.lang.String implicit(java.lang.String[]);
Code: 0: ldc #2 // String
2: astore_2 3: iconst_0 4: istore_3 5: iload_3 6: aload_1 7: arraylength 8: if_icmpge 38
11: new #3 // class java/lang/StringBuilder
14: dup 15: invokespecial #4 // Method java/lang/StringBuilder."<init>":()V
18: aload_2 19: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
22: aload_1 23: iload_3 24: aaload 25: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
28: invokevirtual #6 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
31: astore_2 32: iinc 3, 1
35: goto 5
38: aload_2 39: areturn public java.lang.String explicit(java.lang.String[]);
Code: 0: new #3 // class java/lang/StringBuilder
3: dup 4: invokespecial #4 // Method java/lang/StringBuilder."<init>":()V
7: astore_2 8: iconst_0 9: istore_3 10: iload_3 11: aload_1 12: arraylength 13: if_icmpge 30
16: aload_2 17: aload_1 18: iload_3 19: aaload 20: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
23: pop 24: iinc 3, 1
27: goto 10
30: aload_2 31: invokevirtual #6 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
34: areturn
}13.3 无意识的递归
由String对象后面跟着一个“+”,再后面的对象不是String时,编译器会使后面的对象通过toString()自动类型转换成String,如果这发生在自定义的类的重写的toString()方法体内,就有可能发生无限递归,运行时抛出java.lang.StackOverflowError栈溢出异常。
// InfiniteRecursion.javapublic class InfiniteRecursion{ public String toString(){ //应该调用Object.toString()方法,所以此处应为super.toString()。
return " InfiniteRecursion address: " + this + "\n";
} public static void main(String[] args){
List<InfiniteRecursion> v = new ArrayList<InfiniteRecursion>(); for(int i = 0; i < 10; i++)
v.add(new InfiniteRecursion());
System.out.println(v);
}
}文末:
这些章节内容算是Java的基础,整理出来作为第一部分,算是温故知新吧。
相关文章:
Atas ialah kandungan terperinci Java编程思想学习课时(一):第1~13、16章. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bagaimanakah saya menggunakan Maven atau Gradle untuk Pengurusan Projek Java Lanjutan, Membina Automasi, dan Resolusi Ketergantungan?Mar 17, 2025 pm 05:46 PM
Bagaimanakah saya menggunakan Maven atau Gradle untuk Pengurusan Projek Java Lanjutan, Membina Automasi, dan Resolusi Ketergantungan?Mar 17, 2025 pm 05:46 PMArtikel ini membincangkan menggunakan Maven dan Gradle untuk Pengurusan Projek Java, membina automasi, dan resolusi pergantungan, membandingkan pendekatan dan strategi pengoptimuman mereka.
 Bagaimanakah saya membuat dan menggunakan perpustakaan Java Custom (fail JAR) dengan pengurusan versi dan pergantungan yang betul?Mar 17, 2025 pm 05:45 PM
Bagaimanakah saya membuat dan menggunakan perpustakaan Java Custom (fail JAR) dengan pengurusan versi dan pergantungan yang betul?Mar 17, 2025 pm 05:45 PMArtikel ini membincangkan membuat dan menggunakan perpustakaan Java tersuai (fail balang) dengan pengurusan versi dan pergantungan yang betul, menggunakan alat seperti Maven dan Gradle.
 Bagaimanakah saya melaksanakan caching pelbagai peringkat dalam aplikasi java menggunakan perpustakaan seperti kafein atau cache jambu?Mar 17, 2025 pm 05:44 PM
Bagaimanakah saya melaksanakan caching pelbagai peringkat dalam aplikasi java menggunakan perpustakaan seperti kafein atau cache jambu?Mar 17, 2025 pm 05:44 PMArtikel ini membincangkan pelaksanaan caching pelbagai peringkat di Java menggunakan kafein dan cache jambu untuk meningkatkan prestasi aplikasi. Ia meliputi persediaan, integrasi, dan faedah prestasi, bersama -sama dengan Pengurusan Dasar Konfigurasi dan Pengusiran PRA Terbaik
 Bagaimanakah saya boleh menggunakan JPA (Java Constence API) untuk pemetaan objek-objek dengan ciri-ciri canggih seperti caching dan malas malas?Mar 17, 2025 pm 05:43 PM
Bagaimanakah saya boleh menggunakan JPA (Java Constence API) untuk pemetaan objek-objek dengan ciri-ciri canggih seperti caching dan malas malas?Mar 17, 2025 pm 05:43 PMArtikel ini membincangkan menggunakan JPA untuk pemetaan objek-relasi dengan ciri-ciri canggih seperti caching dan pemuatan malas. Ia meliputi persediaan, pemetaan entiti, dan amalan terbaik untuk mengoptimumkan prestasi sambil menonjolkan potensi perangkap. [159 aksara]
 Bagaimanakah mekanisme kelas muatan Java berfungsi, termasuk kelas yang berbeza dan model delegasi mereka?Mar 17, 2025 pm 05:35 PM
Bagaimanakah mekanisme kelas muatan Java berfungsi, termasuk kelas yang berbeza dan model delegasi mereka?Mar 17, 2025 pm 05:35 PMKelas kelas Java melibatkan pemuatan, menghubungkan, dan memulakan kelas menggunakan sistem hierarki dengan bootstrap, lanjutan, dan pemuat kelas aplikasi. Model delegasi induk memastikan kelas teras dimuatkan dahulu, yang mempengaruhi LOA kelas tersuai


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Dreamweaver CS6
Alat pembangunan web visual

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

ZendStudio 13.5.1 Mac
Persekitaran pembangunan bersepadu PHP yang berkuasa

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

