
Rumah >pangkalan data >tutorial mysql >【MySQL数据库】第四章解读:Schema与数据类型优化(上)
【MySQL数据库】第四章解读:Schema与数据类型优化(上)
- php是最好的语言asal
- 2018-08-07 13:53:421741semak imbas
前言:
高性能的基石:良好的逻辑、物理设计,根据系统要执行的查询语句设计schema
本章关注MySQL数据库设计,介绍mysql数据库设计与其他关系型数据库管理系统的区别
schema:【源】
schema就是数据库对象的集合,这个集合包含了各种对象如:表、视图、存储过程、索引等。为了区分不同的集合,就需要给不同的集合起不同的名字,默认情况下一个用户对应一个集合,用户的schema名等于用户名,并作为该用户缺省schema。所以schema集合看上去像用户名。
如果把database看作是一个仓库,仓库很多房间(schema),一个schema代表一个房间,table可以看作是每个房间中的储物柜,user是每个schema的主人,有操作数据库中每个房间的权利,就是说每个数据库映射的user有每个schema(房间)的钥匙。 SQL server和Oracle mysql有别
4.1选择优化的数据类型
原则:
1、更小的通过更好,尽量使用可正确存储数据的最小的数据类型(占更少的磁盘 内存 CPU缓存,处理时需要CPU周期更少:更快),但能罩得住数据,存不下就尴尬了
2、简单就好:简单类型(更少CPU周期),使用MySQL内建类型存时间,整型存ip,整型较字符代价低(字符集和校对排序规则使字符较复杂)
3、尽量避免null:最好指定为not null
*)null列使用更多的存储空间,mysql里需要特殊处理
*)null使索引、索引统计和值比较更复杂;可为null的列被索引时,每个索引记录需额外的字节
例外:InnoDB使用单独位bit存储null,so对于稀疏数据(很多值为null)有很好的空间效率,不适合MyISAM
4.1.1整数类型【参考】
整数whole number
tinyint(8位存储空间) smallint(16) mediumint(24) int(32) bigint(64)
1、存储值的范围: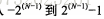
2、unsigned:可选、不容许负值,可使正数的上限提高一倍:tinyint unsigned 0~255,tinyint-128~127
3、有无符号使用相同的存储空间,相同的性能
可为整型指定宽度,例如INT(11),对于大多数应用无意义,不会限制值的合法范围,只是规定了交互工具显示字符的个数,对于存储和计算,int(1)和int(20)是相同的;
实数real number:带小数
float和double,mysql使用duble作为内部浮点计算的类型
decimal:存储精确的小数,mysql服务器自身实现,decimal(18,9)18位,9位小数,9个字节(前4后4点1)
尽量只在对小数进行精确计算时才使用(额外的空间和计算开销),如财务数据
数据量大时,考虑使用bigint代替,将需要存储的货币单位据小数的位数乘以相应的倍数
浮点:
建议:只指定类型、不定精度(mysql),这些精度非标准,mysql会悄选类型、或存时对值取舍
存储同样范围的值时,比decimal更少的空间,float4字节存 double8字节(更高精度范围)
4.1.3字符串类型
varchar和char:
前提:innodb和myisam引擎,最主要的字符串类型
磁盘存储:存储引擎存储的方式与在内存、磁盘上的不能不一样,所以mysql服务器从引擎取值需转格式
varchar:
1、存储可变字符串,比定长节省空间(仅使用必要的空间),但如果表使用row_format=fixed,行会定长存储
2、需使用1/2额外字节记录字符串长度;1)列max长度<=255字节,1字节表示,否2字节,2)采用latinl字符集,varchar(10)列需11个字节的存储空间,varchar(1000)1002字节,2字节存储长度信息
3、节省存储空间,利于性能;但在update可能使行变得比原来更长、需做额外工作
合适的情况:
1)字符串列最大长度比平均长度大很多;2)列的更新少(不担心碎片);3)使用UTF-8字符串,每个字符均使用不同的字节数存储
char:
1、定长,据长度分配空间,删除all末尾空格;长度不够、空格填充
2、存储空间上更有效率,char(1)来存储只有Y N的值 1个字节 ,varchar2字节,还有一个记录长度
适合的情况:
1)适合存储很短的字符串;2)或all值接近同一个长度;3)经常变更的数据,存储不易碎片
对应空格、存储:
char类型存储时末尾空格被删;数据如何存储取决于存储引擎,Memory引擎只支持定长的行(最大长度分配空间)
binary,varbinary:存储二进制字符串,字节码,长度不够、\0来凑(不是空格)检索时不会去
慷慨不是明智的:varchar(5)和varchar(100)存储‘hell’空间开销一样,长的列消耗更多内存
blob和text:大数据
分别用二进制和字符方式存储,分别属于两组不同的数据类型:字符类型:tinytext、smalltext、text、mediumtext、longtext,对应的二进制类型是tinyblob、smallblob、blob、mediumblob、longblob,两类仅有的不同:blob类型存储的是二进制,无排序规则或字符集,text有字符串 排序规则;
MySQL会把每个blob和text当做独立的对象处理,存储引擎存储时会做特殊处理,当值太大,innoDB使用专门的外部存储区域进行存储,此时每个值在行内需要1~4个字节存储一个指针,然后在外部存储实际的值;
mysql对他们的列排序:只对每列前max_sort_length字节排序;且不能将列全部长度的字符串进行索引,也不能使用这些索引消除排序;
如果explain执行计划的extra包含using temporary:这个查询使用了隐式临时表
使用enum代替字符串类型
定义时指定取值范围,对1~255个成员的枚举需要1个字节存储;对于256~65535个成员,需要2个字节存储。最多可以有65535个成员,ENUM类型只能从成员中选择一个;和set相似
可把不重复的固定的字符串存储成一个预定义的集合,mysql在存储枚举时会据列表值的数量压缩到1/2字节中,在内部会将每个值在列表中的位置保存为整数(从1开始,必须进行查找才能转换为字符串,开销、列表小 可控),且在表的.frm文件中保持“数字-字符串”映射关系的“查找表”;
将一个数字存储到一个 ENUM 中,数字被当作为一个索引值,并且存储的值是该索引值所对应的枚举成员: 在一个 ENUM字符串中存储数字是不明智的,因为它可能会打乱思维;ENUM 值依照列规格说明中的列表顺序进行排序。(ENUM 值依照它们的索引号排序。)举例来说,对于 ENUM("a", "b") "a" 排在 "b" 后,但是对于 ENUM("b", "a"), "b" 却排在 "a" 之前。空字符串排在非空字符串前,NULL 值排在其它所有的枚举值前。为了防止意想不到的结果,建议依照字母的顺序定义 ENUM列表。也可以通过使用GROUP BY CONCAT(col) 来确定该以字母顺序排序而不是以索引值。【源】
排序时安装创建表时的顺序排序的(应该是);枚举最不好的地方:字符串列表是固定的,添加删除字符串须使用alter table;在‘查找表’时采用整数主键避免基于字符串的值进行关联;
4.1.4日期和时间
datetime:大范围的值 1001 9999 s YYYYMMDDHHMMSS 与时区无关 8字节
默认,以可排序、无歧义的格式显示datetime:2008-01-02 22:33:44
timestamp:1970 2038,1970 1 1以来的秒数,时区 4字节
from_unixtime将unix时间戳转日期,unix_timestamp将日期转unix时间戳
插入时没有指定第一个timestamp列的值,设置为当前时间,插入记录时,默认更新第一个timestamp列的值,timestamp类为not null,尽量使用timestamp(空间效率高);
可以使用bigint类型存储微妙级别的时间戳,或double存秒之后的小数部分,或使用MariaDB代替MySQL;
4.1.5 位
bit:mysql5.0
前与tinyint同义词,新特性
bit(1)单个位的字段,bit(2)2个位,最大长度64个位
行为因存储引擎而异,MyISAM打包存储all的BIT列(17个单独的bit列只需要17个位存储,myisam3字节ok),其他引擎Memory和innoDB为每bit列使用足够存储的最小整数类型来存放,不节省存储空间;
mysql把bit当做字符串类型,检索bit(1)值、结果是包含二进制0/1的字符串,数字上下文的场景检索,将字符串转成数字,大部分应用,best避免使用;

set
创建表时,就指定SET类型的取值范围 :属性名 SET('值1','值2','值3'...,'值n'),“值n”参数表示列表中的第n个值,这些值末尾的空格将会被系统直接删除,字段元素顺序 系统自动按照定义时的顺序显示 重复 只存一次。
其基本形式与ENUM类型一样。SET类型的值可以取列表中的一个元素或者多个元素的组合。取多个元素时,不同元素之间用逗号隔开。SET类型的值最多只能是有64个元素构成的组合,根据成员的不同,存储上也有所不同:【参考,同enum】
1~8成员的集合,占1个字节。 9~16成员的集合,占2个字节。 17~24成员的集合,占3个字节。 25~32成员的集合,占4个字节。 33~64成员的集合,占8个字节。
需要保持很多true、false值,可考虑合并这些列到set类型,在mysql内部以一系列打包的位的集合来表示的(有效利用存储空间)且mysql有find_in_set、field函数,方便在查询中使用;
缺点:改变列的定义代价高,需要alter table,无法再set上通索引查找
在整数列按位操作:
代替set的方式:使用整数包装一系列的位:可把8个位包装到tinyint中,且按位操作来使用,为位定义名称常量来简化这个工作,但是这样查询语句较难写且难理解
4.1.6选择标识符identifier
标识列:自增长列【源】
1)可不用手动插入值,系统提供默认序列值;2)不要求和主键搭配 ; 3)要求是unique key;
4)一个表最多一个;5)类型只能是数值;5)可通过set auto_increment_increment=3;
选择标识列类型时
考虑存储类型、mysql对这种类型怎么执行计算和比较,确定后确保在all关联表中使用same类型,类型间要精确匹配;
技巧:
1、整数类型:整数通常最好的选择,很快且可使用auto_increment
2、enum和set类型,存储固定信息
3、字符串:避免,耗空间较数字慢,myisam表特别小心(默认对字符串压缩使用、查询慢)
1)完全“随机”字符串MD5/SHA1/UUID函数生成的新值 会任意分布在很大的空间内,导致insert及部分的select变慢:插入值随机的写到索引的不同位置,insert变慢(页分裂 磁盘随机访问 聚簇索引碎片);select变慢、逻辑上相邻的行分布在磁盘和内存不同的地方;随机值导致缓存对all类型的查询语句效果都变差(使缓存赖以工作的访问局部性原理失效)
聚簇索引,实际存储的循序结构与数据存储的物理结构一致,通常来说物理顺序结构只有一种,一个表的聚簇索引也只能有一个,通常默认都是主键,设置了主键,系统默认就为你加上了聚簇索引;【源】
非聚簇索引记录的物理顺序与逻辑顺序没有必然的联系,与数据的存储物理结构没有关系;一个表对应的非聚簇索引可以有多条,根据不同列的约束可以建立不同要求的非聚簇索引;
2)存储uuid,移除-符号,或者用unhex转换uuid值为16字节的数字,且存储在binary(16)列中,检索时通过hex函数格式化为16进制格式;
UUID生成的值与加密散列函数(sha1)生成的值不同特征:uuid分布不均匀,有一定顺序,不如递增整数
当心自动生成的schema:
严重性能问题,很大的varchar、关联列不同的类型;
orm会存储任意类型的数据到任意类型的后端数据存储中,并没有设计使用更优的类型存储,有时为每个对象每个属性使用单独行,设置使用基于时间戳的版本控制,导致单个属性会有多个版本存在;权衡
4.1.7特殊类型数据:空
相关文章:
Atas ialah kandungan terperinci 【MySQL数据库】第四章解读:Schema与数据类型优化(上). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!