

这篇文章主要介绍了JavaScript模块的用法以及语法基础,需要的朋友参考学习下吧。
本文是关于JavaScript模块的基础讲解内容,对每个模块进行了分析和代码用法的讲解,以下是全部内容:
JavaScript的模块介绍
模块通常是指编程语言所提供的代码组织机制,利用此机制可将程序拆解为独立且通用的代码单元。所谓模块化主要是解决代码分割、作用域隔离、模块之间的依赖管理以及发布到生产环境时的自动化打包与处理等多个方面。
模块的优点 可维护性。 因为模块是独立的,一个设计良好的模块会让外面的代码对自己的依赖越少越好,这样自己就可以独立去更新和改进。 命名空间。 在 JavaScript 里面,如果一个变量在最顶级的函数之外声明,它就直接变成全局可用。因此,常常不小心出现命名冲突的情况。使用模块化开发来封装变量,可以避免污染全局环境。 重用代码。 我们有时候会喜欢从之前写过的项目中拷贝代码到新的项目,这没有问题,但是更好的方法是,通过模块引用的方式,来避免重复的代码库。 CommonJS
CommonJS 最开始是 Mozilla 的工程师于 2009 年开始的一个项目,它的目的是让浏览器之外的 JavaScript (比如服务器端或者桌面端)能够通过模块化的方式来开发和协作。
在 CommonJS 的规范中,每个 JavaScript 文件就是一个独立的模块上下文(module context),在这个上下文中默认创建的属性都是私有的。也就是说,在一个文件定义的变量(还包括函数和类),都是私有的,对其他文件是不可见的。
需要注意的是,CommonJS 规范的主要适用场景是服务器端编程,所以采用同步加载模块的策略。如果我们依赖3个模块,代码会一个一个依次加载它们。
该模块实现方案主要包含 require 与 module 这两个关键字,其允许某个模块对外暴露部分接口并且由其他模块导入使用。
//sayModule.js
function SayModule () {
this.hello = function () {
console.log('hello');
};
this.goodbye = function () {
console.log('goodbye');
};
}
module.exports = SayModule;
//main.js 引入sayModule.js
var Say = require('./sayModule.js');
var sayer = new Say();
sayer.hello(); //hello作为一个服务器端的解决方案,CommonJS 需要一个兼容的脚本加载器作为前提条件。该脚本加载器必须支持名为 require 和 module.exports 的函数,它们将模块相互导入导出。
Node.js
Node 从 CommonJS 的一些创意中,创造出自己的模块化实现。由于Node 在服务端的流行,Node 的模块形式被(不正确地)称为 CommonJS。
Node.js模块可以分为两大类,一类是核心模块,另一类是文件模块。
核心模块 就是Node.js标准的API中提供的模块,如fs、http、net等,这些都是由Node.js官方提供的模块,编译成了二进制代码,可以直接通过require获取核心模块,例如require('fs'),核心模块拥有最高的加载优先级,如果有模块与核心模块命名冲突,Node.js总是会加载核心模块。
文件模块 是存储为单独的文件(或文件夹)的模块,可能是JavaScript代码、JSON或编译好的C/C++代码。在不显式指定文件模块扩展名的时候,Node.js会分别试图加上.js、.json、.node(编译好的C/C++代码)。
加载方式
按路径加载模块
如果require参数一"/"开头,那么就以绝对路径的方式查找模块名称,如果参数一"./"、"../"开头,那么则是以相对路径的方式来查找模块。
通过查找node_modules目录加载模块
如果require参数不以"/"、"./"、"../"开头,而该模块又不是核心模块,那么就要通过查找node_modules加载模块了。我们使用的npm获取的包通常就是以这种方式加载的。
加载缓存
Node.js模块不会被重复加载,这是因为Node.js通过文件名缓存所有加载过的文件模块,所以以后再访问到时就不会重新加载了。
注意: Node.js是根据实际文件名缓存的,而不是require()提供的参数缓存的,也就是说即使你分别通过require('express')和require('./node_modules/express')加载两次,也不会重复加载,因为尽管两次参数不同,解析到的文件却是同一个。
Node.js 中的模块在加载之后是以单例化运行,并且遵循值传递原则:如果是一个对象,就相当于这个对象的引用。
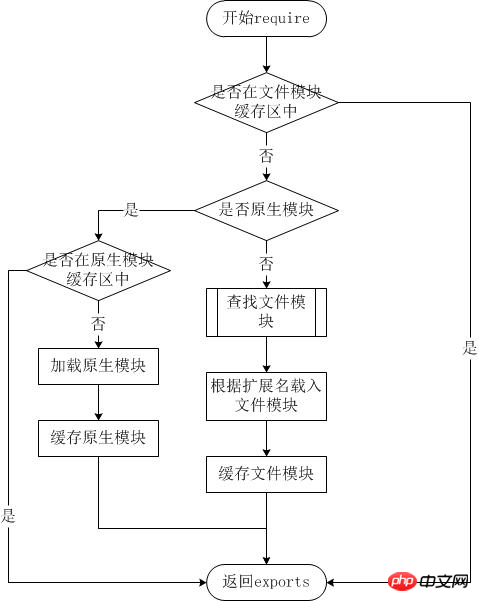
模块载入过程
加载文件模块的工作,主要由原生模块module来实现和完成,该原生模块在启动时已经被加载,进程直接调用到runMain静态方法。
例如运行: node app.js
Module.runMain = function () {
// Load the main module--the command line argument.
Module._load(process.argv[1], null, true);
};
//_load静态方法在分析文件名之后执行
var module = new Module(id, parent);
//并根据文件路径缓存当前模块对象,该模块实例对象则根据文件名加载。
module.load(filename); 具体说一下上文提到了文件模块的三类模块,这三类文件模块以后缀来区分,Node.js会根据后缀名来决定加载方法,具体的加载方法在下文require.extensions中会介绍。
.js 通过fs模块同步读取js文件并编译执行。 .node 通过C/C++进行编写的Addon。通过dlopen方法进行加载。 .json 读取文件,调用JSON.parse解析加载。
接下来详细描述js后缀的编译过程。Node.js在编译js文件的过程中实际完成的步骤有对js文件内容进行头尾包装。以app.js为例,包装之后的app.js将会变成以下形式:
//circle.js
var PI = Math.PI;
exports.area = function (r) {
return PI * r * r;
};
exports.circumference = function (r) {
return 2 * PI * r;
};
//app.js
var circle = require('./circle.js');
console.log( 'The area of a circle of radius 4 is ' + circle.area(4));
//app包装后
(function (exports, require, module, __filename, __dirname) {
var circle = require('./circle.js');
console.log('The area of a circle of radius 4 is ' + circle.area(4));
});
//这段代码会通过vm原生模块的runInThisContext方法执行(类似eval,只是具有明确上下文,不污染全局),返回为一个具体的function对象。最后传入module对象的exports,require方法,module,文件名,目录名作为实参并执行。 这就是为什么require并没有定义在app.js 文件中,但是这个方法却存在的原因。从Node.js的API文档中可以看到还有__filename、__dirname、module、exports几个没有定义但是却存在的变量。其中__filename和__dirname在查找文件路径的过程中分析得到后传入的。module变量是这个模块对象自身,exports是在module的构造函数中初始化的一个空对象({},而不是null)。
在这个主文件中,可以通过require方法去引入其余的模块。而其实这个require方法实际调用的就是load方法。
load方法在载入、编译、缓存了module后,返回module的exports对象。这就是circle.js文件中只有定义在exports对象上的方法才能被外部调用的原因。
以上所描述的模块载入机制均定义在lib/module.js中。
require 函数
require 引入的对象主要是函数。当 Node 调用 require() 函数,并且传递一个文件路径给它的时候,Node 会经历如下几个步骤:
Resolving:找到文件的绝对路径; Loading:判断文件内容类型; Wrapping:打包,给这个文件赋予一个私有作用范围。这是使 require 和 module 模块在本地引用的一种方法; Evaluating:VM 对加载的代码进行处理的地方; Caching:当再次需要用这个文件的时候,不需要重复一遍上面步骤。
require.extensions 来查看对三种文件的支持情况
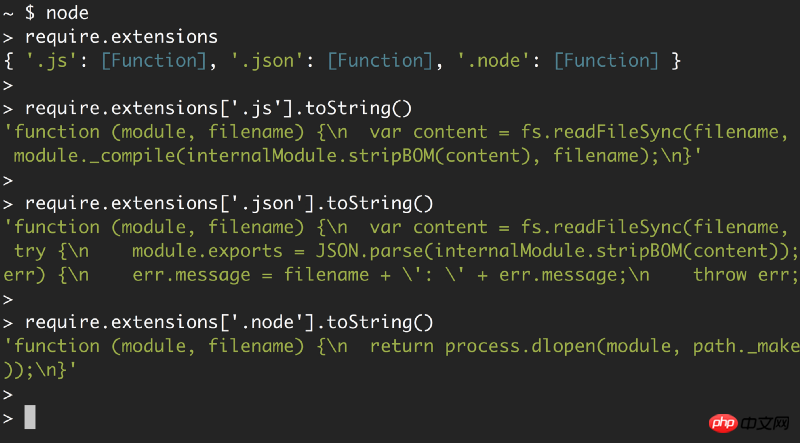
可以清晰地看到 Node 对每种扩展名所使用的函数及其操作:对 .js 文件使用 module._compile;对 .json 文件使用 JSON.parse;对 .node 文件使用 process.dlopen。
文件查找策略
从文件模块缓存中加载
尽管原生模块与文件模块的优先级不同,但是优先级最高的是从文件模块的缓存中加载已经存在的模块。
从原生模块加载
原生模块的优先级仅次于文件模块缓存的优先级。require方法在解析文件名之后,优先检查模块是否在原生模块列表中。以http模块为例,尽管在目录下存在一个http、http.js、http.node、http.json文件,require(“http”)都不会从这些文件中加载,而是从原生模块中加载。
原生模块也有一个缓存区,同样也是优先从缓存区加载。如果缓存区没有被加载过,则调用原生模块的加载方式进行加载和执行。
从文件加载
当文件模块缓存中不存在,而且不是原生模块的时候,Node.js会解析require方法传入的参数,并从文件系统中加载实际的文件,加载过程中的包装和编译细节在前面说过是调用module._load方法。
··
当 Node 遇到 require(X) 时,按下面的顺序处理。
(1)如果 X 是内置模块(比如 require('http'))
a. 返回该模块。
b. 不再继续执行。
(2)如果 X 以 "./" 或者 "/" 或者 "../" 开头
a. 根据 X 所在的父模块,确定 X 的绝对路径。
b. 将 X 当成文件,依次查找下面文件,只要其中有一个存在,就返回该文件,不再继续执行。
X
X.js
X.json
X.node
c. 将 X 当成目录,依次查找下面文件,只要其中有一个存在,就返回该文件,不再继续执行。
X/package.json(main字段)
X/index.js
X/index.json
X/index.node
(3)如果 X 不带路径
a. 根据 X 所在的父模块,确定 X 可能的安装目录。
b. 依次在每个目录中,将 X 当成文件名或目录名加载。
(4) 抛出 "not found"
模块循环依赖
//创建两个文件,module1.js 和 module2.js,并且让它们相互引用 // module1.js exports.a = 1; require('./module2'); exports.b = 2; exports.c = 3; // module2.js const Module1 = require('./module1'); console.log('Module1 is partially loaded here', Module1);
在 module1 完全加载之前需要先加载 module2,而 module2 的加载又需要 module1。这种状态下,我们从 exports 对象中能得到的就是在发生循环依赖之前的这部分。上面代码中,只有 a 属性被引入,因为 b 和 c 都需要在引入 module2 之后才能加载进来。
Node 使这个问题简单化,在一个模块加载期间开始创建 exports 对象。如果它需要引入其他模块,并且有循环依赖,那么只能部分引入,也就是只能引入发生循环依赖之前所定义的这部分。
AMD
AMD 是 Asynchronous Module Definition 的简称,即“异步模块定义”,是从 CommonJS 讨论中诞生的。AMD 优先照顾浏览器的模块加载场景,使用了异步加载和回调的方式。
AMD 和 CommonJS 一样需要脚本加载器,尽管 AMD 只需要对 define 方法的支持。define 方法需要三个参数:模块名称,模块运行的依赖数组,所有依赖都可用之后执行的函数(该函数按照依赖声明的顺序,接收依赖作为参数)。只有函数参数是必须的。define 既是一种引用模块的方式,也是定义模块的方式。
// file lib/sayModule.js
define(function (){
return {
sayHello: function () {
console.log('hello');
}
};
});
//file main.js
define(['./lib/sayModule'], function (say){
say.sayHello(); //hello
})main.js 作为整个应用的入口模块,我们使用 define 关键字声明了该模块以及外部依赖(没有生命模块名称);当我们执行该模块代码时,也就是执行 define 函数的第二个参数中定义的函数功能,其会在框架将所有的其他依赖模块加载完毕后被执行。这种延迟代码执行的技术也就保证了依赖的并发加载。
RequireJS
RequireJS 是一个前端的模块化管理的工具库,遵循AMD规范,通过一个函数来将所有所需要的或者说所依赖的模块实现装载进来,然后返回一个新的函数(模块),我们所有的关于新模块的业务代码都在这个函数内部操作,其内部也可无限制的使用已经加载进来的以来的模块。
<script data-main='scripts/main' src='scripts/require.js'></script> //scripts下的main.js则是指定的主代码脚本文件,所有的依赖模块代码文件都将从该文件开始异步加载进入执行。
defined用于定义模块,RequireJS要求每个模块均放在独立的文件之中。按照是否有依赖其他模块的情况分为独立模块和非独立模块。
1、独立模块 不依赖其他模块。直接定义
define({
methodOne: function (){},
methodTwo: function (){}
});
//等价于
define(function (){
return {
methodOne: function (){},
methodTwo: function (){}
};
});2、非独立模块,对其他模块有依赖
define([ 'moduleOne', 'moduleTwo' ], function(mOne, mTwo){
...
});
//或者
define( function( require ){
var mOne = require( 'moduleOne' ),
mTwo = require( 'moduleTwo' );
...
});如上代码, define中有依赖模块数组的 和 没有依赖模块数组用require加载 这两种定义模块,调用模块的方法合称为AMD模式,定义模块清晰,不会污染全局变量,清楚的显示依赖关系。AMD模式可以用于浏览器环境并且允许非同步加载模块,也可以按需动态加载模块。
CMD
CMD(Common Module Definition),在CMD中,一个模块就是一个文件。
全局函数define,用来定义模块。
参数 factory 可以是一个函数,也可以为对象或者字符串。
当 factory 为对象、字符串时,表示模块的接口就是该对象、字符串。
定义JSON数据模块:
define({ "foo": "bar" });factory 为函数的时候,表示模块的构造方法,执行构造方法便可以得到模块向外提供的接口。
define( function(require, exports, module) {
// 模块代码
});SeaJS
sea.js 核心特征:
遵循CMD规范,与NodeJS般的书写模块代码。依赖自动加载,配置清晰简洁。
seajs.use用来在页面中加载一个或者多个模块
// 加载一个模块
seajs.use('./a');
// 加载模块,加载完成时执行回调
seajs.use('./a',function(a){
a.doSomething();
});
// 加载多个模块执行回调
seajs.use(['./a','./b'],function(a , b){
a.doSomething();
b.doSomething();
});AMD和CMD最大的区别是对依赖模块的执行时机处理不同,注意不是加载的时机或者方式不同。
很多人说requireJS是异步加载模块,SeaJS是同步加载模块,这么理解实际上是不准确的,其实加载模块都是异步的,只不过AMD依赖前置,js可以方便知道依赖模块是谁,立即加载,而CMD就近依赖,需要使用把模块变为字符串解析一遍才知道依赖了那些模块,这也是很多人诟病CMD的一点,牺牲性能来带来开发的便利性,实际上解析模块用的时间短到可以忽略。
为什么说是执行时机处理不同?
同样都是异步加载模块,AMD在加载模块完成后就会执行该模块,所有模块都加载执行完后会进入回调函数,执行主逻辑,这样的效果就是依赖模块的执行顺序和书写顺序不一定一致,看网络速度,哪个先下载下来,哪个先执行,但是主逻辑一定在所有依赖加载完成后才执行。
CMD加载完某个依赖模块后并不执行,只是下载而已,在所有依赖模块加载完成后进入主逻辑,遇到require语句的时候才执行对应的模块,这样模块的执行顺序和书写顺序是完全一致的。
UMD
统一模块定义(UMD:Universal Module Definition )就是将 AMD 和 CommonJS 合在一起的一种尝试,常见的做法是将CommonJS 语法包裹在兼容 AMD 的代码中。
(function(define) {
define(function () {
return {
sayHello: function () {
console.log('hello');
}
};
});
}(
typeof module === 'object' && module.exports && typeof define !== 'function' ?
function (factory) { module.exports = factory(); } :
define
));该模式的核心思想在于所谓的 IIFE(Immediately Invoked Function Expression),该函数会根据环境来判断需要的参数类别
ES6模块(module) 严格模式
ES6 的模块自动采用严格模式,不管有没有在模块头部加上"use strict";。
严格模式主要有以下限制。
变量必须声明后再使用函数的参数不能有同名属性,否则报错不能使用with语句不能对只读属性赋值,否则报错不能使用前缀0表示八进制数,否则报错不能删除不可删除的属性,否则报错不能删除变量delete prop,会报错,只能删除属性delete global[prop] eval不会在它的外层作用域引入变量 eval和arguments不能被重新赋值 arguments不会自动反映函数参数的变化不能使用arguments.callee 不能使用arguments.caller 禁止this指向全局对象不能使用fn.caller和fn.arguments获取函数调用的堆栈增加了保留字(比如protected、static和interface) 模块Module
一个模块,就是一个对其他模块暴露自己的属性或者方法的文件。
导出Export
作为一个模块,它可以选择性地给其他模块暴露(提供)自己的属性和方法,供其他模块使用。
// profile.js
export var firstName = 'qiqi';
export var lastName = 'haobenben';
export var year = 1992;
//等价于
var firstName = 'qiqi';
var lastName = 'haobenben';
var year = 1992;
export {firstName, lastName, year}1、 通常情况下,export输出的变量就是本来的名字,但是可以使用as关键字重命名。
function v1() { ... }
function v2() { ... }
export {
v1 as streamV1,
v2 as streamV2,
v2 as streamLatestVersion
};
//上面代码使用as关键字,重命名了函数v1和v2的对外接口。重命名后,v2可以用不同的名字输出两次。2、 需要特别注意的是,export命令规定的是对外的接口,必须与模块内部的变量建立一一对应关系。
// 报错
export 1;
// 报错
var m = 1;
export m;
//上面两种写法都会报错,因为没有提供对外的接口。第一种写法直接输出1,第二种写法通过变量m,还是直接输出1。1只是一个值,不是接口。
/ 写法一
export var m = 1;
// 写法二
var m = 1;
export {m};
// 写法三
var n = 1;
export {n as m};
//上面三种写法都是正确的,规定了对外的接口m。其他脚本可以通过这个接口,取到值1。它们的实质是,在接口名与模块内部变量之间,建立了一一对应的关系。3、最后,export命令可以出现在模块的任何位置,只要处于模块顶层就可以。如果处于块级作用域内,就会报错,接下来说的import命令也是如此。
function foo() {
export default 'bar' // SyntaxError
}
foo()导入import
作为一个模块,可以根据需要,引入其他模块的提供的属性或者方法,供自己模块使用。
1、 import命令接受一对大括号,里面指定要从其他模块导入的变量名。大括号里面的变量名,必须与被导入模块(profile.js)对外接口的名称相同。如果想为输入的变量重新取一个名字,import命令要使用as关键字,将输入的变量重命名。
import { lastName as surename } from './profile';3、注意,import命令具有提升效果,会提升到整个模块的头部,首先执行。
2、import后面的from指定模块文件的位置,可以是相对路径,也可以是绝对路径,.js路径可以省略。如果只是模块名,不带有路径,那么必须有配置文件,告诉 JavaScript 引擎该模块的位置。
foo();
import { foo } from 'my_module';
//上面的代码不会报错,因为import的执行早于foo的调用。这种行为的本质是,import命令是编译阶段执行的,在代码运行之前。4、由于import是静态执行,所以不能使用表达式和变量,这些只有在运行时才能得到结果的语法结构。
/ 报错
import { 'f' + 'oo' } from 'my_module';
// 报错
let module = 'my_module';
import { foo } from module;
// 报错
if (x === 1) {
import { foo } from 'module1';
} else {
import { foo } from 'module2';
}5、最后,import语句会执行所加载的模块,因此可以有下面的写法。
import 'lodash'; //上面代码仅仅执行lodash模块,但是不输入任何值。
默认导出(export default)
每个模块支持我们导出一个没有名字的变量,使用关键语句export default来实现.
export default function(){
console.log("I am default Fn");
}
//使用export default关键字对外导出一个匿名函数,导入这个模块的时候,可以为这个匿名函数取任意的名字
//取任意名字均可
import sayDefault from "./module-B.js";
sayDefault();
//结果:I am default Fn1、默认输出和正常输出的比较
// 第一组
export default function diff() { // 输出
// ...
}
import diff from 'diff'; // 输入
// 第二组
export function diff() { // 输出
// ...
};
import {diff} from 'diff'; // 输入
//上面代码的两组写法,第一组是使用export default时,对应的import语句不需要使用大括号;第二组是不使用export default时,对应的import语句需要使用大括号。export default命令用于指定模块的默认输出。显然,一个模块只能有一个默认输出,因此export default命令只能使用一次。所以,import命令后面才不用加大括号,因为只可能对应一个方法。
2、因为export default本质是将该命令后面的值,赋给default变量以后再默认,所以直接将一个值写在export default之后。
/ 正确 export default 42; // 报错 export 42; //上面代码中,后一句报错是因为没有指定对外的接口,而前一句指定外对接口为default。
3、如果想在一条import语句中,同时输入默认方法和其他变量,可以写成下面这样。
import _, { each } from 'lodash';
//对应上面代码的export语句如下
export default function (){
//...
}
export function each (obj, iterator, context){
//...
}export 与 import 的复合写法
如果在一个模块之中,先输入后输出同一个模块,import语句可以与export语句写在一起。
export { foo, bar } from 'my_module';
// 等同于
import { foo, bar } from 'my_module';
export { foo, bar };
/ 接口改名
export { foo as myFoo } from 'my_module';
// 整体输出
export * from 'my_module';注意事项
1、声明的变量,对外都是只读的。但是导出的是对象类型的值,就可修改。
2、导入不存在的变量,值为undefined。
ES6 中的循环引用
ES6 中,imports 是 exprts 的只读视图,直白一点就是,imports 都指向 exports 原本的数据,比如:
//------ lib.js ------
export let counter = 3;
export function incCounter() {
counter++;
}
//------ main.js ------
import { counter, incCounter } from './lib';
// The imported value `counter` is live
console.log(counter); // 3
incCounter();
console.log(counter); // 4
// The imported value can't be changed
counter++; // TypeError因此在 ES6 中处理循环引用特别简单,看下面这段代码:
//------ a.js ------
import {bar} from 'b'; // (1)
export function foo() {
bar(); // (2)
}
//------ b.js ------
import {foo} from 'a'; // (3)
export function bar() {
if (Math.random()) {
foo(); // (4)
}
}假设先加载模块 a,在模块 a 加载完成之后,bar 间接性地指向的是模块 b 中的 bar。无论是加载完成的 imports 还是未完成的 imports,imports 和 exports 之间都有一个间接的联系,所以总是可以正常工作。
实例
//---module-B.js文件---
//导出变量:name
export var name = "cfangxu";
moduleA模块代码:
//导入 模块B的属性 name
import { name } from "./module-B.js";
console.log(name)
//打印结果:cfangxu批量导出
//属性name
var name = "cfangxu";
//属性age
var age = 26;
//方法 say
var say = function(){
console.log("say hello");
}
//批量导出
export {name,age,say}批量导入
//导入 模块B的属性
import { name,age,say } from "./module-B.js";
console.log(name)
//打印结果:cfangxu
console.log(age)
//打印结果:26
say()
//打印结果:say hello重命名导入变量
import {name as myName} from './module-B.js';
console.log(myName) //cfangxu整体导入
/使用*实现整体导入 import * as obj from "./module-B.js"; console.log(obj.name) //结果:"cfangxu" console.log(obj.age) //结果:26 obj.say(); //结果:say hello
上面是我整理给大家的,希望今后会对大家有帮助。
相关文章:
Atas ialah kandungan terperinci 详细解读分析JavaScript代码模块. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Memahami Enjin JavaScript: Butiran PelaksanaanApr 17, 2025 am 12:05 AM
Memahami Enjin JavaScript: Butiran PelaksanaanApr 17, 2025 am 12:05 AMMemahami bagaimana enjin JavaScript berfungsi secara dalaman adalah penting kepada pemaju kerana ia membantu menulis kod yang lebih cekap dan memahami kesesakan prestasi dan strategi pengoptimuman. 1) aliran kerja enjin termasuk tiga peringkat: parsing, penyusun dan pelaksanaan; 2) Semasa proses pelaksanaan, enjin akan melakukan pengoptimuman dinamik, seperti cache dalam talian dan kelas tersembunyi; 3) Amalan terbaik termasuk mengelakkan pembolehubah global, mengoptimumkan gelung, menggunakan const dan membiarkan, dan mengelakkan penggunaan penutupan yang berlebihan.
 Python vs JavaScript: Keluk Pembelajaran dan Kemudahan PenggunaanApr 16, 2025 am 12:12 AM
Python vs JavaScript: Keluk Pembelajaran dan Kemudahan PenggunaanApr 16, 2025 am 12:12 AMPython lebih sesuai untuk pemula, dengan lengkung pembelajaran yang lancar dan sintaks ringkas; JavaScript sesuai untuk pembangunan front-end, dengan lengkung pembelajaran yang curam dan sintaks yang fleksibel. 1. Sintaks Python adalah intuitif dan sesuai untuk sains data dan pembangunan back-end. 2. JavaScript adalah fleksibel dan digunakan secara meluas dalam pengaturcaraan depan dan pelayan.
 Python vs JavaScript: Komuniti, Perpustakaan, dan SumberApr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan SumberApr 15, 2025 am 12:16 AMPython dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Dari C/C ke JavaScript: Bagaimana semuanya berfungsiApr 14, 2025 am 12:05 AM
Dari C/C ke JavaScript: Bagaimana semuanya berfungsiApr 14, 2025 am 12:05 AMPeralihan dari C/C ke JavaScript memerlukan menyesuaikan diri dengan menaip dinamik, pengumpulan sampah dan pengaturcaraan asynchronous. 1) C/C adalah bahasa yang ditaip secara statik yang memerlukan pengurusan memori manual, manakala JavaScript ditaip secara dinamik dan pengumpulan sampah diproses secara automatik. 2) C/C perlu dikumpulkan ke dalam kod mesin, manakala JavaScript adalah bahasa yang ditafsirkan. 3) JavaScript memperkenalkan konsep seperti penutupan, rantaian prototaip dan janji, yang meningkatkan keupayaan pengaturcaraan fleksibiliti dan asynchronous.
 Enjin JavaScript: Membandingkan PelaksanaanApr 13, 2025 am 12:05 AM
Enjin JavaScript: Membandingkan PelaksanaanApr 13, 2025 am 12:05 AMEnjin JavaScript yang berbeza mempunyai kesan yang berbeza apabila menguraikan dan melaksanakan kod JavaScript, kerana prinsip pelaksanaan dan strategi pengoptimuman setiap enjin berbeza. 1. Analisis leksikal: Menukar kod sumber ke dalam unit leksikal. 2. Analisis Tatabahasa: Menjana pokok sintaks abstrak. 3. Pengoptimuman dan Penyusunan: Menjana kod mesin melalui pengkompil JIT. 4. Jalankan: Jalankan kod mesin. Enjin V8 mengoptimumkan melalui kompilasi segera dan kelas tersembunyi, Spidermonkey menggunakan sistem kesimpulan jenis, menghasilkan prestasi prestasi yang berbeza pada kod yang sama.
 Beyond the Browser: JavaScript di dunia nyataApr 12, 2025 am 12:06 AM
Beyond the Browser: JavaScript di dunia nyataApr 12, 2025 am 12:06 AMAplikasi JavaScript di dunia nyata termasuk pengaturcaraan sisi pelayan, pembangunan aplikasi mudah alih dan Internet of Things Control: 1. Pengaturcaraan sisi pelayan direalisasikan melalui node.js, sesuai untuk pemprosesan permintaan serentak yang tinggi. 2. Pembangunan aplikasi mudah alih dijalankan melalui reaktnatif dan menyokong penggunaan silang platform. 3. Digunakan untuk kawalan peranti IoT melalui Perpustakaan Johnny-Five, sesuai untuk interaksi perkakasan.
 Membina aplikasi SaaS Multi-penyewa dengan Next.js (Integrasi Backend)Apr 11, 2025 am 08:23 AM
Membina aplikasi SaaS Multi-penyewa dengan Next.js (Integrasi Backend)Apr 11, 2025 am 08:23 AMSaya membina aplikasi SaaS multi-penyewa berfungsi (aplikasi edTech) dengan alat teknologi harian anda dan anda boleh melakukan perkara yang sama. Pertama, apakah aplikasi SaaS multi-penyewa? Aplikasi SaaS Multi-penyewa membolehkan anda melayani beberapa pelanggan dari Sing
 Cara Membina Aplikasi SaaS Multi-Tenant dengan Next.js (Integrasi Frontend)Apr 11, 2025 am 08:22 AM
Cara Membina Aplikasi SaaS Multi-Tenant dengan Next.js (Integrasi Frontend)Apr 11, 2025 am 08:22 AMArtikel ini menunjukkan integrasi frontend dengan backend yang dijamin oleh permit, membina aplikasi edtech SaaS yang berfungsi menggunakan Next.Js. Frontend mengambil kebenaran pengguna untuk mengawal penglihatan UI dan memastikan permintaan API mematuhi dasar peranan


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver Mac版
Alat pembangunan web visual

