



这篇文章主要介绍了关于Redis面试题及分布式集群,有着一定的参考价值,现在分享给大家,有需要的朋友可以参考一下

1. 使用Redis有哪些好处?
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
专题推荐:2020年redis面试题大全(最新)
2. redis相比memcached有哪些优势?
(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型
(2) redis的速度比memcached快很多
(3) redis可以持久化其数据
3. redis常见性能问题和解决方案:
(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件
(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次
(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内
(4) 尽量避免在压力很大的主库上增加从库
(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3…
这样的结构方便解决单点故障问题,实现Slave对Master的替换。如果Master挂了,可以立刻启用Slave1做Master,其他不变。
4. MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据
相关知识:redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略:
voltile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
5. Memcache与Redis的区别都有哪些?
1)、存储方式
Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。
Redis有部份存在硬盘上,这样能保证数据的持久性。
2)、数据支持类型
Memcache对数据类型支持相对简单。
Redis有复杂的数据类型。
3)、使用底层模型不同
它们之间底层实现方式 以及与客户端之间通信的应用协议不一样。
Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
4),value大小
redis最大可以达到1GB,而memcache只有1MB
6. Redis 常见的性能问题都有哪些?如何解决?
1).Master写内存快照,save命令调度rdbSave函数,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以Master最好不要写内存快照。
2).Master AOF持久化,如果不重写AOF文件,这个持久化方式对性能的影响是最小的,但是AOF文件会不断增大,AOF文件过大会影响Master重启的恢复速度。Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化,如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
3).Master调用BGREWRITEAOF重写AOF文件,AOF在重写的时候会占大量的CPU和内存资源,导致服务load过高,出现短暂服务暂停现象。
4). Redis主从复制的性能问题,为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内
7, redis 最适合的场景
Redis最适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就会有疑问,似乎Redis更像一个加强版的Memcached,那么何时使用Memcached,何时使用Redis呢?
如果简单地比较Redis与Memcached的区别,大多数都会得到以下观点:
1 、Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
2 、Redis支持数据的备份,即master-slave模式的数据备份。
3 、Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
(1)、会话缓存(Session Cache)
最常用的一种使用Redis的情景是会话缓存(session cache)。用Redis缓存会话比其他存储(如Memcached)的优势在于:Redis提供持久化。当维护一个不是严格要求一致性的缓存时,如果用户的购物车信息全部丢失,大部分人都会不高兴的,现在,他们还会这样吗?
幸运的是,随着 Redis 这些年的改进,很容易找到怎么恰当的使用Redis来缓存会话的文档。甚至广为人知的商业平台Magento也提供Redis的插件。
(2)、全页缓存(FPC)
除基本的会话token之外,Redis还提供很简便的FPC平台。回到一致性问题,即使重启了Redis实例,因为有磁盘的持久化,用户也不会看到页面加载速度的下降,这是一个极大改进,类似PHP本地FPC。
再次以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。
此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
(3)、队列
Reids在内存存储引擎领域的一大优点是提供 list 和 set 操作,这使得Redis能作为一个很好的消息队列平台来使用。Redis作为队列使用的操作,就类似于本地程序语言(如Python)对 list 的 push/pop 操作。
如果你快速的在Google中搜索“Redis queues”,你马上就能找到大量的开源项目,这些项目的目的就是利用Redis创建非常好的后端工具,以满足各种队列需求。例如,Celery有一个后台就是使用Redis作为broker,你可以从这里去查看。
(4),排行榜/计数器
Redis在内存中对数字进行递增或递减的操作实现的非常好。集合(Set)和有序集合(Sorted Set)也使得我们在执行这些操作的时候变的非常简单,Redis只是正好提供了这两种数据结构。所以,我们要从排序集合中获取到排名最靠前的10个用户–我们称之为“user_scores”,我们只需要像下面一样执行即可:
当然,这是假定你是根据你用户的分数做递增的排序。如果你想返回用户及用户的分数,你需要这样执行:
ZRANGE user_scores 0 10 WITHSCORES
Agora Games就是一个很好的例子,用Ruby实现的,它的排行榜就是使用Redis来存储数据的,你可以在这里看到。
(5)、发布/订阅
最后(但肯定不是最不重要的)是Redis的发布/订阅功能。发布/订阅的使用场景确实非常多。我已看见人们在社交网络连接中使用,还可作为基于发布/订阅的脚本触发器,甚至用Redis的发布/订阅功能来建立聊天系统!(不,这是真的,你可以去核实)。
Redis提供的所有特性中,我感觉这个是喜欢的人最少的一个,虽然它为用户提供如果此多功能。
高可用分布式集群
一,高可用
高可用(High Availability),是当一台服务器停止服务后,对于业务及用户毫无影响。 停止服务的原因可能由于网卡、路由器、机房、CPU负载过高、内存溢出、自然灾害等不可预期的原因导致,在很多时候也称单点问题。
(1)解决单点问题主要有2种方式:
主备方式
这种通常是一台主机、一台或多台备机,在正常情况下主机对外提供服务,并把数据同步到备机,当主机宕机后,备机立刻开始服务。
Redis HA中使用比较多的是keepalived,它使主机备机对外提供同一个虚拟IP,客户端通过虚拟IP进行数据操作,正常期间主机一直对外提供服务,宕机后VIP自动漂移到备机上。
优点是对客户端毫无影响,仍然通过VIP操作。
缺点也很明显,在绝大多数时间内备机是一直没使用,被浪费着的。
主从方式
这种采取一主多从的办法,主从之间进行数据同步。 当Master宕机后,通过选举算法(Paxos、Raft)从slave中选举出新Master继续对外提供服务,主机恢复后以slave的身份重新加入。
主从另一个目的是进行读写分离,这是当单机读写压力过高的一种通用型解决方案。 其主机的角色只提供写操作或少量的读,把多余读请求通过负载均衡算法分流到单个或多个slave服务器上。
缺点是主机宕机后,Slave虽然被选举成新Master了,但对外提供的IP服务地址却发生变化了,意味着会影响到客户端。 解决这种情况需要一些额外的工作,在当主机地址发生变化后及时通知到客户端,客户端收到新地址后,使用新地址继续发送新请求。
(2)数据同步
无论是主备还是主从都牵扯到数据同步的问题,这也分2种情况:
同步方式:当主机收到客户端写操作后,以同步方式把数据同步到从机上,当从机也成功写入后,主机才返回给客户端成功,也称数据强一致性。 很显然这种方式性能会降低不少,当从机很多时,可以不用每台都同步,主机同步某一台从机后,从机再把数据分发同步到其他从机上,这样提高主机性能分担同步压力。 在redis中是支持这杨配置的,一台master,一台slave,同时这台salve又作为其他slave的master。
异步方式:主机接收到写操作后,直接返回成功,然后在后台用异步方式把数据同步到从机上。 这种同步性能比较好,但无法保证数据的完整性,比如在异步同步过程中主机突然宕机了,也称这种方式为数据弱一致性。
Redis主从同步采用的是异步方式,因此会有少量丢数据的危险。还有种弱一致性的特例叫最终一致性,这块详细内容可参见CAP原理及一致性模型。
(3)方案选择
keepalived方案配置简单、人力成本小,在数据量少、压力小的情况下推荐使用。 如果数据量比较大,不希望过多浪费机器,还希望在宕机后,做一些自定义的措施,比如报警、记日志、数据迁移等操作,推荐使用主从方式,因为和主从搭配的一般还有个管理监控中心。
宕机通知这块,可以集成到客户端组件上,也可单独抽离出来。 Redis官方Sentinel支持故障自动转移、通知等,详情见低成本高可用方案设计(四)。
逻辑图: 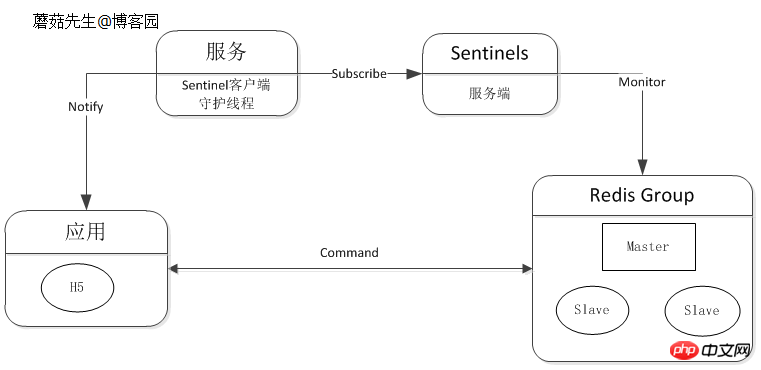
二,分布式
分布式(distributed), 是当业务量、数据量增加时,可以通过任意增加减少服务器数量来解决问题。
集群时代
至少部署两台Redis服务器构成一个小的集群,主要有2个目的:
高可用性:在主机挂掉后,自动故障转移,使前端服务对用户无影响。
读写分离:将主机读压力分流到从机上。
可在客户端组件上实现负载均衡,根据不同服务器的运行情况,分担不同比例的读请求压力。
逻辑图: 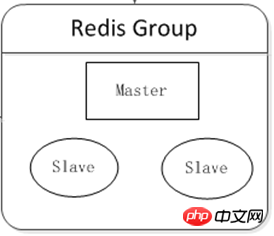
三,分布式集群时代
当缓存数据量不断增加时,单机内存不够使用,需要把数据切分不同部分,分布到多台服务器上。
可在客户端对数据进行分片,数据分片算法详见C#一致性Hash详解、C#之虚拟桶分片。
逻辑图: 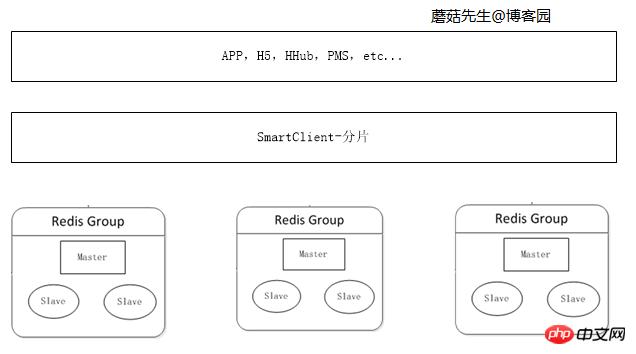
大规模分布式集群时代
当数据量持续增加时,应用可根据不同场景下的业务申请对应的分布式集群。 这块最关键的是缓存治理这块,其中最重要的部分是加入了代理服务。 应用通过代理访问真实的Redis服务器进行读写,这样做的好处是:
避免越来越多的客户端直接访问Redis服务器难以管理,而造成风险。
在代理这一层可以做对应的安全措施,比如限流、授权、分片。
避免客户端越来越多的逻辑代码,不但臃肿升级还比较麻烦。
代理这层无状态的,可任意扩展节点,对于客户端来说,访问代理跟访问单机Redis一样。
目前楼主公司使用的是客户端组件和代理两种方案并存,因为通过代理会影响一定的性能。 代理这块对应的方案实现有Twitter的Twemproxy和豌豆荚的codis。
逻辑图: 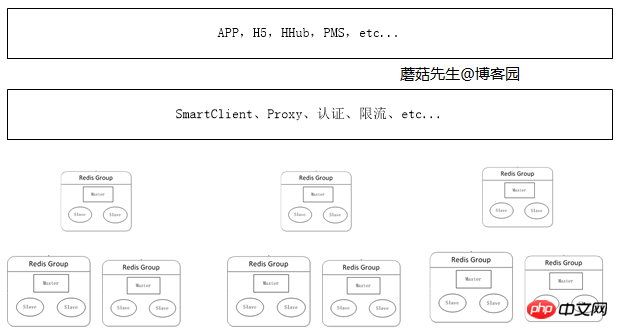
四,总结
分布式缓存再向后是云服务缓存,对使用端完全屏蔽细节,各应用自行申请大小、流量方案即可,如淘宝OCS云服务缓存。
分布式缓存对应需要的实现组件有:
一个缓存监控、迁移、管理中心。
一个自定义的客户端组件,上图中的SmartClient。
一个无状态的代理服务。
N台服务器。
相关学习推荐:redis视频教程
相关学习推荐:mysql视频教程
Atas ialah kandungan terperinci Redis面试题及分布式集群. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bagaimanakah anda dapat mencegah serangan penetapan sesi?Apr 28, 2025 am 12:25 AM
Bagaimanakah anda dapat mencegah serangan penetapan sesi?Apr 28, 2025 am 12:25 AMKaedah yang berkesan untuk mengelakkan serangan tetap sesi termasuk: 1. Meningkatkan semula ID Sesi selepas log pengguna masuk; 2. Gunakan algoritma penjanaan ID sesi yang selamat; 3. Melaksanakan mekanisme masa tamat sesi; 4. Menyulitkan data sesi menggunakan HTTPS. Langkah -langkah ini dapat memastikan bahawa aplikasi itu tidak dapat dihancurkan apabila menghadapi serangan tetap sesi.
 Bagaimana anda melaksanakan pengesahan tanpa sesi?Apr 28, 2025 am 12:24 AM
Bagaimana anda melaksanakan pengesahan tanpa sesi?Apr 28, 2025 am 12:24 AMMelaksanakan pengesahan bebas sesi boleh dicapai dengan menggunakan JSONWEBTOKENS (JWT), sistem pengesahan berasaskan token di mana semua maklumat yang diperlukan disimpan dalam token tanpa penyimpanan sesi pelayan. 1) Gunakan JWT untuk menjana dan mengesahkan token, 2) memastikan bahawa HTTPS digunakan untuk mengelakkan token daripada dipintas, 3) menyimpan token dengan selamat di sisi klien, 4) mengesahkan token di sisi pelayan untuk mengelakkan gangguan, 5) melaksanakan mekanisme pembatalan token.
 Apakah beberapa risiko keselamatan biasa yang berkaitan dengan sesi PHP?Apr 28, 2025 am 12:24 AM
Apakah beberapa risiko keselamatan biasa yang berkaitan dengan sesi PHP?Apr 28, 2025 am 12:24 AMRisiko keselamatan sesi PHP terutamanya termasuk rampasan sesi, penetapan sesi, ramalan sesi dan keracunan sesi. 1. Sesi rampasan boleh dicegah dengan menggunakan HTTPS dan melindungi kuki. 2. Penetapan sesi boleh dielakkan dengan menanam semula ID sesi sebelum log pengguna masuk. 4. Keracunan sesi boleh dicegah dengan mengesahkan dan menapis data sesi.
 Bagaimana anda memusnahkan sesi PHP?Apr 28, 2025 am 12:16 AM
Bagaimana anda memusnahkan sesi PHP?Apr 28, 2025 am 12:16 AMUntuk memusnahkan sesi PHP, anda perlu memulakan sesi terlebih dahulu, kemudian membersihkan data dan memusnahkan fail sesi. 1. Gunakan session_start () untuk memulakan sesi. 2. Gunakan session_unset () untuk membersihkan data sesi. 3. Akhirnya, gunakan session_destroy () untuk memusnahkan fail sesi untuk memastikan keselamatan data dan pelepasan sumber.
 Bagaimanakah anda boleh menukar sesi simpan sesi lalai di php?Apr 28, 2025 am 12:12 AM
Bagaimanakah anda boleh menukar sesi simpan sesi lalai di php?Apr 28, 2025 am 12:12 AMBagaimana cara menukar laluan penjimatan sesi lalai PHP? Ia boleh dicapai melalui langkah -langkah berikut: gunakan session_save_path ('/var/www/sesi'); session_start (); Dalam skrip PHP untuk menetapkan laluan penjimatan sesi. Tetapkan session.save_path = "/var/www/sesi" dalam fail php.ini untuk menukar laluan penjimatan sesi di seluruh dunia. Gunakan memcached atau redis untuk menyimpan data sesi, seperti ini_set ('session.save_handler', 'memcached'); ini_set (
 Bagaimana anda mengubah suai data yang disimpan dalam sesi PHP?Apr 27, 2025 am 12:23 AM
Bagaimana anda mengubah suai data yang disimpan dalam sesi PHP?Apr 27, 2025 am 12:23 AMTomodififydatainaphpsession, startTheSessionWithSsion_start (), thenuse $ _SessionToset, Modify, Orremovariables.1) startTheSession.2) setOrmodifySessionVariabelinging $ _Session.3) ReveVariablesWithunset ()
 Berikan contoh menyimpan array dalam sesi PHP.Apr 27, 2025 am 12:20 AM
Berikan contoh menyimpan array dalam sesi PHP.Apr 27, 2025 am 12:20 AMArray boleh disimpan dalam sesi PHP. 1. Mulakan sesi dan gunakan session_start (). 2. Buat array dan simpan dalam $ _Session. 3. Dapatkan array melalui $ _Session. 4. Mengoptimumkan data sesi untuk meningkatkan prestasi.
 Bagaimanakah pengumpulan sampah berfungsi untuk sesi PHP?Apr 27, 2025 am 12:19 AM
Bagaimanakah pengumpulan sampah berfungsi untuk sesi PHP?Apr 27, 2025 am 12:19 AMPengumpulan sampah sesi PHP dicetuskan melalui mekanisme kebarangkalian untuk membersihkan data sesi yang telah tamat tempoh. 1) Tetapkan kebarangkalian pencetus dan kitaran hayat sesi dalam fail konfigurasi; 2) Anda boleh menggunakan tugas cron untuk mengoptimumkan aplikasi beban tinggi; 3) Anda perlu mengimbangi kekerapan dan prestasi pengumpulan sampah untuk mengelakkan kehilangan data.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

ZendStudio 13.5.1 Mac
Persekitaran pembangunan bersepadu PHP yang berkuasa

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

