
Rumah >pembangunan bahagian belakang >Tutorial Python >Python 网络爬虫--关于简单的模拟登录
Python 网络爬虫--关于简单的模拟登录

- 不言asal
- 2018-06-02 14:18:071763semak imbas
今天这篇文章主要介绍了关于Python 网络爬虫--关于简单的模拟登录,有着一定的参考价值,现在分享给大家,有需要的朋友可以参考一下
和获取网页上的信息不同,想要进行模拟登录还需要向服务器发送一些信息,如账号、密码等等。
模拟登录一个网站大致分为这么几步:
1.先将登录网站的隐藏信息找到,并将其内容先进行保存(由于我这里登录的网站并没有额外信息,所以这里没有进行信息筛选保存)
2.将信息进行提交
3.获取登录后的信息
先给上源码
<span style="font-size: 14px;"># -*- coding: utf-8 -*-
import requests
def login():
session = requests.session()
# res = session.get('http://my.its.csu.edu.cn/').content
login_data = {
'userName': '3903150327',
'passWord': '136510',
'enter': 'true'
}
session.post('http://my.its.csu.edu.cn//', data=login_data)
res = session.get('http://my.its.csu.edu.cn/Home/Default')
print(res.text)
login()</span>
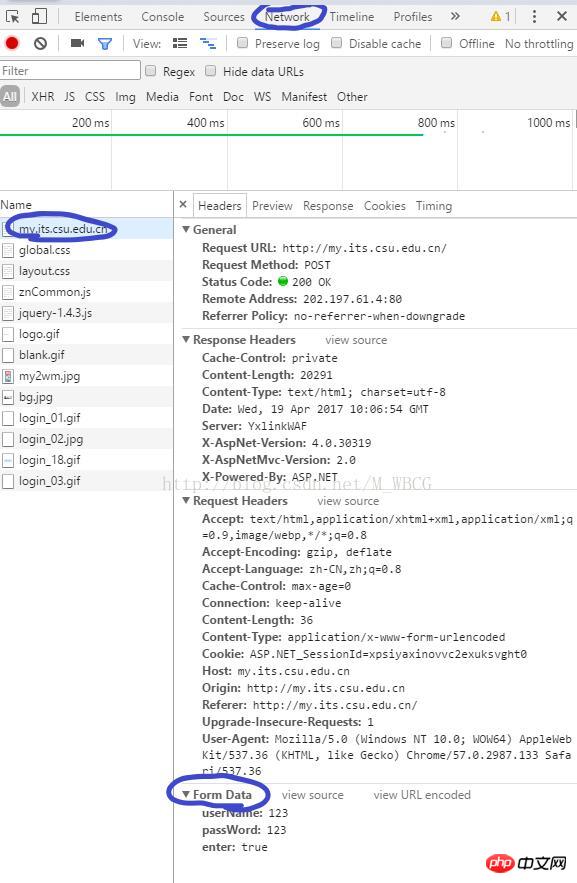
一、筛选得到隐藏信息
进入开发者工具(按F12),找到其中的Network后,手动的先进行一次登录,找到其中的第一个请求,在Header的底部会有一个data的数据段,这个就是登录所需的信息。如果想对其中的隐藏信息进行修改
先获取网页Html的内容
res = session.get('http://my.its.csu.edu.cn/').content
再通过正则表达式筛选内容
二、将信息进行提交
找到源码中提交表单所需要的action,和method
使用
session.post('http://my.its.csu.edu.cn/(这里就是提交的action)', data=login_data)
该方法提交信息
三、获取登录后的信息
信息提交后模拟登录就成功了
接下来就可以获取登录后的信息了
res = session.get('http://my.its.csu.edu.cn/Home/Default').content
相关推荐:
Atas ialah kandungan terperinci Python 网络爬虫--关于简单的模拟登录. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:
Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn
Artikel sebelumnya:Python中的模块string.pyArtikel seterusnya:Python一键搭建Http服务器的方法