
Rumah >pembangunan bahagian belakang >Tutorial Python >python实现图书馆研习室自动预约功能
python实现图书馆研习室自动预约功能

- 不言asal
- 2018-04-27 10:38:363287semak imbas
这篇文章主要为大家详细介绍了python实现图书馆研习室自动预约功能,具有一定的参考价值,感兴趣的小伙伴们可以参考一下
本文为大家分享了python实现图书馆研习室自动预约的具体代码,供大家参考,具体内容如下
简介
现在好多学校为学生提供了非常良好的学习环境,通常体现在自习教室的设施设备上。对此不得不提一句的就是我们学校的图书馆,随着新图书馆的修建,馆内也设置了多个功能区,每层分为A、B、C、D四个区域,由南北连廊相连,中间由旋转楼梯贯通一至五层。A区为自修区;B区和C区为藏阅一体的社会科学和自然科学书库;D区为专项功能区,包含影视厅、数字媒体创客体验中心、智慧培训教室、云桌面电子阅览室等;B、C区东西连廊设有大小十二间研习室;南北连廊设有休闲阅读区。
上面那段我是从图书馆官网上抄的,不过真的得为学校的图书馆点个赞。回归本篇文章正题,学校免费为广大师生提供了舒适优良设备齐全的研习室。但是这些研习室是需要进行网上预约才能够进入使用,每天的00:00开启下一天的预约,因此要想约到一个时间段(3小时)的研习室,可谓得“挑灯夜战”。当然,在这个过程中手速快将有巨大的优势。如果晚上休息的早,手速又不快,基本上就别想预约到研习室了。刚刚好最近学了一点python爬虫,就打算用爬虫帮我完成这个艰巨的任务了。哈哈哈哈!(ps:防止恶意访问,所有链接就不放了哈)
python实现思路
想想思路还是挺简单的,无非就是登录账号、查找房间、提交预约。那就让我们试试看:
登录账号
首先打开我们研习室预约的登录界面,链接为:U2FsdGVkX19NdfJkghN54Msvy1zl7AucRur/ct0nz4orPI7uLkSDsvuFMgr0fGcO
rn9Z/f8h3bds9w==
好吧,这第一步登录账号就非常考验我这个新手了,不过不能怂。通过参考其他一些大佬使用的方法,就是打开firefox的firebug(ctrl+shift+e)查看网络情况,在这个情况下进行一次正常的登录。

可以看到我们这里有个post,到时便可以使用python中requests.post方法。
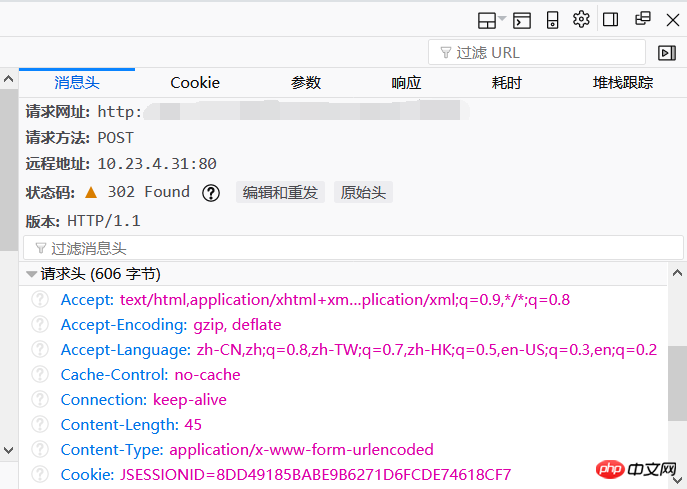
为了能够成功的登录,要隐藏自己是个爬虫的身份,在消息头中,可以看到我们的请求头,只要将参数都复制过来,组成自己的headers = {…}来欺骗服务器。
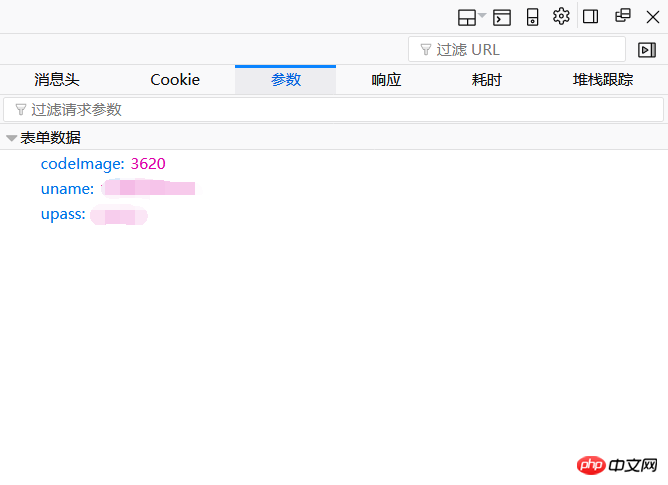
看一下参数这一页,这里的表单数据只有三个,分别对应着验证码、账号和密码。将这里的参数复制过来,就可以组成我们的data = {…}。其中需要我们的注意的就是这个验证码,无论是人工“自”能识别,还是机器自动识别,都需要将验证码保存为本地文件。如此一来,就有了一个问题,每访问一次服务器,验证码就会变换。现在让我们好好捋捋思路,首先我们得获得验证码并将其保存在本地,这就需要访问一次服务器,最后我们要提交我们的参数进行登录,这又再一次访问了服务器,这次的验证码和我们获取的验证码已经不是同一个验证码了。在刚刚开始的尝试中我无论如何无法登录服务器,就是两次的验证码不匹配。如何实现第一次获取的验证码和提交时的验证码相一致呢?
这里就需要同一个cookie在上面的几个图中,我们都能看到有个cookie值。要保证同步,这里就需要做到,我们获取验证码时的cookie值和提交账号密码时的cookie值一致。因此,在我的程序中,我先做的一个步骤时先获取一个cookie值,然后将这个cookie值作为headers中的一个参数。登录的思路就是这样了,补充一句,这里的验证码我是自己手动识别的>﹏<。
查找房间
这个步骤其实是一个无用的步骤,为什么有这个步骤,按照人为预约习惯,我们会产生怎么一个步骤,但是如果使用爬虫,只要成功登录之后就可以直接提交预约的表单。当然,如果要使得自动预约程序更加智能,便可以添加这个步骤,可以查看那些房间是还可以预约的,在这里自定义的补充一些规则。我就略过了。。。
提交预约
同登录一样,我们也手动的提交一次,去查看网络情况,便可以用python模拟这一个过程。在这里我就不在贴图进行解释,这里提交也是用requests.post的方法。不过一点要注意的是,这里的headers和登录时的headers是不一样的,所以在此提醒各位,如果在其他类似的预约程序中可以注意看看不同内容post时的headers是否一致。我在这里就被坑了一会。
#!/usr/bin/env python
# _*_ coding:utf-8 _*_
#
# @Version : 1.0
# @Time : 2018/4/10
# @Author : 圈圈烃
# @File : reservation_4.py
import requests
import re
import json
import datetime
import time
def get_cookies():
"""获得cookies"""
url = 'http://**************'
s = requests.session()
s.get(url)
ck_dict = requests.utils.dict_from_cookiejar(s.cookies) # 将jar格式转化为dict
ck = 'JSESSIONID=' + ck_dict['JSESSIONID'] # 重组cookies
"""获得二维码"""
path = './code.png'
get_cookies_headers = {
'user-anget': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0',
'Cookie': ck}
get_cookies_url = 'http://**************'
code_image = requests.get(get_cookies_url, headers=get_cookies_headers)
with open(path, 'wb') as fn:
fn.write(code_image.content)
fn.close()
print('验证码保存成功')
return ck
def login(cookies, hour, minute):
login_headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '45',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': cookies,
'Host': '**************',
'Pragma': 'no-cache',
'Referer': 'http://**************',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
login_url = 'http://**************'
login_data = {
'codeImage': input('请输入验证码:'),
'uname': '**************',
'upass': '**************'
}
requests.post(login_url, data=login_data, headers=login_headers)
res = requests.get('http://**************', headers=login_headers)
reg_h = r'<option value=(.*?)>\d{4}-\d{2}-\d{2}' # 匹配可提供预约的hash
value_h = re.findall(reg_h, res.text)
"""定时"""
counter = 0
while (True):
now = datetime.datetime.now() # 获取当前系统时间
if now.hour == hour and now.minute == minute:
break
time.sleep(0.5)
# print(now)
counter = counter + 1
if counter == 240:
res = requests.get('http://**************', headers=login_headers)
reg_h = r'<option value=(.*?)>\d{4}-\d{2}-\d{2}' # 匹配可提供预约的hash
reg_t = r'(\d{4}-\d{2}-\d{2})' # 匹配可提供预约的日期
value_h = re.findall(reg_h, res.text)
value_t = re.findall(reg_t, res.text)
with open('./con_log.txt', 'a') as fjs:
fjs.write(eval(value_h[-1])+' '+value_t[-1]+' '+str(now)+' \n')
fjs.close()
print('保存成功')
counter = 0
return str(eval(value_h[-1]))
def reservation(day_hash, cookies, stime, etime):
reservation_data = {
'_etime': etime, # 结束时间11点,其值为11*60=660
'_roomid': '1285b3ca77594b3095c7b89d4922553c', # 房间Id
'_seatno': '',
'_stime': stime, # 开始时间8点,其值为8*60=480
'_subject': '学习', # 研讨主题
'_summary': '学习', # 研讨大纲
'ruleId': day_hash,
'usercount': 3, # 预约人数
'users': '**************', # 学号
'UUID': '**************'
}
reservation_headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Length': '239',
'Content-Type': 'application/json',
'Cookie': cookies,
'Host': '**************',
'Pragma': 'no-cache',
'Referer': 'http://**************',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:59.0) Gecko/20100101 Firefox/59.0'
}
reservation_js = json.dumps(reservation_data)
reservation_url = 'http://**************'
status = requests.post(reservation_url, data=reservation_js, headers=reservation_headers)
# print(stime, etime)
# print(status)
print(status.text)
def main():
"""预约策略一:11:20-20.40"""
full_stime = ['1060', '870', '680']
full_etime = ['1240', '1050', '860']
"""预约策略二:10:00-13:00;13:50-16:50;17:40-20:40"""
stime = ['1060', '830', '600']
etime = ['1240', '1010', '780']
cookies = get_cookies()
day_hash = login(cookies, 0, 0) # 设定定时时间
for i in range(0, 3):
reservation(day_hash, cookies, stime[i], etime[i])
if __name__ == '__main__':
main()
实现效果
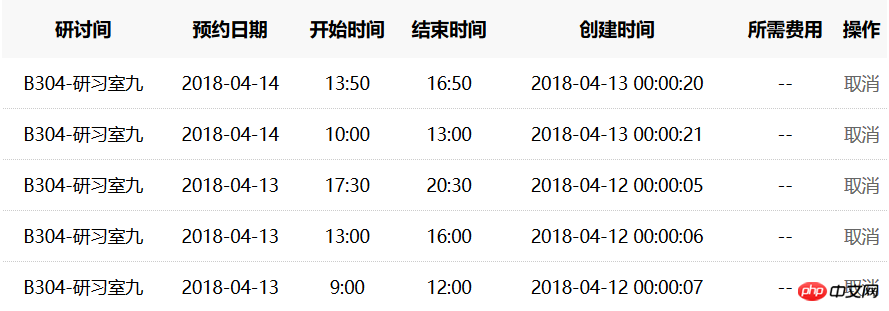
自从学了python,妈妈再也不用担心我抢不到研习室了。在程序中加几行定时的程序之后,便可以在00:00自动帮我预约研习室了。通过测试发现,预约时很大程度上是能够约到房间的,例如在4-12号,约好三个时间段是用了7秒,但是在4-13号居然花了21秒,而且使得一个时间段被其他同学约走了。当然这个程序还需要进一步改进,实现完胜“手速”。
补在最后
还有不足,欢迎交流。
相关推荐:
Atas ialah kandungan terperinci python实现图书馆研习室自动预约功能. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!