
Rumah >pembangunan bahagian belakang >tutorial php >HTTP请求头与请求体详解
HTTP请求头与请求体详解

- 小云云asal
- 2018-03-29 11:13:217014semak imbas
本文主要和大家分享HTTP请求头与请求体详解,对于HTTP的学习主要包含HTTP 基础、HTTP 请求头与请求体、HTTP 响应头与状态码、HTTP 缓存这四个部分,而对于HTTP相关的扩展与引申,我们还需要了解HTTPS 理解与实践 、HTTP/2 基础、WebSocket 基础这些部分。本部分知识点同时也归纳于笔者的我的校招准备之路:从Web前端到服务端应用架构这篇综述。
HTTP Request
HTTP 的请求报文分为三个部分 请求行、请求头和请求体,格式如图:
一个典型的请求消息头域,如下所示:
POST/GET http://download.microtool.de:80/somedata.exe Host: download.microtool.de Accept:*/* Pragma: no-cache Cache-Control: no-cache Referer: http://download.microtool.de/ User-Agent:Mozilla/4.04[en](Win95;I;Nav) Range:bytes=554554-
Request Line:请求行
请求行(Request Line)分为三个部分:请求方法、请求地址和协议及版本,以CRLF(rn)结束。
HTTP/1.1 定义的请求方法有8种:GET、POST、PUT、DELETE、PATCH、HEAD、OPTIONS、TRACE,最常的两种GET和POST,如果是RESTful接口的话一般会用到GET、POST、DELETE、PUT。
Request Methods
注意,仅有POST、PUT以及PATCH这三个动词时会包含请求体,而GET、HEAD、DELETE、CONNECT、TRACE、OPTIONS这几个动词时不包含请求体。
Header:请求头
| Header | 解释 | 示例 |
|---|---|---|
| Accept | 指定客户端能够接收的内容类型 | Accept: text/plain, text/html,application/json |
| Accept-Charset | 浏览器可以接受的字符编码集。 | Accept-Charset: iso-8859-5 |
| Accept-Encoding | 指定浏览器可以支持的web服务器返回内容压缩编码类型。 | Accept-Encoding: compress, gzip |
| Accept-Language | 浏览器可接受的语言 | Accept-Language: en,zh |
| Accept-Ranges | 可以请求网页实体的一个或者多个子范围字段 | Accept-Ranges: bytes |
| Authorization | HTTP授权的授权证书 | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Cache-Control | 指定请求和响应遵循的缓存机制 | Cache-Control: no-cache |
| Connection | 表示是否需要持久连接。(HTTP 1.1默认进行持久连接) | Connection: close |
| Cookie | HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。 | Cookie: $Version=1; Skin=new; |
| Content-Length | 请求的内容长度 | Content-Length: 348 |
| Content-Type | 请求的与实体对应的MIME信息 | Content-Type: application/x-www-form-urlencoded |
| Date | 请求发送的日期和时间 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| Expect | 请求的特定的服务器行为 | Expect: 100-continue |
| From | 发出请求的用户的Email | From: user@email.com |
| Host | 指定请求的服务器的域名和端口号 | Host: www.zcmhi.com |
| If-Match | 只有请求内容与实体相匹配才有效 | If-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Modified-Since | 如果请求的部分在指定时间之后被修改则请求成功,未被修改则返回304代码 | If-Modified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| If-None-Match | 如果内容未改变返回304代码,参数为服务器先前发送的Etag,与服务器回应的Etag比较判断是否改变 | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Range | 如果实体未改变,服务器发送客户端丢失的部分,否则发送整个实体。参数也为Etag | If-Range: “737060cd8c284d8af7ad3082f209582d” |
| If-Unmodified-Since | 只在实体在指定时间之后未被修改才请求成功 | If-Unmodified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| Max-Forwards | 限制信息通过代理和网关传送的时间 | Max-Forwards: 10 |
| Pragma | 用来包含实现特定的指令 | Pragma: no-cache |
| Proxy-Authorization | 连接到代理的授权证书 | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Range | 只请求实体的一部分,指定范围 | Range: bytes=500-999 |
| Referer | 先前网页的地址,当前请求网页紧随其后,即来路 | Referer: http://www.zcmhi.com/archives... |
| TE | 客户端愿意接受的传输编码,并通知服务器接受接受尾加头信息 | TE: trailers,deflate;q=0.5 |
| Upgrade | 向服务器指定某种传输协议以便服务器进行转换(如果支持) | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent | User-Agent的内容包含发出请求的用户信息 | User-Agent: Mozilla/5.0 (Linux; X11) |
| Via | 通知中间网关或代理服务器地址,通信协议 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | 关于消息实体的警告信息 | Warn: 199 Miscellaneous warning |
Request Body:请求体
Types
根据应用场景的不同,HTTP请求的请求体有三种不同的形式。
任意类型
移动开发者常见的,请求体是任意类型,服务器不会解析请求体,请求体的处理需要自己解析,如 POST JSON时候就是这类。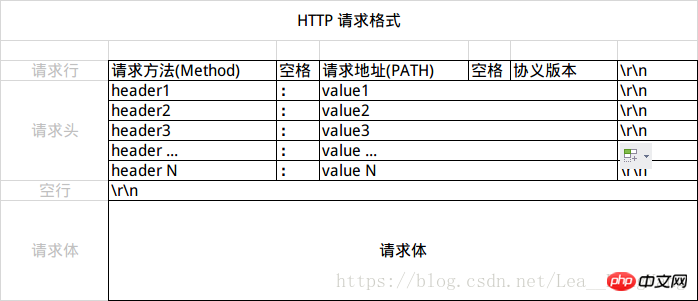
application/json
application/json 这个 Content-Type 作为响应头大家肯定不陌生。实际上,现在越来越多的人把它作为请求头,用来告诉服务端消息主体是序列化后的 JSON 字符串。由于 JSON 规范的流行,除了低版本 IE 之外的各大浏览器都原生支持 JSON.stringify,服务端语言也都有处理 JSON 的函数,使用 JSON 不会遇上什么麻烦。
JSON 格式支持比键值对复杂得多的结构化数据,这一点也很有用。记得我几年前做一个项目时,需要提交的数据层次非常深,我就是把数据 JSON 序列化之后来提交的。不过当时我是把 JSON 字符串作为 val,仍然放在键值对里,以 x-www-form-urlencoded 方式提交。
Google 的 AngularJS 中的 Ajax 功能,默认就是提交 JSON 字符串。例如下面这段代码:
JSvar data = {'title':'test', 'sub' : [1,2,3]};$http.post(url, data).success(function(result) {
...
});最终发送的请求是:
BASHPOST http://www.example.com HTTP/1.1 Content-Type: application/json;charset=utf-8{"title":"test","sub":[1,2,3]}这种方案,可以方便的提交复杂的结构化数据,特别适合 RESTful 的接口。各大抓包工具如 Chrome 自带的开发者工具、Firebug、Fiddler,都会以树形结构展示 JSON 数据,非常友好。但也有些服务端语言还没有支持这种方式,例如 php 就无法通过 $_POST 对象从上面的请求中获得内容。这时候,需要自己动手处理下:在请求头中 Content-Type 为 application/json 时,从 php://input 里获得原始输入流,再 json_decode 成对象。一些 php 框架已经开始这么做了。
当然 AngularJS 也可以配置为使用 x-www-form-urlencoded 方式提交数据。如有需要,可以参考这篇文章。
text/xml
我的博客之前提到过 XML-RPC(XML Remote Procedure Call)。它是一种使用 HTTP 作为传输协议,XML 作为编码方式的远程调用规范。典型的 XML-RPC 请求是这样的:
HTMLPOST http://www.example.com HTTP/1.1
Content-Type: text/xml<?xml version="1.0"?><methodCall>
<methodName>examples.getStateName</methodName>
<params>
<param>
<value><i4>41</i4></value>
</param>
</params></methodCall>XML-RPC 协议简单、功能够用,各种语言的实现都有。它的使用也很广泛,如 WordPress 的 XML-RPC Api,搜索引擎的 ping 服务等等。JavaScript 中,也有现成的库支持以这种方式进行数据交互,能很好的支持已有的 XML-RPC 服务。不过,我个人觉得 XML 结构还是过于臃肿,一般场景用 JSON 会更灵活方便。
Query String:application/x-www-form-urlencoded
这算是最常见的 POST 提交数据的方式了。浏览器的原生 ff9c23ada1bcecdd1a0fb5d5a0f18437 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据。请求类似于下面这样(无关的请求头在本文中都省略掉了):
POST http://www.example.com HTTP/1.1
Content-Type: application/x-www-form-urlencoded;charset=utf-8
title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3
首先,Content-Type 被指定为 application/x-www-form-urlencoded;这里的格式要求就是URL中Query String的格式要求:多个键值对之间用&连接,键与值之前用=连接,且只能用ASCII字符,非ASCII字符需使用UrlEncode编码。大部分服务端语言都对这种方式有很好的支持。例如 PHP 中,$_POST['title'] 可以获取到 title 的值,$_POST['sub'] 可以得到 sub 数组。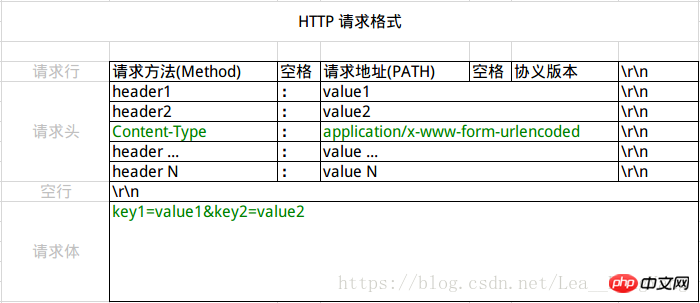
文件分割
第三种请求体的请求体被分成为多个部分,文件上传时会被使用,这种格式最先应该是被用于邮件传输中,每个字段/文件都被boundary(Content-Type中指定)分成单独的段,每段以-- 加 boundary开头,然后是该段的描述头,描述头之后空一行接内容,请求结束的标制为boundary后面加--,结构见下图: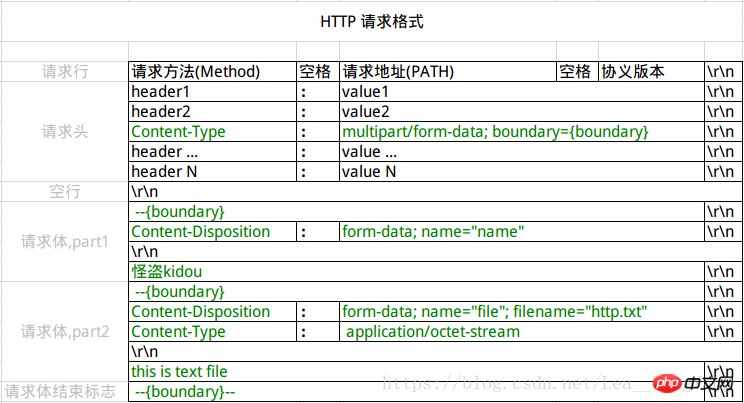
区分是否被当成文件的关键是Content-Disposition是否包含filename,因为文件有不同的类型,所以还要使用Content-Type指示文件的类型,如果不知道是什么类型取值可以为application/octet-stream表示该文件是个二进制文件,如果不是文件则Content-Type可以省略。
我们使用表单上传文件时,必须让 ff9c23ada1bcecdd1a0fb5d5a0f18437 表单的 enctyped 等于 multipart/form-data。直接来看一个请求示例:
BASHPOST http://www.example.com HTTP/1.1Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3TrwA------WebKitFormBoundaryrGKCBY7qhFd3TrwAContent-Disposition: form-data; name="text"title------WebKitFormBoundaryrGKCBY7qhFd3TrwAContent-Disposition: form-data; name="file"; filename="chrome.png"Content-Type: image/pngPNG ... content of chrome.png ...------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
这个例子稍微复杂点。首先生成了一个 boundary 用于分割不同的字段,为了避免与正文内容重复,boundary 很长很复杂。然后 Content-Type 里指明了数据是以 multipart/form-data 来编码,本次请求的 boundary 是什么内容。消息主体里按照字段个数又分为多个结构类似的部分,每部分都是以 --boundary 开始,紧接着是内容描述信息,然后是回车,最后是字段具体内容(文本或二进制)。如果传输的是文件,还要包含文件名和文件类型信息。消息主体最后以 --boundary-- 标示结束。关于 multipart/form-data 的详细定义,请前往 rfc1867 查看。
这种方式一般用来上传文件,各大服务端语言对它也有着良好的支持。
上面提到的这两种 POST 数据的方式,都是浏览器原生支持的,而且现阶段标准中原生 ff9c23ada1bcecdd1a0fb5d5a0f18437 表单也只支持这两种方式(通过 ff9c23ada1bcecdd1a0fb5d5a0f18437 元素的enctype 属性指定,默认为 application/x-www-form-urlencoded。其实 enctype 还支持 text/plain,不过用得非常少)。
随着越来越多的 Web 站点,尤其是 WebApp,全部使用 Ajax 进行数据交互之后,我们完全可以定义新的数据提交方式,给开发带来更多便利。
Encoding:编码
网页中的表单使用POST方法提交时,数据内容的类型是 application/x-www-form-urlencoded,这种类型会:
1.字符"a"-"z","A"-"Z","0"-"9",".","-","*",和"_" 都不会被编码;
2.将空格转换为加号 (+)
3.将非文本内容转换成"%xy"的形式,xy是两位16进制的数值;
4.在每个 name=value 对之间放置 & 符号。
web设计者面临的众多难题之一便是怎样处理不同操作系统间的差异性。这些差异性能引起URL方面的问题:例如,一些操作系统允许文件名中含有空格符,有些又不允许。大多数操作系统不会认为文件名中含有符号“#”会有什么特殊含义;但是在一个URL中,符号“#”表示该文件名已经结束,后面会紧跟一个fragment(部分)标识符。其他的特殊字符,非字母数字字符集,它们在URL或另一个操作系统上都有其特殊的含义,表述着相似的问题。为了解决这些问题,我们在URL中使用的字符就必须是一个ASCII字符集的固定字集中的元素,具体如下:
1.大写字母A-Z
2.小写字母a-z
3.数字 0-9
4.标点符 - _ . ! ~ * ' (和 ,)
诸如字符: / & ? @ # $ + = 和 %也可以被使用,但是它们各有其特殊的用途,如果一个文件名包括了这些字符( / & ? @ # $ + = %),这些字符和所有其他字符就应该被编码。
编码过程非常简单,任何字符只要不是ASCII码数字,字母,或者前面提到的标点符,它们都将被转换成字节形式,每个字节都写成这种形式:一个“%”后面跟着两位16进制的数值。空格是一个特殊情况,因为它们太平常了。它除了被编码成“%20”以外,还能编码为一个“+”。加号(+)本身被编码为%2B。当/ # = & 和?作为名字的一部分来使用时,而不是作为URL部分之间的分隔符来使用时,它们都应该被编码。
WARNING这种策略在存在大量字符集的异构环境中效果不甚理想。例如:在U.S. Windows 系统中, é 被编码为 %E9. 在 U.S. Mac中被编码为%8E。这种不确定性的存在是现存的URI的一个明显的不足。所以在将来URI的规范当中应该通过国际资源标识符(IRIs)进行改善。
类URL并不自动执行编码或解码工作。你能生成一个URL对象,它可以包括非法的ASCII和非ASCII字符和/或%xx。当用方法getPath() 和toExternalForm( ) 作为输出方法时,这种字符和转移符不会自动编码或解码。你应对被用来生成一个URL对象的字符串对象负责,确保所有字符都会被恰当地编码。
相关推荐:
Atas ialah kandungan terperinci HTTP请求头与请求体详解. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Semua simbol ungkapan dalam ungkapan biasa (ringkasan)