


什么叫采集?就是使用PHP程序,把其他网站中的信息抓取到我们自己的数据库中、网站中。本文主要和大家分享3种PHP实现数据采集方法,希望能帮助到大家。
PHP制作采集的技术:
从底层的socket到高层的文件操作函数,一共有3种方法可以实现采集。
1. 使用socket技术采集:
socket采集是最底层的,它只是建立了一个长连接,然后我们要自己构造http协议字符串去发送请求。
例如要想获取这个页面的内容,http://tv.youku.com/?spm=a2hww.20023042.topNav.5~1~3!2~A,用socket写如下:
<?php
//连接,$error错误编号,$errstr错误的字符串,30s是连接超时时间
$fp=fsockopen("www.youku.com",80,$errno,$errstr,30);
if(!$fp) die("连接失败".$errstr);
//构造http协议字符串,因为socket编程是最底层的,它还没有使用http协议
$http="GET /?spm=a2hww.20023042.topNav.5~1~3!2~A HTTP/1.1\r\n"; // \r\n表示前面的是一个命令
$http.="Host:www.youku.com\r\n"; //请求的主机
$http.="Connection:close\r\n\r\n"; // 连接关闭,最后一行要两个\r\n
//发送这个字符串到服务器
fwrite($fp,$http,strlen($http));
//接收服务器返回的数据
$data='';
while (!feof($fp)) {
$data.=fread($fp,4096); //fread读取返回的数据,一次读取4096字节
}
//关闭连接
fclose($fp);
var_dump($data);
?>打印出的结果如下,包含了返回的头信息及页面的源码:

2. 使用curl_一套函数
curl把HTTP协议都封装成了很多函数,直接传相应参数即可,降低了编写HTTP协议字符串的难度。
前提:在php.ini中要开启curl扩展。
//生成一个curl对象 $curl=curl_init(); //设置URL和相应的选项 curl_setopt($curl, CURLOPT_URL, "http://www.youku.com"); curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //将curl_exec()获取的信息以字符串返回,而不是直接输出。 //执行curl操作 $data=curl_exec($curl); var_dump($data);
打印出的结果如下,只包含页面的源码:
3. 直接使用file_get_contents(最顶层的)
前提:在php.ini中设置允许打开一个网络的url地址。

//使用file_get_contents()
$data=file_get_contents("http://www.youku.com");
var_dump($data);
3种方式的选择
网络之间通信主要使用的是以上三种。其中后两种用的较多:如果要批量采集大量的数据时使用第二种【CURL】,性能好、稳定。
偶尔发几个请求发的频繁不密集时使用第三种。
扩展:图片的防盗链如何破?
比如7060网站上的图片做了防盗链:在他的网站中可以看到图片,把图片拿到站外就无法访问。
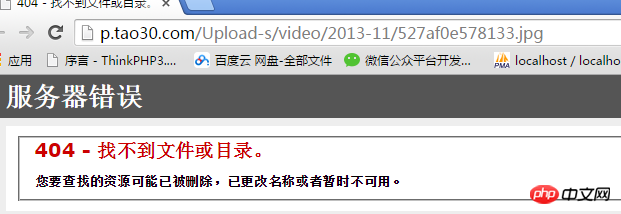
原理:在HTTP协议中有一个referer项,代表发这个请求的来源地址,服务器会判断如果这个请求不是这个网站发来的就会过滤掉这个请求:
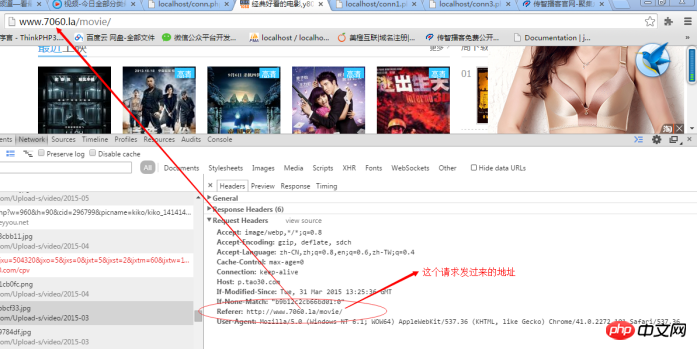
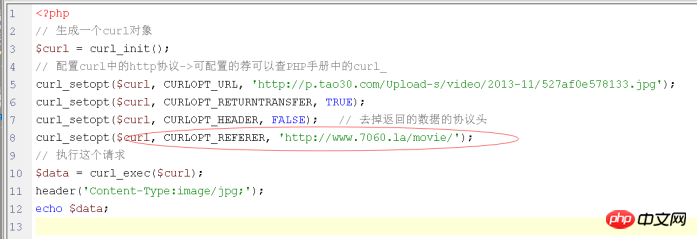
解决办法:发HTTP时自己模拟referer即可:
扩展:有些要采集数据时时必须先登录,可以使用模拟的试模拟在登录状态下的采集:
a. 先用浏览登录一下,登录完,浏览器的COOKIE中就会有SESSIONID
b. 发PHP发HTTP协议时,把浏览器中的SESSIONID放到PHP的HTTP协议请求里,这样就在以登录的状态发请求。
总结:所有客户端发过来的数据都可以被模拟,所以服务器上的程序必须要必要的地方过滤客户端的数据。
什么时候用以上东西?接口开发时、采集时。
二、数据采集
例如我要采集这个url里的所有美国电影的信息,
http://list.youku.com/category/show/c_96_a_%E7%BE%8E%E5%9B%BD_s_1_d_1_p_3.html
则先要知道电影所在的节点的结构,我们使用firebug查看。
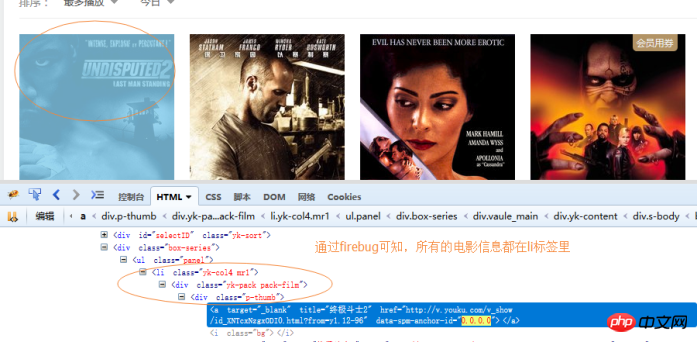
然后开始写代码:完整代码如下
/**
* 发一个GET请求获取数据
*/
function get($url)
{
global $curl;
// 配置curl中的http协议->可配置的荐可以查PHP手册中的curl_
curl_setopt($curl, CURLOPT_URL, $url);
curl_setopt($curl, CURLOPT_RETURNTRANSFER, TRUE);
curl_setopt($curl, CURLOPT_HEADER, FALSE);
// 执行这个请求
return curl_exec($curl);
}
// 生成一个curl对象
$curl = curl_init();
$url='http://list.youku.com/category/show/c_96_a_%E7%BE%8E%E5%9B%BD_s_1_d_1_p_3.html';
$data=get($url);
// 匹配电影所在位置
$list_preg = '/<li class="yk-col4 mr1">.+<\/li>/Us';
// 匹配img标签上的src和alt
$img_preg = '/<img class="quic" _src="(.*)" src="(.*)" alt="(.*)" \/>/U';
//匹配电影的url
$video_preg='/<a href="(.*)" title="(.*)" target="(.*)"><\/a>/U';
//把所有的li存到$list里,$list是个二维数组
preg_match_all($list_preg,$data,$list);
//var_dump($list);
foreach ($list[0] as $k => $v) { //这里$v就是每一个li标签
/* 获取图片及电影名称
preg_match($img_preg,$v,$img); //把匹配到的图片的信息存到$img里
var_dump($img);
*/
/*获取电影地址
preg_match($video_preg,$v,$video); //把匹配到的电影的信息存到$video里
var_dump($video);
*/
preg_match($img_preg,$v,$img);
preg_match($video_preg,$v,$video);
echo $img[0].'<a href="'.$video[1].'">'.$video[2].'</a>';
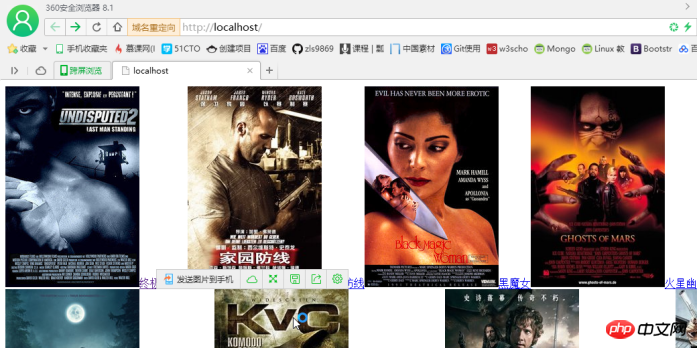
}测试:
打印$list;

打印$img

打印$video

最终效果:
如果需要把图片拷贝到硬盘上,则在foreach循环里加上以下代码:
$imgData = get($img[1]);
// 把图片文件写到硬盘上【下载】
// 因为操作系统是GBK的,所以要把UTF8转成GBK
is_dir('./youkuimg/') ? '': mkdir('./youkuimg/');
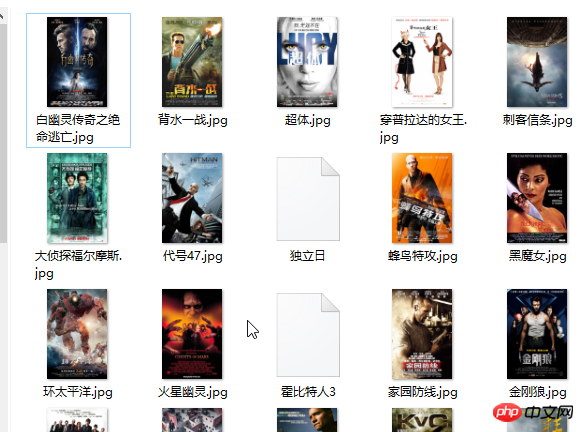
file_put_contents('./youkuimg/'.mb_convert_encoding($img[3], 'gbk', 'utf-8').'.jpg', $imgData);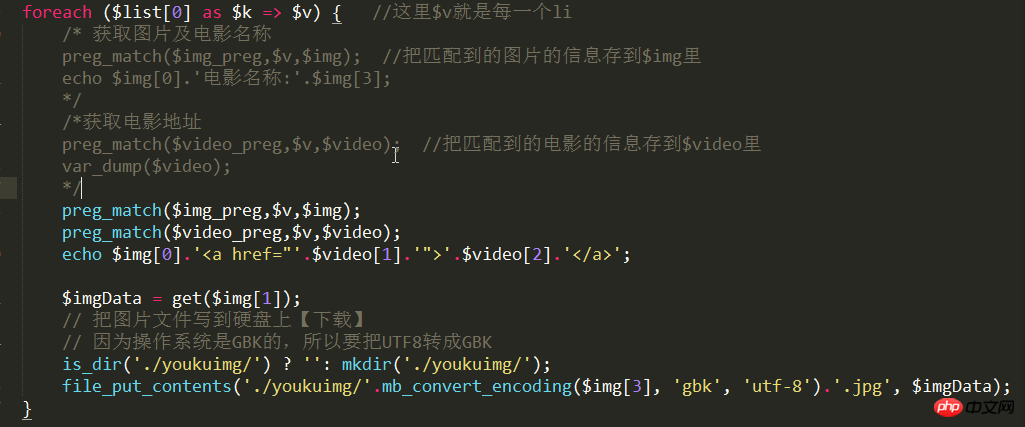
效果如下:在当前目录下的youkuimg目录下就会有下载好的图片。
my github: https://github.com/lensh
Atas ialah kandungan terperinci 3种PHP实现数据采集方法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 PHP dalam Tindakan: Contoh dan aplikasi dunia nyataApr 14, 2025 am 12:19 AM
PHP dalam Tindakan: Contoh dan aplikasi dunia nyataApr 14, 2025 am 12:19 AMPHP digunakan secara meluas dalam e-dagang, sistem pengurusan kandungan dan pembangunan API. 1) e-dagang: Digunakan untuk fungsi keranjang belanja dan pemprosesan pembayaran. 2) Sistem Pengurusan Kandungan: Digunakan untuk penjanaan kandungan dinamik dan pengurusan pengguna. 3) Pembangunan API: Digunakan untuk Pembangunan API RESTful dan Keselamatan API. Melalui pengoptimuman prestasi dan amalan terbaik, kecekapan dan pemeliharaan aplikasi PHP bertambah baik.
 PHP: Membuat kandungan web interaktif dengan mudahApr 14, 2025 am 12:15 AM
PHP: Membuat kandungan web interaktif dengan mudahApr 14, 2025 am 12:15 AMPHP menjadikannya mudah untuk membuat kandungan web interaktif. 1) Secara dinamik menjana kandungan dengan memasukkan HTML dan paparkannya dalam masa nyata berdasarkan input pengguna atau data pangkalan data. 2) Penyerahan borang proses dan menjana output dinamik untuk memastikan bahawa htmlspecialchars digunakan untuk mencegah XSS. 3) Gunakan MySQL untuk membuat sistem pendaftaran pengguna, dan gunakan kata laluan dan preprocessing untuk meningkatkan keselamatan. Menguasai teknik ini akan meningkatkan kecekapan pembangunan web.
 PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popularApr 14, 2025 am 12:13 AM
PHP dan Python: Membandingkan dua bahasa pengaturcaraan yang popularApr 14, 2025 am 12:13 AMPHP dan Python masing -masing mempunyai kelebihan mereka sendiri, dan memilih mengikut keperluan projek. 1.PHP sesuai untuk pembangunan web, terutamanya untuk pembangunan pesat dan penyelenggaraan laman web. 2. Python sesuai untuk sains data, pembelajaran mesin dan kecerdasan buatan, dengan sintaks ringkas dan sesuai untuk pemula.
 Relevannya PHP: Adakah ia masih hidup?Apr 14, 2025 am 12:12 AM
Relevannya PHP: Adakah ia masih hidup?Apr 14, 2025 am 12:12 AMPHP masih dinamik dan masih menduduki kedudukan penting dalam bidang pengaturcaraan moden. 1) kesederhanaan PHP dan sokongan komuniti yang kuat menjadikannya digunakan secara meluas dalam pembangunan web; 2) fleksibiliti dan kestabilannya menjadikannya cemerlang dalam mengendalikan borang web, operasi pangkalan data dan pemprosesan fail; 3) PHP sentiasa berkembang dan mengoptimumkan, sesuai untuk pemula dan pemaju yang berpengalaman.
 Status Semasa PHP: Lihat trend pembangunan webApr 13, 2025 am 12:20 AM
Status Semasa PHP: Lihat trend pembangunan webApr 13, 2025 am 12:20 AMPHP tetap penting dalam pembangunan web moden, terutamanya dalam pengurusan kandungan dan platform e-dagang. 1) PHP mempunyai ekosistem yang kaya dan sokongan rangka kerja yang kuat, seperti Laravel dan Symfony. 2) Pengoptimuman prestasi boleh dicapai melalui OPCACHE dan NGINX. 3) Php8.0 memperkenalkan pengkompil JIT untuk meningkatkan prestasi. 4) Aplikasi awan asli dikerahkan melalui Docker dan Kubernet untuk meningkatkan fleksibiliti dan skalabiliti.
 PHP vs Bahasa Lain: PerbandinganApr 13, 2025 am 12:19 AM
PHP vs Bahasa Lain: PerbandinganApr 13, 2025 am 12:19 AMPHP sesuai untuk pembangunan web, terutamanya dalam pembangunan pesat dan memproses kandungan dinamik, tetapi tidak baik pada sains data dan aplikasi peringkat perusahaan. Berbanding dengan Python, PHP mempunyai lebih banyak kelebihan dalam pembangunan web, tetapi tidak sebaik python dalam bidang sains data; Berbanding dengan Java, PHP melakukan lebih buruk dalam aplikasi peringkat perusahaan, tetapi lebih fleksibel dalam pembangunan web; Berbanding dengan JavaScript, PHP lebih ringkas dalam pembangunan back-end, tetapi tidak sebaik JavaScript dalam pembangunan front-end.
 PHP vs Python: Ciri dan Fungsi TerasApr 13, 2025 am 12:16 AM
PHP vs Python: Ciri dan Fungsi TerasApr 13, 2025 am 12:16 AMPHP dan Python masing -masing mempunyai kelebihan sendiri dan sesuai untuk senario yang berbeza. 1.PHP sesuai untuk pembangunan web dan menyediakan pelayan web terbina dalam dan perpustakaan fungsi yang kaya. 2. Python sesuai untuk sains data dan pembelajaran mesin, dengan sintaks ringkas dan perpustakaan standard yang kuat. Apabila memilih, ia harus diputuskan berdasarkan keperluan projek.
 PHP: Bahasa utama untuk pembangunan webApr 13, 2025 am 12:08 AM
PHP: Bahasa utama untuk pembangunan webApr 13, 2025 am 12:08 AMPHP adalah bahasa skrip yang digunakan secara meluas di sisi pelayan, terutamanya sesuai untuk pembangunan web. 1.PHP boleh membenamkan HTML, memproses permintaan dan respons HTTP, dan menyokong pelbagai pangkalan data. 2.PHP digunakan untuk menjana kandungan web dinamik, data borang proses, pangkalan data akses, dan lain -lain, dengan sokongan komuniti yang kuat dan sumber sumber terbuka. 3. PHP adalah bahasa yang ditafsirkan, dan proses pelaksanaan termasuk analisis leksikal, analisis tatabahasa, penyusunan dan pelaksanaan. 4.Php boleh digabungkan dengan MySQL untuk aplikasi lanjutan seperti sistem pendaftaran pengguna. 5. Apabila debugging php, anda boleh menggunakan fungsi seperti error_reporting () dan var_dump (). 6. Mengoptimumkan kod PHP untuk menggunakan mekanisme caching, mengoptimumkan pertanyaan pangkalan data dan menggunakan fungsi terbina dalam. 7


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

