


根据上面所学的CSS基础语法知识,现在来实现字段的解析。首先还是解析标题。打开网页开发者工具,找到标题所对应的源代码。本文主要介绍了CSS选择器实现字段解析的相关资料,需要的朋友可以参考下,希望能帮助到大家
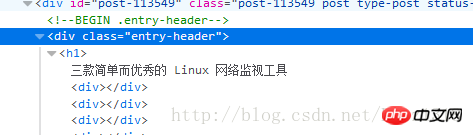
发现是在p class="entry-header"下面的h1节点中,于是打开scrapy shell 进行调试

但是我不想要4a249f0d628e2318394fd9b75b4636b1这种标签该咋办,这时候就要使用CSS选择器中的伪类方法。如下所示。

注意的是两个冒号。使用CSS选择器真的很方便。同理我用CSS实现字段解析。代码如下
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass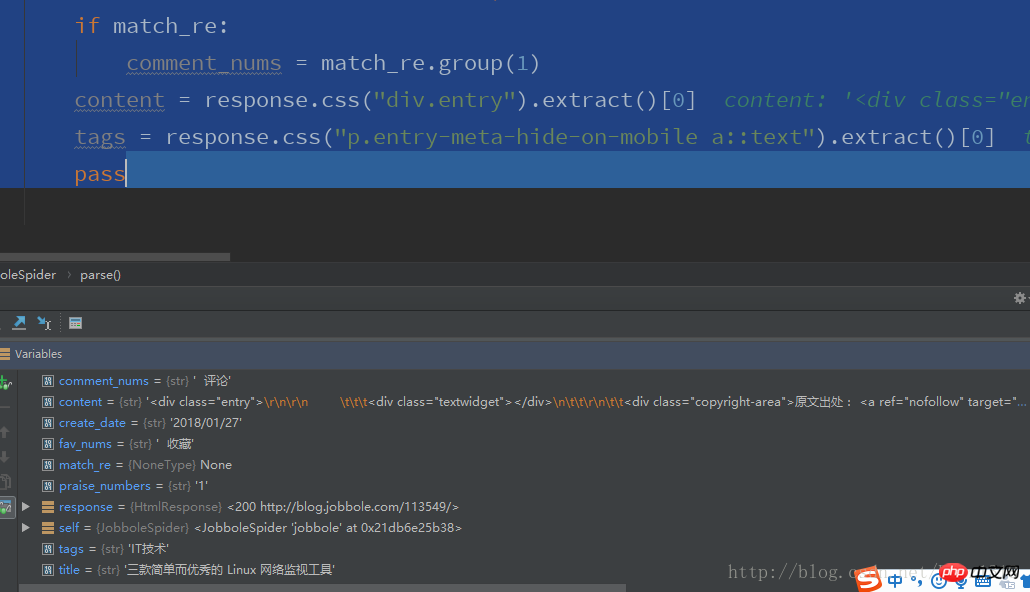
相关推荐:
Atas ialah kandungan terperinci CSS选择器字段解析的实现方法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bagaimana kami menandakan font Google dan mencipta goofonts.comApr 12, 2025 pm 12:02 PM
Bagaimana kami menandakan font Google dan mencipta goofonts.comApr 12, 2025 pm 12:02 PMGoofonts adalah projek sampingan yang ditandatangani oleh isteri pemaju dan suami pereka, kedua-duanya peminat besar tipografi. Kami telah menandakan Google
 Artikel Web Dev yang tidak berkesudahanApr 12, 2025 am 11:44 AM
Artikel Web Dev yang tidak berkesudahanApr 12, 2025 am 11:44 AMPavithra Kodmad meminta orang ramai untuk membuat cadangan mengenai apa yang mereka fikir adalah beberapa artikel yang paling abadi mengenai pembangunan web yang telah mengubahnya
 Perjanjian dengan elemen seksyenApr 12, 2025 am 11:39 AM
Perjanjian dengan elemen seksyenApr 12, 2025 am 11:39 AMDua artikel diterbitkan pada hari yang sama:
 Amalkan pertanyaan GraphQL dengan keadaan API JavaScriptApr 12, 2025 am 11:33 AM
Amalkan pertanyaan GraphQL dengan keadaan API JavaScriptApr 12, 2025 am 11:33 AMBelajar bagaimana untuk membina API GraphQL boleh menjadi agak mencabar. Tetapi anda boleh belajar cara menggunakan API GraphQL dalam 10 minit! Dan ia berlaku saya ' ve mendapat yang sempurna
 CMSS peringkat komponenApr 12, 2025 am 11:09 AM
CMSS peringkat komponenApr 12, 2025 am 11:09 AMApabila komponen tinggal di persekitaran di mana pertanyaan data memisahkannya tinggal berdekatan, terdapat garis langsung yang cukup antara komponen visual dan
 Tetapkan jenis pada bulatan ... dengan laluan mengimbangiApr 12, 2025 am 11:00 AM
Tetapkan jenis pada bulatan ... dengan laluan mengimbangiApr 12, 2025 am 11:00 AMDi sini ' s beberapa CSS Trickery dari Yuanchuan. Terdapat CSS Property Offset-Path. Suatu ketika dahulu, ia dipanggil gerakan-jalan dan kemudian ia dinamakan semula. I
 Apa yang 'kembali' lakukan dalam CSS?Apr 12, 2025 am 10:59 AM
Apa yang 'kembali' lakukan dalam CSS?Apr 12, 2025 am 10:59 AMMiriam Suzanne menerangkan dalam video pemaju Mozilla mengenai subjek.



Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Dreamweaver Mac版
Alat pembangunan web visual

