


本文主要为大家带来一篇python爬取安居客二手房网站数据(实例讲解)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧,希望能帮助到大家。
现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧!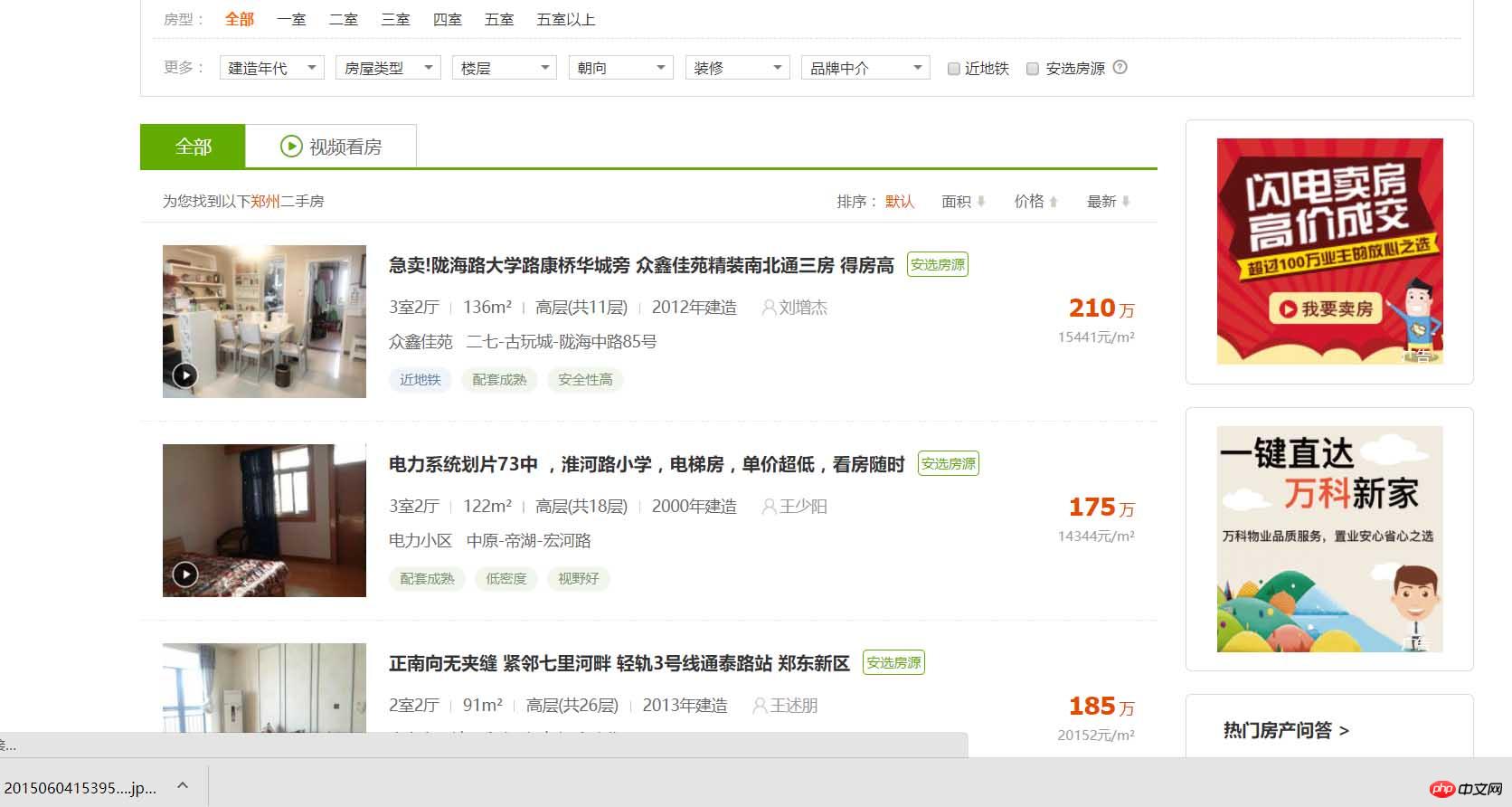
在上面这个页面中,我们可以看到一条条的房源信息,由上可以看到网页一条条的房源信息,点击进去后就会发现:
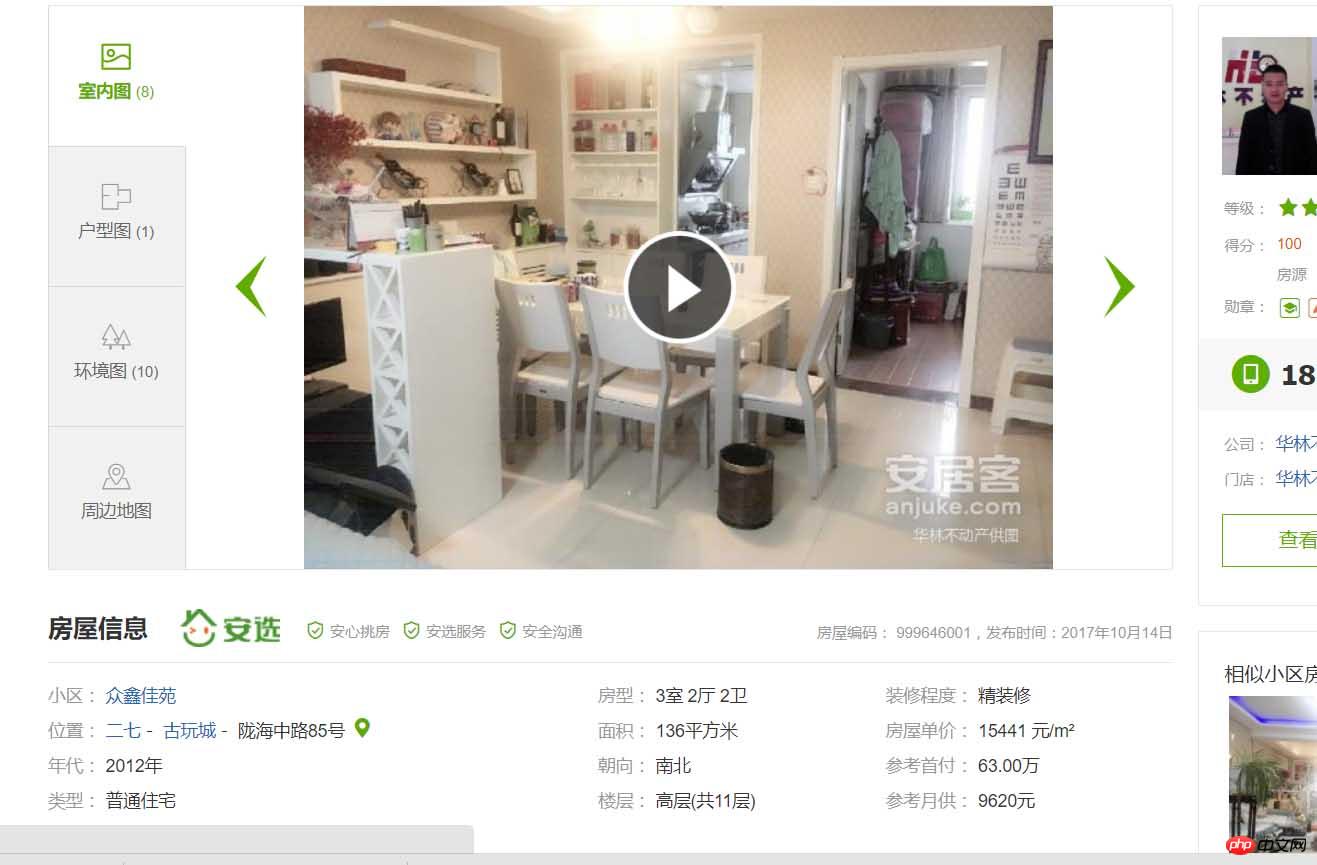
房源的详细信息。OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说了好,正式开始,首先我采用python3.6 中的requests,BeautifulSoup模块来进行爬取页面,首先由requests模块进行请求:
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
response = requests.get(url, headers=header)
print(response.text)执行后就会得到这个网站的html代码了
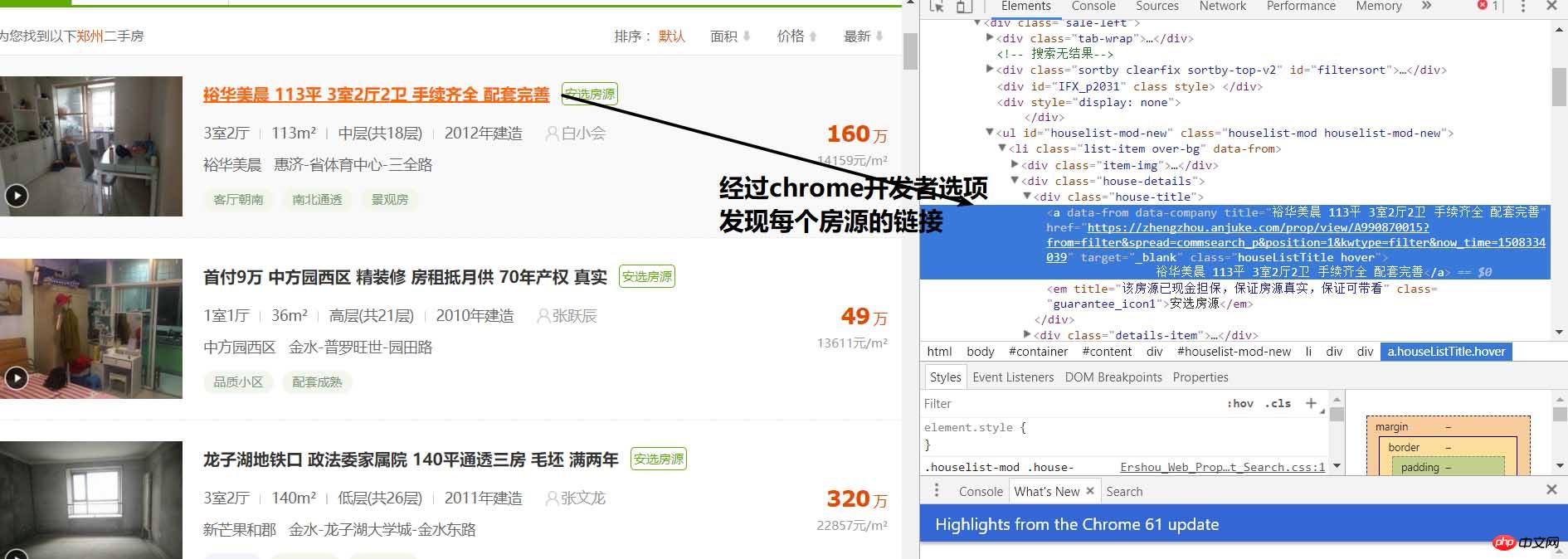
 通过分析可以得到每个房源都在class="list-item"的 li 标签中,那么我们就可以根据BeautifulSoup包进行提取
通过分析可以得到每个房源都在class="list-item"的 li 标签中,那么我们就可以根据BeautifulSoup包进行提取
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
for i in result_li:
print(i)通过打印就能进一步减少了code量,好,继续提取
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
print(result_href.attrs['href'])这样,我们就能看到一个个的url了,是不是很喜欢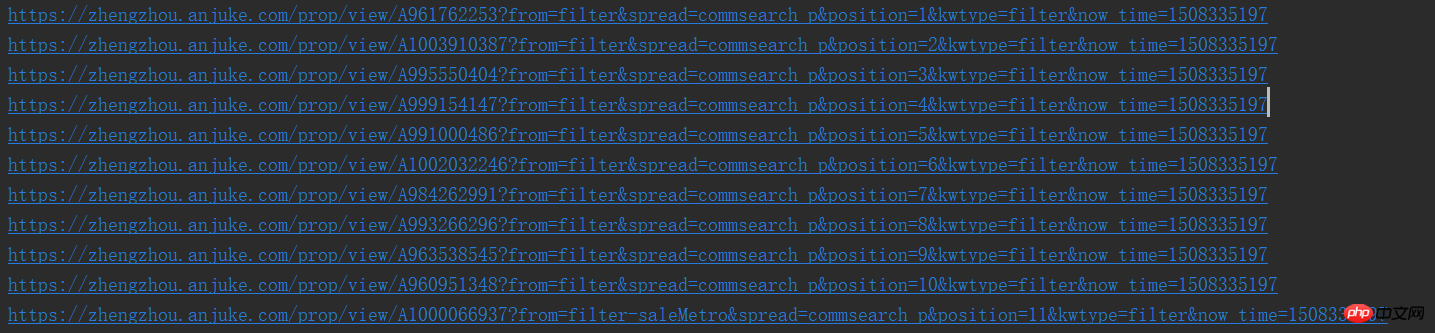
好了,按正常的逻辑就要进入页面开始分析详细页面了,但是爬取完后如何进行下一页的爬取呢所以,我们就需要先分析该页面是否有下一页
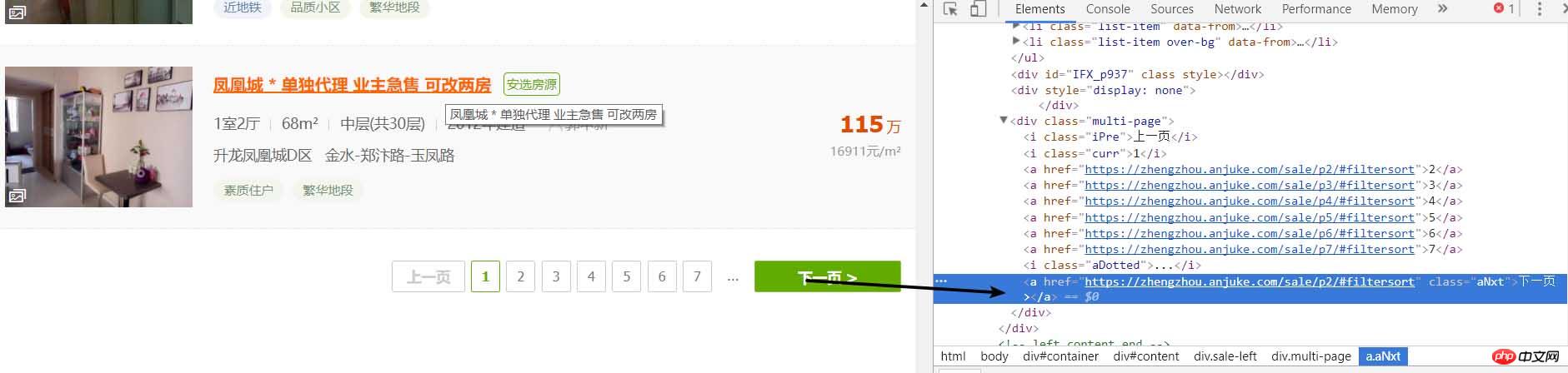
同样的方法就可以发现下一页同样是如此的简单,那么咱们就可以还是按原来的配方原来的味道继续
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
print(result_next_page[0].attrs['href'])
else:
print('没有下一页了')因为当存在下一页的时候,网页中就是一个a标签,如果没有的话,就会成为i标签了,所以这样的就行,因此,我们就能完善一下,将以上这些封装为一个函数
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup = BeautifulSoup(response.text, 'html.parser')
result_li = soup.find_all('li', {'class': 'list-item'})
# 进行下一页的爬取
result_next_page = soup.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 先不做分析,等一会进行详细页面函数完成后进行调用
print(result_href.attrs['href'])
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)好了,那么咱们就开始详细页面的爬取了
哎,怎么动不动就要断电了,大学的坑啊,先把结果附上,闲了在补充,
import requests
from bs4 import BeautifulSoup
# 网页的请求头
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
def get_page(url):
response = requests.get(url, headers=header)
# 通过BeautifulSoup进行解析出每个房源详细列表并进行打印
soup_idex = BeautifulSoup(response.text, 'html.parser')
result_li = soup_idex.find_all('li', {'class': 'list-item'})
# 进行循环遍历其中的房源详细列表
for i in result_li:
# 由于BeautifulSoup传入的必须为字符串,所以进行转换
page_url = str(i)
soup = BeautifulSoup(page_url, 'html.parser')
# 由于通过class解析的为一个列表,所以只需要第一个参数
result_href = soup.find_all('a', {'class': 'houseListTitle'})[0]
# 详细页面的函数调用
get_page_detail(result_href.attrs['href'])
# 进行下一页的爬取
result_next_page = soup_idex.find_all('a', {'class': 'aNxt'})
if len(result_next_page) != 0:
# 函数进行递归
get_page(result_next_page[0].attrs['href'])
else:
print('没有下一页了')
# 进行字符串中空格,换行,tab键的替换及删除字符串两边的空格删除
def my_strip(s):
return str(s).replace(" ", "").replace("\n", "").replace("\t", "").strip()
# 由于频繁进行BeautifulSoup的使用,封装一下,很鸡肋
def my_Beautifulsoup(response):
return BeautifulSoup(str(response), 'html.parser')
# 详细页面的爬取
def get_page_detail(url):
response = requests.get(url, headers=header)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 标题什么的一大堆,哈哈
result_title = soup.find_all('h3', {'class': 'long-title'})[0]
result_price = soup.find_all('span', {'class': 'light info-tag'})[0]
result_house_1 = soup.find_all('p', {'class': 'first-col detail-col'})
result_house_2 = soup.find_all('p', {'class': 'second-col detail-col'})
result_house_3 = soup.find_all('p', {'class': 'third-col detail-col'})
soup_1 = my_Beautifulsoup(result_house_1)
soup_2 = my_Beautifulsoup(result_house_2)
soup_3 = my_Beautifulsoup(result_house_3)
result_house_tar_1 = soup_1.find_all('dd')
result_house_tar_2 = soup_2.find_all('dd')
result_house_tar_3 = soup_3.find_all('dd')
'''
文博公寓,省实验中学,首付只需70万,大三房,诚心卖,价可谈 270万
宇泰文博公寓 金水-花园路-文博东路4号 2010年 普通住宅
3室2厅2卫 140平方米 南北 中层(共32层)
精装修 19285元/m² 81.00万
'''
print(my_strip(result_title.text), my_strip(result_price.text))
print(my_strip(result_house_tar_1[0].text),
my_strip(my_Beautifulsoup(result_house_tar_1[1]).find_all('p')[0].text),
my_strip(result_house_tar_1[2].text), my_strip(result_house_tar_1[3].text))
print(my_strip(result_house_tar_2[0].text), my_strip(result_house_tar_2[1].text),
my_strip(result_house_tar_2[2].text), my_strip(result_house_tar_2[3].text))
print(my_strip(result_house_tar_3[0].text), my_strip(result_house_tar_3[1].text),
my_strip(result_house_tar_3[2].text))
if __name__ == '__main__':
# url链接
url = 'https://zhengzhou.anjuke.com/sale/'
# 页面爬取函数调用
get_page(url)由于自己边写博客,边写的代码,所以get_page函数中进行了一些改变,就是下一页的递归调用需要放在函数后面,以及进行封装了两个函数没有介绍,
而且数据存储到mysql也没有写,所以后期会继续跟进的,thank you!!!
相关推荐:
Atas ialah kandungan terperinci python爬取安居客二手房网站数据方法分享. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bagaimana anda memotong senarai python?May 02, 2025 am 12:14 AM
Bagaimana anda memotong senarai python?May 02, 2025 am 12:14 AMSlicingapythonlistisdoneusingthesyntaxlist [Mula: berhenti: langkah] .here'showitworks: 1) startistheindexofthefirstelementtoinclude.2) stopistheindexofthefirstelementToexclude.3)
 Apakah beberapa operasi biasa yang boleh dilakukan pada array numpy?May 02, 2025 am 12:09 AM
Apakah beberapa operasi biasa yang boleh dilakukan pada array numpy?May 02, 2025 am 12:09 AMNumpyallowsforvariousoperationsonArrays: 1) BasicarithmeticLikeaddition, penolakan, pendaraban, danDivision; 2) Pengerjaan AdvancedSuchasmatrixmultiplication; 3) Element-WiseOperationswithoutExplicitLoops;
 Bagaimana tatasusunan digunakan dalam analisis data dengan python?May 02, 2025 am 12:09 AM
Bagaimana tatasusunan digunakan dalam analisis data dengan python?May 02, 2025 am 12:09 AMArraysinpython, terutamanya yang ada, adalah, penawaran yang ditawarkan.1) numpyarraysenableFandlingoflargedataSetsandClexPleperationsLikemovingAverages.2)
 Bagaimanakah jejak memori senarai dibandingkan dengan jejak memori array di Python?May 02, 2025 am 12:08 AM
Bagaimanakah jejak memori senarai dibandingkan dengan jejak memori array di Python?May 02, 2025 am 12:08 AMListsSandnumpyAraySInpythonHavedifferMememoryFootPrints: listsaremoreflexibleButlessMememory-cekap, pemanmak
 Bagaimana anda mengendalikan konfigurasi khusus persekitaran semasa menggunakan skrip python yang boleh dilaksanakan?May 02, 2025 am 12:07 AM
Bagaimana anda mengendalikan konfigurasi khusus persekitaran semasa menggunakan skrip python yang boleh dilaksanakan?May 02, 2025 am 12:07 AMToensurePythonscriptsbehaveCorrectlyCrossdevelopment, pementasan, dan produksi, usetheseStregies: 1) Environmentvariablesforsimplesettings, 2) ConfigurationFilesfilePlexSetups, dan3) Dynamicloadingforadaptability.EachMethodeFerPiReFiteReFiteShitsandReFitSandRiteFitSandRiteFitSandRiteFiteSandRiteReFitSandRiteReFitSandRiteFiteShiteSandReFiteShitsandReShitsAnfitsEts,
 Bagaimana anda memotong array python?May 01, 2025 am 12:18 AM
Bagaimana anda memotong array python?May 01, 2025 am 12:18 AMSintaks asas untuk pengirim senarai python adalah senarai [Mula: Berhenti: Langkah]. 1. Start adalah indeks elemen pertama yang disertakan, 2.Stop adalah indeks elemen pertama yang dikecualikan, dan 3. Step menentukan saiz langkah antara elemen. Hirisan tidak hanya digunakan untuk mengekstrak data, tetapi juga untuk mengubah suai dan membalikkan senarai.
 Di bawah keadaan apa yang mungkin senarai lebih baik daripada tatasusunan?May 01, 2025 am 12:06 AM
Di bawah keadaan apa yang mungkin senarai lebih baik daripada tatasusunan?May 01, 2025 am 12:06 AMListsOutPerFormAraySin: 1) DynamicsizingandFrequentInsertions/Deletions, 2) StoringHeterogeneousData, dan3) MemoryeficiencyForSparsedata, ButmayHaveslightPerformancecostSincertaor.
 Bagaimana anda boleh menukar array python ke senarai python?May 01, 2025 am 12:05 AM
Bagaimana anda boleh menukar array python ke senarai python?May 01, 2025 am 12:05 AMToConvertapythonarraytoalist, usethelist () constructororageneratorexpression.1) importTheArrayModuleAndCreateeanArray.2) uselist (arr) atau [xforxinarr] toConvertittoalist, urusanPengerasiPormanceAndMemoryeficiencyForlargedatasets.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

