


本文主要给大家讲解了一下用NodeJS学习爬虫,并通过爬糗事百科来讲解用法和效果,一起学习下吧,希望能帮助到大家。
1.前言分析
往常都是利用 Python/.NET 语言实现爬虫,然现在作为一名前端开发人员,自然需要熟练 NodeJS。下面利用 NodeJS 语言实现一个糗事百科的爬虫。另外,本文使用的部分代码是 es6 语法。
实现该爬虫所需要的依赖库如下。
request: 利用 get 或者 post 等方法获取网页的源码。 cheerio: 对网页源码进行解析,获取所需数据。
本文首先对爬虫所需依赖库及其使用进行介绍,然后利用这些依赖库,实现一个针对糗事百科的网络爬虫。
2. request 库
request 是一个轻量级的 http 库,功能十分强大且使用简单。可以使用它实现 Http 的请求,并且支持 HTTP 认证, 自定请求头等。下面对 request 库中一部分功能进行介绍。
安装 request 模块如下:
npm install request
在安装好 request 后,即可进行使用,下面利用 request 请求一下百度的网页。
const req = require('request');
req('http://www.baidu.com', (error, response, body) => {
if (!error && response.statusCode == 200) {
console.log(body)
}
})
在没有设置 options 参数时,request 方法默认是 get 请求。而我喜欢利用 request 对象的具体方法,使用如下:
req.get({
url: 'http://www.baidu.com'
},(err, res, body) => {
if (!err && res.statusCode == 200) {
console.log(body)
}
});
然而很多时候,直接去请求一个网址所获取的 html 源码,往往得不到我们需要的信息。一般情况下,需要考虑到请求头和网页编码。
网页的请求头网页的编码
下面介绍在请求的时候如何添加网页请求头以及设置正确的编码。
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36",
"Host" : "www.zhihu.com",
"Upgrade-Insecure-Requests" : "1"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(!err)
console.log(body);
})
设置 options 参数, 添加 headers 属性即可实现请求头的设置;添加 encoding 属性即可设置网页的编码。需要注意的是,若 encoding:null ,那么 get 请求所获取的内容则是一个 Buffer 对象,即 body 是一个 Buffer 对象。
上面介绍的功能足矣满足后面的所需了
3. cheerio 库
cheerio 是一款服务器端的 Jquery,以轻、快、简单易学等特点被开发者喜爱。有 Jquery 的基础后再来学习 cheerio 库非常轻松。它能够快速定位到网页中的元素,其规则和 Jquery 定位元素的方法是一样的;它也能以一种非常方便的形式修改 html 中的元素内容,以及获取它们的数据。下面主要针对 cheerio 快速定位网页中的元素,以及获取它们的内容进行介绍。
首先安装 cheerio 库
npm install cheerio
下面先给出一段代码,再对代码进行解释 cheerio 库的用法。对博客园首页进行分析,然后提取每一页中文章的标题。
首先对博客园首页进行分析。如下图:
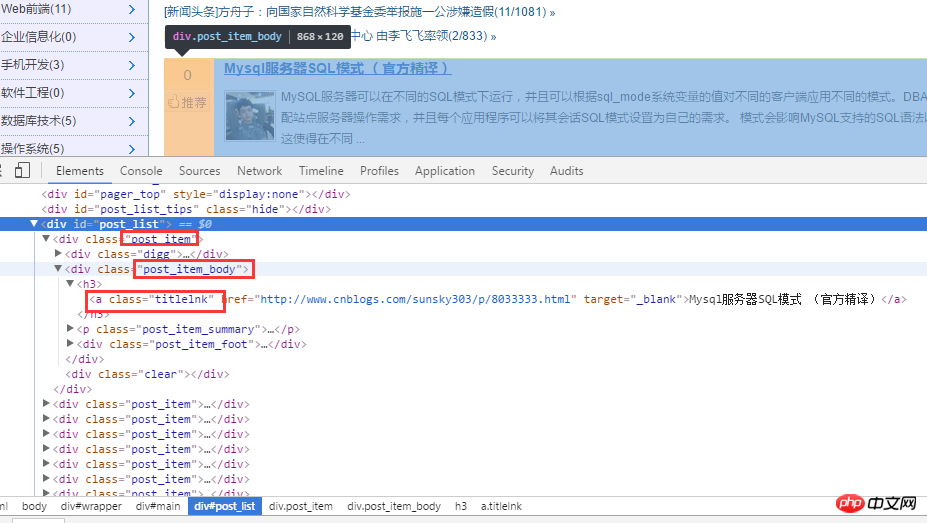
对 html 源代码进行分析后,首先通过 .post_item 获取所有标题,接着对每一个 .post_item 进行分析,使用 a.titlelnk 即可匹配每个标题的 a 标签。下面通过代码进行实现。
const req = require('request');
const cheerio = require('cheerio');
req.get({
url: 'https://www.cnblogs.com/'
}, (err, res, body) => {
if (!err && res.statusCode == 200) {
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
$('.post_item').each((index, ele) => {
let title = $(ele).find('a.titlelnk');
let titleText = title.text();
let titletUrl = title.attr('href');
console.log(titleText, titletUrl);
});
}
});
当然,cheerio 库也支持链式调用,上面的代码也可改写成:
let cnblogHtmlStr = body;
let $ = cheerio.load(cnblogHtmlStr);
let titles = $('.post_item').find('a.titlelnk');
titles.each((index, ele) => {
let titleText = $(ele).text();
let titletUrl = $(ele).attr('href');
console.log(titleText, titletUrl);
上面的代码非常简单,就不再用文字进行赘述了。下面总结一点自己认为比较重要的几点。
使用 find() 方法获取的节点集合 A,若再次以 A 集合中的元素为根节点定位它的子节点以及获取子元素的内容与属性,需对 A 集合中的子元素进行 $(A[i]) 包装,如上面的$(ele) 一样。在上面代码中使用 $(ele) ,其实还可以使用 $(this) 但是由于我使用的是 es6 的箭头函数,因此改变了 each 方法中回调函数的 this 指针,因此,我使用 $(ele); cheerio 库也支持链式调用,如上面的 $('.post_item').find('a.titlelnk') ,需要注意的是,cheerio 对象 A 调用方法 find(),如果 A 是一个集合,那么 A 集合中的每一个子元素都调用 find() 方法,并放回一个结果结合。如果 A 调用 text() ,那么 A 集合中的每一个子元素都调用 text() 并返回一个字符串,该字符串是所有子元素内容的合并(直接合并,没有分隔符)。
最后在总结一些我比较常用的方法。
first() last() children([selector]): 该方法和 find 类似,只不过该方法只搜索子节点,而 find 搜索整个后代节点。
4. 糗事百科爬虫
通过上面对 request 和 cheerio 类库的介绍,下面利用这两个类库对糗事百科的页面进行爬取。
1、在项目目录中,新建 httpHelper.js 文件,通过 url 获取糗事百科的网页源码,代码如下:
//爬虫
const req = require('request');
function getHtml(url){
return new Promise((resolve, reject) => {
req.get({
url : url,
headers: {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Referer" : "https://www.qiushibaike.com/"
},
encoding : 'utf-8'
}, (err, res, body)=>{
if(err) reject(err);
else resolve(body);
})
});
}
exports.getHtml = getHtml;
2、在项目目录中,新建一个 Splider.js 文件,分析糗事百科的网页代码,提取自己需要的信息,并且建立一个逻辑通过更改 url 的 id 来爬取不同页面的数据。
const cheerio = require('cheerio');
const httpHelper = require('./httpHelper');
function getQBJok(htmlStr){
let $ = cheerio.load(htmlStr);
let jokList = $('#content-left').children('p');
let rst = [];
jokList.each((i, item)=>{
let node = $(item);
let titleNode = node.find('h2');
let title = titleNode ? titleNode.text().trim() : '匿名用户';
let content = node.find('.content span').text().trim();
let likeNumber = node.find('i[class=number]').text().trim();
rst.push({
title : title,
content : content,
likeNumber : likeNumber
});
});
return rst;
}
async function splider(index = 1){
let url = `https://www.qiushibaike.com/8hr/page/${index}/`;
let htmlStr = await httpHelper.getHtml(url);
let rst = getQBJok(htmlStr);
return rst;
}
splider(1);
在获取糗事百科网页信息的时候,首先在浏览器中对源码进行分析,定位到自己所需要标签,然后提取标签的文本或者属性值,这样就完成了网页的解析。
Splider.js 文件入口是 splider 方法,首先根据传入该方法的 index 索引,构造糗事百科的 url,接着获取该 url 的网页源码,最后将获取的源码传入 getQBJok 方法,进行解析,本文只解析每条文本笑话的作者、内容以及喜欢个数。
直接运行 Splider.js 文件,即可爬取第一页的笑话信息。然后可以更改 splider 方法的参数,实现抓取不同页面的信息。
在上面已有代码的基础上,使用 koa 和 vue2.0 搭建一个浏览文本的页面,效果如下:

源码已上传到 github 上。下载地址:https://github.com/StartAction/SpliderQB ;
项目运行依赖 node v7.6.0 以上, 首先从 Github 上面克隆整个项目。
git clone https://github.com/StartAction/SpliderQB.git
克隆之后,进入项目目录,运行下面命令即可。
node app.js
5. 总结
通过实现一个完整的爬虫功能,加深自己对 Node 的理解,且实现的部分语言都是使用 es6 的语法,让自己加快对 es6 语法的学习进度。另外,在这次实现中,遇到了 Node 的异步控制的知识,本文是采用的是 async 和 await 关键字,也是我最喜欢的一种,然而在 Node 中,实现异步控制有好几种方式。关于具体的方式以及原理,有时间再进行总结。
相关推荐:
Atas ialah kandungan terperinci NodeJS糗事百科爬虫实例教程. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 JavaScript dan Web: Fungsi teras dan kes penggunaanApr 18, 2025 am 12:19 AM
JavaScript dan Web: Fungsi teras dan kes penggunaanApr 18, 2025 am 12:19 AMPenggunaan utama JavaScript dalam pembangunan web termasuk interaksi klien, pengesahan bentuk dan komunikasi tak segerak. 1) kemas kini kandungan dinamik dan interaksi pengguna melalui operasi DOM; 2) pengesahan pelanggan dijalankan sebelum pengguna mengemukakan data untuk meningkatkan pengalaman pengguna; 3) Komunikasi yang tidak bersesuaian dengan pelayan dicapai melalui teknologi Ajax.
 Memahami Enjin JavaScript: Butiran PelaksanaanApr 17, 2025 am 12:05 AM
Memahami Enjin JavaScript: Butiran PelaksanaanApr 17, 2025 am 12:05 AMMemahami bagaimana enjin JavaScript berfungsi secara dalaman adalah penting kepada pemaju kerana ia membantu menulis kod yang lebih cekap dan memahami kesesakan prestasi dan strategi pengoptimuman. 1) aliran kerja enjin termasuk tiga peringkat: parsing, penyusun dan pelaksanaan; 2) Semasa proses pelaksanaan, enjin akan melakukan pengoptimuman dinamik, seperti cache dalam talian dan kelas tersembunyi; 3) Amalan terbaik termasuk mengelakkan pembolehubah global, mengoptimumkan gelung, menggunakan const dan membiarkan, dan mengelakkan penggunaan penutupan yang berlebihan.
 Python vs JavaScript: Keluk Pembelajaran dan Kemudahan PenggunaanApr 16, 2025 am 12:12 AM
Python vs JavaScript: Keluk Pembelajaran dan Kemudahan PenggunaanApr 16, 2025 am 12:12 AMPython lebih sesuai untuk pemula, dengan lengkung pembelajaran yang lancar dan sintaks ringkas; JavaScript sesuai untuk pembangunan front-end, dengan lengkung pembelajaran yang curam dan sintaks yang fleksibel. 1. Sintaks Python adalah intuitif dan sesuai untuk sains data dan pembangunan back-end. 2. JavaScript adalah fleksibel dan digunakan secara meluas dalam pengaturcaraan depan dan pelayan.
 Python vs JavaScript: Komuniti, Perpustakaan, dan SumberApr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan SumberApr 15, 2025 am 12:16 AMPython dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Dari C/C ke JavaScript: Bagaimana semuanya berfungsiApr 14, 2025 am 12:05 AM
Dari C/C ke JavaScript: Bagaimana semuanya berfungsiApr 14, 2025 am 12:05 AMPeralihan dari C/C ke JavaScript memerlukan menyesuaikan diri dengan menaip dinamik, pengumpulan sampah dan pengaturcaraan asynchronous. 1) C/C adalah bahasa yang ditaip secara statik yang memerlukan pengurusan memori manual, manakala JavaScript ditaip secara dinamik dan pengumpulan sampah diproses secara automatik. 2) C/C perlu dikumpulkan ke dalam kod mesin, manakala JavaScript adalah bahasa yang ditafsirkan. 3) JavaScript memperkenalkan konsep seperti penutupan, rantaian prototaip dan janji, yang meningkatkan keupayaan pengaturcaraan fleksibiliti dan asynchronous.
 Enjin JavaScript: Membandingkan PelaksanaanApr 13, 2025 am 12:05 AM
Enjin JavaScript: Membandingkan PelaksanaanApr 13, 2025 am 12:05 AMEnjin JavaScript yang berbeza mempunyai kesan yang berbeza apabila menguraikan dan melaksanakan kod JavaScript, kerana prinsip pelaksanaan dan strategi pengoptimuman setiap enjin berbeza. 1. Analisis leksikal: Menukar kod sumber ke dalam unit leksikal. 2. Analisis Tatabahasa: Menjana pokok sintaks abstrak. 3. Pengoptimuman dan Penyusunan: Menjana kod mesin melalui pengkompil JIT. 4. Jalankan: Jalankan kod mesin. Enjin V8 mengoptimumkan melalui kompilasi segera dan kelas tersembunyi, Spidermonkey menggunakan sistem kesimpulan jenis, menghasilkan prestasi prestasi yang berbeza pada kod yang sama.
 Beyond the Browser: JavaScript di dunia nyataApr 12, 2025 am 12:06 AM
Beyond the Browser: JavaScript di dunia nyataApr 12, 2025 am 12:06 AMAplikasi JavaScript di dunia nyata termasuk pengaturcaraan sisi pelayan, pembangunan aplikasi mudah alih dan Internet of Things Control: 1. Pengaturcaraan sisi pelayan direalisasikan melalui node.js, sesuai untuk pemprosesan permintaan serentak yang tinggi. 2. Pembangunan aplikasi mudah alih dijalankan melalui reaktnatif dan menyokong penggunaan silang platform. 3. Digunakan untuk kawalan peranti IoT melalui Perpustakaan Johnny-Five, sesuai untuk interaksi perkakasan.
 Membina aplikasi SaaS Multi-penyewa dengan Next.js (Integrasi Backend)Apr 11, 2025 am 08:23 AM
Membina aplikasi SaaS Multi-penyewa dengan Next.js (Integrasi Backend)Apr 11, 2025 am 08:23 AMSaya membina aplikasi SaaS multi-penyewa berfungsi (aplikasi edTech) dengan alat teknologi harian anda dan anda boleh melakukan perkara yang sama. Pertama, apakah aplikasi SaaS multi-penyewa? Aplikasi SaaS Multi-penyewa membolehkan anda melayani beberapa pelanggan dari Sing


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

