


假如有一段文本,你只想匹配最短的可能,而不是最长。本文就主要给大家介绍了关于正则表达式中最短匹配模式用法的相关资料。
前言
最近有一次想用正则表达式从网页里面抓取一些东西出来,内容不复杂却出现不少问题。下面话不多说,来一起看看详细的介绍:
当我们用正则表达式去匹配一个标签的首尾的时候,比如匹配 4a249f0d628e2318394fd9b75b4636b1hello world473f0a7621bec819994bb5020d29372a 中的 h1 的开始和闭合标签
可能很多人会这样写
/<.*h1>/g
但是这样真的可以吗?
因为 * 匹配符是匹配前面一个字符的零到多个,而且它是贪婪匹配的
所以你得到的就会是下面的结果了。
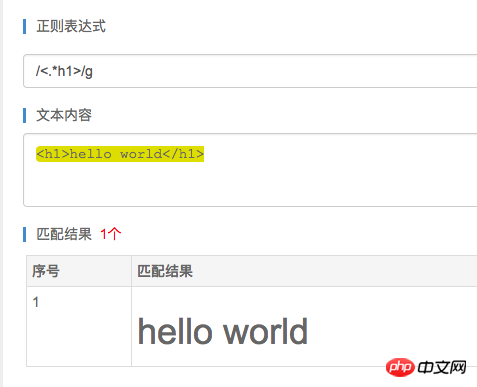
显然这并不是我们想要的,那么怎么把贪婪匹配换成最小匹配呢,
/<.*?h1>/g
上面的写法就可以了,如下图:
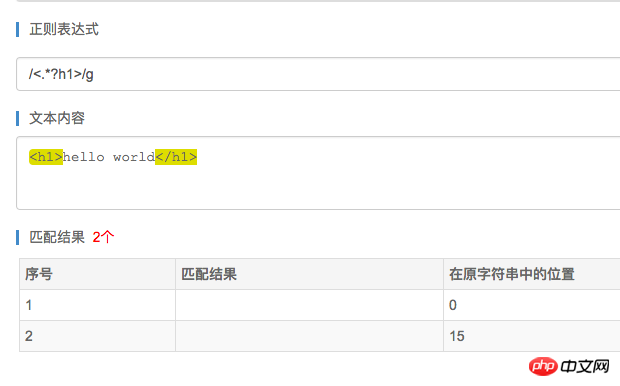
其实原理应该很简单,因为 ? 也是贪婪匹配,并且只能匹配0到1个,
所以它会匹配到第一个的时候就结束了,从而阻止了 * 的匹配多个的贪婪。
以上内容就是正则表达式中最短匹配模式的用法,希望能帮助到大家。
相关推荐:
Atas ialah kandungan terperinci 正则表达式中最短匹配模式的用法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Cara membuat aplikasi php lebih cepatMay 12, 2025 am 12:12 AM
Cara membuat aplikasi php lebih cepatMay 12, 2025 am 12:12 AMTomakephpapplicationsfaster, ikutiTheseSteps: 1) UseopcodecachinglikeopcachetostorePrecompiledscriptbytecode.2) minimizedatabasequeriesbyusingquerycachingandeficientindexing.3)
 Senarai Semak Pengoptimuman Prestasi PHP: Meningkatkan Kelajuan SekarangMay 12, 2025 am 12:07 AM
Senarai Semak Pengoptimuman Prestasi PHP: Meningkatkan Kelajuan SekarangMay 12, 2025 am 12:07 AMToimprovePhpapPlicationspeed, ikutiTheSesteps: 1) EnableopCodeCachingWithApcutoreduceScriptExecutionTime.2) pelaksanaanDatabasequerycachingingPdotominimizedataBaseHits.3)
 Suntikan Ketergantungan PHP: Meningkatkan kebolehlaksanaan kodMay 12, 2025 am 12:03 AM
Suntikan Ketergantungan PHP: Meningkatkan kebolehlaksanaan kodMay 12, 2025 am 12:03 AMSuntikan ketergantungan (DI) dengan ketara meningkatkan kesesuaian kod PHP oleh kebergantungan transitif secara eksplisit. 1) Kelas Decoupling dan pelaksanaan khusus menjadikan ujian dan penyelenggaraan lebih fleksibel. 2) Di antara tiga jenis, pembina menyuntik kebergantungan ekspresi eksplisit untuk memastikan keadaan konsisten. 3) Gunakan bekas DI untuk menguruskan kebergantungan kompleks untuk meningkatkan kualiti kod dan kecekapan pembangunan.
 Pengoptimuman Prestasi PHP: Pengoptimuman Pertanyaan Pangkalan DataMay 12, 2025 am 12:02 AM
Pengoptimuman Prestasi PHP: Pengoptimuman Pertanyaan Pangkalan DataMay 12, 2025 am 12:02 AMDatabaseQueryoptimizationInpinvolvesseverSlegatiesToenhancePratePratePratePratePratePregiesToRperformance.1) selectOnlynessaryColumnStoReducedatatatransfer.2) UseIndexingTospeedupdatareTrieval.3) PrevancequerycachingToStoreresultSoffReFfeFfffffffffffffffffffffffffffffffffffffffffffferseprewfffffffffffersepresseprespersepresperseprespersepresperseprespersepresperseprespers
 Panduan Mudah: Menghantar E -mel dengan Skrip PHPMay 12, 2025 am 12:02 AM
Panduan Mudah: Menghantar E -mel dengan Skrip PHPMay 12, 2025 am 12:02 AMPhpisusedforsendingemailsduetoitsbuilt-inmail () functionAndSupportivelibrariesLikePhpmailerandswiftmailer.1) usethemail () functionforbasiceMails, butithaslimitations.2) scorkphpmailerforadvancedfeatures
 Prestasi PHP: Mengenalpasti dan menetapkan kesesakanMay 11, 2025 am 12:13 AM
Prestasi PHP: Mengenalpasti dan menetapkan kesesakanMay 11, 2025 am 12:13 AMKesesakan prestasi PHP boleh diselesaikan melalui langkah -langkah berikut: 1) Gunakan XDEBUG atau Blackfire untuk analisis prestasi untuk mengetahui masalah; 2) Mengoptimumkan pertanyaan pangkalan data dan menggunakan cache, seperti APCU; 3) Gunakan fungsi yang cekap seperti array_filter untuk mengoptimumkan operasi array; 4) Konfigurasi Opcache untuk cache bytecode; 5) mengoptimumkan bahagian depan, seperti mengurangkan permintaan HTTP dan mengoptimumkan gambar; 6) Memantau dan mengoptimumkan prestasi secara berterusan. Melalui kaedah ini, prestasi aplikasi PHP dapat ditingkatkan dengan ketara.
 Suntikan Ketergantungan untuk PHP: Ringkasan CepatMay 11, 2025 am 12:09 AM
Suntikan Ketergantungan untuk PHP: Ringkasan CepatMay 11, 2025 am 12:09 AMDependencyInjection (DI) inphpisadesignPatternThatManagesandReducesclassdependencies, enhancingcodemodularity, testility, andmaintainability.itallowspassingdependenciesLikedatabaseconnectionstoclassesesparameters, fasilitasieAseAsiShanandscalability.
 Meningkatkan Prestasi PHP: Strategi & Teknik CachingMay 11, 2025 am 12:08 AM
Meningkatkan Prestasi PHP: Strategi & Teknik CachingMay 11, 2025 am 12:08 AMCachingimprovesphpperformanceSbebyStoringResultsofcomputationsorqueriesforquickretrieval, reducingserverloadandenhancingResponsetimes.effectiveStRegiesClude: 1) Opcodecaching, yang


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Dreamweaver CS6
Alat pembangunan web visual

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

Dreamweaver Mac版
Alat pembangunan web visual

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

