
Rumah >hujung hadapan web >tutorial js >js实现数据结构: 树和二叉树,二叉树的遍历和基本操作方法
js实现数据结构: 树和二叉树,二叉树的遍历和基本操作方法
- 一个新手asal
- 2017-09-22 09:55:012118semak imbas
树型结构是一类非常重要的非线性结构。直观地,树型结构是以分支关系定义的层次结构。
树在计算机领域中也有着广泛的应用,例如在编译程序中,用树来表示源程序的语法结构;在数据库系统中,可用树来组织信息;在分析算法的行为时,可用树来描述其执行过程等等
首先看看树的一些概念:1.树(Tree)是n(n>=0)个结点的有限集。在任意一棵非空树中:
(1)有且仅有一个特定的称为根(Root)的结点;
(2)当n>1时,其余结点可分为m(m>0)个互不相交的有限集T1,T2,T3,…Tm,其中每一个集合本身又是一棵树,并且称为根的子树(Subtree)。
例如,(a)是只有一个根结点的树;(b)是有13个结点的树,其中A是根,其余结点分成3个互不相交的子集:T1={B,E,F,K,L},t2={D,H,I,J,M};T1,T2和T3都是根A的子树,且本身也是一棵树。 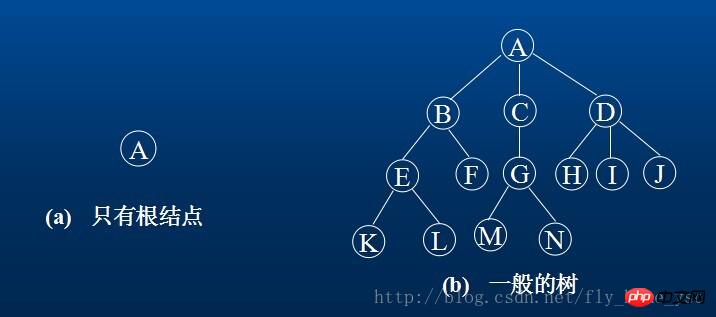
2.树的结点包含一个数据元素及若干指向其子树的分支。结点拥有的子树数称为结点的度(Degree)。例如,(b)中A的度为3,C的度为1,F的度为0.度为0的结点称为叶子(Leaf)或者终端结点。度不为0的结点称为非终端结点或分支结点。树的度是树内各结点的度的最大值。(b)的树的度为3.结点的子树的根称为该结点的孩子(Child)。相应的,该结点称为孩子的双亲(Parent)。同一个双亲的孩子之间互称兄弟(Sibling)。结点的祖先是从根到该结点所经分支上的所有结点。反之,以某结点为根的子树中的任一结点都称为该结点的子孙。
3.结点的层次(Level)从根开始定义起,根为第一层,跟的孩子为第二层。若某结点在第l层,则其子树的根就在第l+1层。其双亲在同一层的结点互为堂兄弟。例如,结点G与E,F,H,I,J互为堂兄弟。树中结点的最大层次称为树的深度(Depth)或高度。(b)的树的深度为4。
4.如果将树中结点的各子树看成从左至右是有次序的(即不能交换),则称该树为有序树,否则称为无序树。在有序树中最左边的子树的根称为第一个孩子,最右边的称为最后一个孩子。
5.森林(Forest)是m(m>=0)棵互不相交的树的集合。对树中每个结点而言,其子树的集合即为森林。
接下来看看二叉树相关的概念:
二叉树(Binary Tree)是另一种树型结构,它的特点是每个结点至多只有两棵子树(即二叉树中不存在度大于2的结点),并且,二叉树的子树有左右之分(其次序不能任意颠倒。)
二叉树的性质:
1.在二叉树的第i层上至多有2的i-1次方个结点(i>=1)。
2.深度为k的二叉树至多有2的k次方-1个结点,(k>=1)。
3.对任何一棵二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0 = n2 + 1;
一棵深度为k且有2的k次方-1个结点的二叉树称为满二叉树。
深度为k的,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应时,称之为完全二叉树。
下面是完全二叉树的两个特性:
4.具有n个结点的完全二叉树的深度为Math.floor(log 2 n) + 1
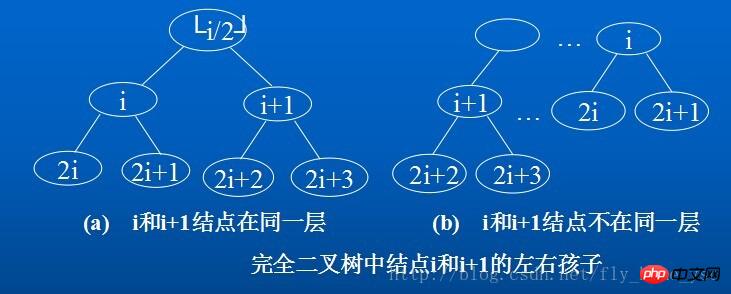
5.如果对一棵有n个结点的完全二叉树(其深度为Math.floor(log 2 n) + 1)的结点按层序编号(从第1层到第Math.floor(2 n) + 1,每层从左到右),则对任一结点(1197196a2badc70a6d62dc9ded43c285c1,则其双亲parent(i)是结点Math.floor(i/2)。
(2)如果2i > n,则结点i无左孩子(结点i为叶子结点);否则其左孩子LChild(i)是结点2i.
(3)如果2i + 1 > n,则结点i无右孩子;否则其右孩子RChild(i)是结点2i + 1; 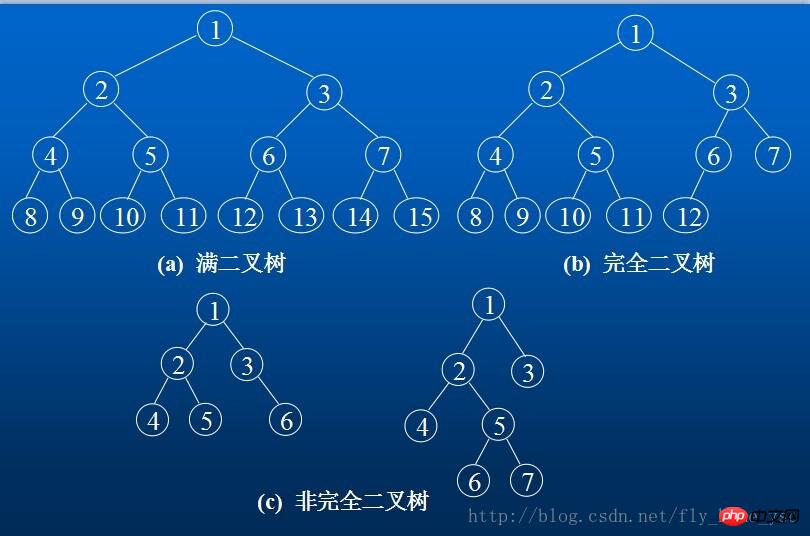
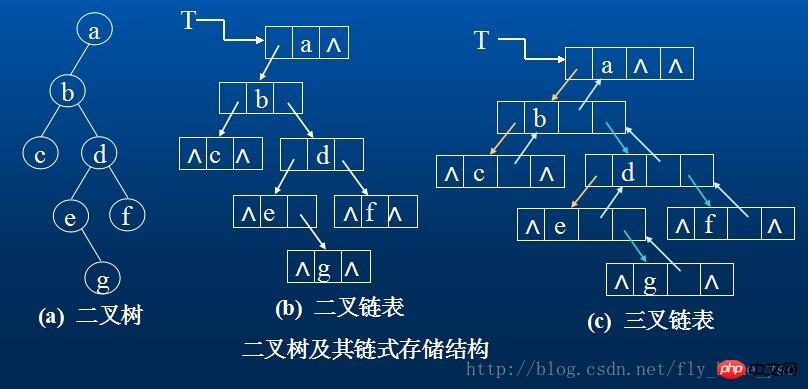
二叉树的存储结构
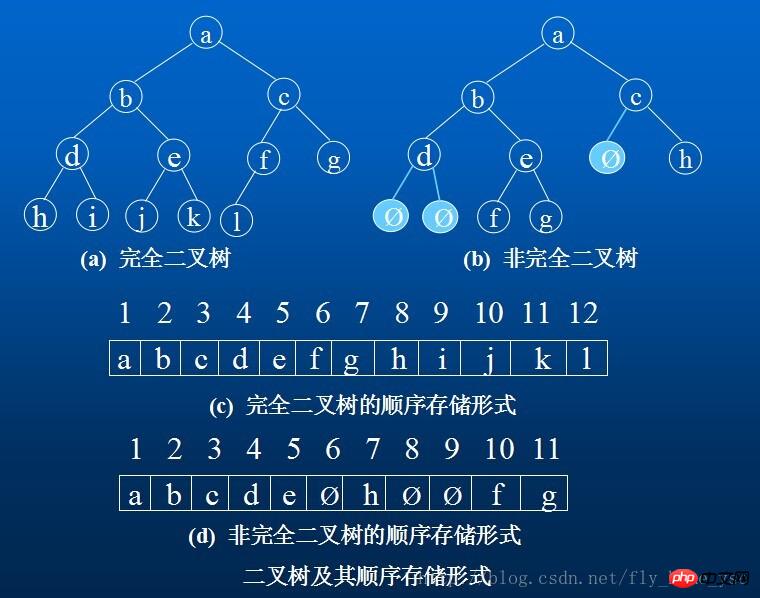
1.顺序存储结构
用一组连续的存储单元依次自上而下,自左至右存储完全二叉树上的结点元素,即将二叉树上编号为i的结点元素存储在加上定义的一维数组中下标为i-1的分量中。“0”表示不存在此结点。这种顺序存储结构仅适用于完全二叉树。
因为,在最坏情况下,一个深度为k且只有k个结点的单支树(树中不存在度为2的结点)却需要长度为2的n次方-1的一维数组。
2.链式存储结构
二叉树的结点由一个数据元素和分别指向其左右子树的两个分支构成,则表示二叉树的链表中的结点至少包含三个域:数据域和左右指针域。有时,为了便于找到结点的双亲,则还可在结点结构中增加一个指向其双亲结点的指针域。利用这两种结构所得的二叉树的存储结构分别称之为二叉链表和三叉链表。
在含有n个结点的二叉链表中有n+1个空链域,我们可以利用这些空链域存储其他有用信息,从而得到另一种链式存储结构—线索链表。
二叉树的遍历主要分三种:
先(根)序遍历:根左右
中(根)序遍历:左根右
后(根)序遍历:左右根
二叉树的顺序存储结构:
二叉树的链式存储形式:
// 顺序存储结构
var tree = [1, 2, 3, 4, 5, , 6, , , 7];
// 链式存储结构
function BinaryTree(data, leftChild, rightChild) {
this.data = data || null;
// 左右孩子结点
this.leftChild = leftChild || null;
this.rightChild = rightChild || null;
}遍历二叉树(Traversing Binary Tree):是指按指定的规律对二叉树中的每个结点访问一次且仅访问一次。
1.先序遍历二叉树
1)算法的递归定义是:
若二叉树为空,则遍历结束;否则
⑴ 访问根结点;
⑵ 先序遍历左子树(递归调用本算法);
⑶ 先序遍历右子树(递归调用本算法)。
算法实现:
// 顺序存储结构的递归先序遍历
var tree = [1, 2, 3, 4, 5, , 6, , , 7]; console.log('preOrder:');
void function preOrderTraverse(x, visit) {
visit(tree[x]);
if (tree[2 * x + 1]) preOrderTraverse(2 * x + 1, visit);
if (tree[2 * x + 2]) preOrderTraverse(2 * x + 2, visit);
}(0, function (value) {
console.log(value);
});
// 链式存储结构的递归先序遍历
BinaryTree.prototype.preOrderTraverse = function preOrderTraverse(visit) {
visit(this.data);
if (this.leftChild) preOrderTraverse.call(this.leftChild, visit);
if (this.rightChild) preOrderTraverse.call(this.rightChild, visit);
};2)非递归算法:
设T是指向二叉树根结点的变量,非递归算法是: 若二叉树为空,则返回;否则,令p=T;
(1) p为根结点;
(2) 若p不为空或者栈不为空;
(3) 若p不为空,访问p所指向的结点, p进栈, p = p.leftChild,访问左子树;
(4) 否则;退栈到p,然后p = p.rightChild, 访问右子树
(5) 转(2),直到栈空为止。
代码实现:
// 链式存储的非递归先序遍历
// 方法1
BinaryTree.prototype.preOrder_stack = function (visit) {
var stack = new Stack();
stack.push(this);
while (stack.top) {
var p; // 向左走到尽头
while ((p = stack.peek())) {
p.data && visit(p.data);
stack.push(p.leftChild);
}
stack.pop();
if (stack.top) {
p = stack.pop();
stack.push(p.rightChild);
}
}
}; // 方法2
BinaryTree.prototype.preOrder_stack2 = function (visit) {
var stack = new Stack();
var p = this;
while (p || stack.top) {
if (p) {
stack.push(p);
p.data && visit(p.data);
p = p.leftChild;
} else {
p = stack.pop();
p = p.rightChild;
}
}
};2.中序遍历二叉树:
1)算法的递归定义是:
若二叉树为空,则遍历结束;否则
⑴ 中序遍历左子树(递归调用本算法);
⑵ 访问根结点;
⑶ 中序遍历右子树(递归调用本算法)。
// 顺序存储结构的递归中序遍历
var tree = [1, 2, 3, 4, 5, , 6, , , 7];
console.log('inOrder:');
void function inOrderTraverse(x, visit) {
if (tree[2 * x + 1]) inOrderTraverse(2 * x + 1, visit);
visit(tree[x]);
if (tree[2 * x + 2]) inOrderTraverse(2 * x + 2, visit);
}(0, function (value) {
console.log(value);
});
// 链式存储的递归中序遍历
BinaryTree.prototype.inPrderTraverse = function inPrderTraverse(visit) {
if (this.leftChild) inPrderTraverse.call(this.leftChild, visit);
visit(this.data);
if (this.rightChild) inPrderTraverse.call(this.rightChild, visit);
};2) 非递归算法
T是指向二叉树根结点的变量,非递归算法是: 若二叉树为空,则返回;否则,令p=T
⑴ 若p不为空,p进栈, p=p.leftChild ;
<br/>
⑵ 否则(即p为空),退栈到p,访问p所指向的结点,p=p.rightChild ;
⑶ 转(1);
直到栈空为止。
// 方法1
inOrder_stack1: function (visit) {
var stack = new Stack();
stack.push(this);
while (stack.top) {
var p; // 向左走到尽头
while ((p = stack.peek())) {
stack.push(p.leftChild);
}
stack.pop();
if (stack.top) {
p = stack.pop();
p.data && visit(p.data);
stack.push(p.rightChild);
}
}
}, // 方法2
inOrder_stack2: function (visit) {
var stack = new Stack();
var p = this;
while (p || stack.top) {
if (p) {
stack.push(p);
p = p.leftChild;
} else {
p = stack.pop();
p.data && visit(p.data);
p = p.rightChild;
}
}
},3.后序遍历二叉树:
1)递归算法
若二叉树为空,则遍历结束;否则
⑴ 后序遍历左子树(递归调用本算法);
⑵ 后序遍历右子树(递归调用本算法) ;
⑶ 访问根结点 。
// 顺序存储结构的递归后序遍历
var tree = [1, 2, 3, 4, 5, , 6, , , 7];
console.log('postOrder:');
void function postOrderTraverse(x, visit) {
if (tree[2 * x + 1]) postOrderTraverse(2 * x + 1, visit);
if (tree[2 * x + 2]) postOrderTraverse(2 * x + 2, visit);
visit(tree[x]);
}(0, function (value) {
console.log(value);
});
// 链式存储的递归后序遍历
BinaryTree.prototype.postOrderTraverse = function postOrderTraverse(visit) {
if (this.leftChild) postOrderTraverse.call(this.leftChild, visit);
if (this.rightChild) postOrderTraverse.call(this.rightChild, visit);
visit(this.data);
};2) 非递归算法
在后序遍历中,根结点是最后被访问的。因此,在遍历过程中,当搜索指针指向某一根结点时,不能立即访问,而要先遍历其左子树,此时根结点进栈。当其左子树遍历完后再搜索到该根结点时,还是不能访问,还需遍历其右子树。所以,此根结点还需再次进栈,当其右子树遍历完后再退栈到到该根结点时,才能被访问。 因此,设立一个状态标志变量mark:
mark=0表示刚刚访问此结点,mark=1表示左子树处理结束返回,
mark=2表示右子树处理结束返回。每次根据栈顶的mark域决定做何动作
算法实现思路:
(1) 根结点入栈,且mark = 0;
(2) 若栈不为空,出栈到node;
(3) 若node的mark = 0,修改当前node的mark为1,左子树入栈;
(4) 若node的mark = 1,修改当前node的mark为2,右子树入栈;
(5) 若node的mark = 2,访问当前node结点的值;
(6) 直到栈为空结束。
postOrder_stack: function (visit) {
var stack = new Stack();
stack.push([this, 0]);
while (stack.top) {
var a = stack.pop();
var node = a[0];
switch (a[1]) {
case 0:
stack.push([node, 1]); // 修改mark域
if (node.leftChild) stack.push([node.leftChild, 0]); // 访问左子树
break;
case 1:
stack.push([node, 2]);
if (node.rightChild) stack.push([node.rightChild, 0]);
break;
case 2:
node.data && visit(node.data);
break;
default:
break;
}
}
}具体的一个例子
<html>
<head>
<meta charset="utf-8">
<title>文档标题</title>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" />
<meta name="renderer" content="webkit">
<meta name="keywords" content="your keywords">
<meta name="description" content="your description">
<link rel="shortcut icon" type="image/ico" href="/favicon.ico" />
<meta name="viewport" content="width=device-width, initial-scale=1.0"></head><body>
<p class="container"></p>
<script>
// 顺序存储结构
(function () {
// 顺序存储结构的遍历
var tree = ["a","b","c","d","e","f","g"];
console.log('preOrder:');
+function preOrderTraverse(x, visit) {
visit(tree[x]);
if (tree[2 * x + 1]) preOrderTraverse(2 * x + 1, visit);
if (tree[2 * x + 2]) preOrderTraverse(2 * x + 2, visit);
}(0, function (value) {
console.log(value);
});
console.log('inOrder:');
void function inOrderTraverse(x, visit) {
if (tree[2 * x + 1]) inOrderTraverse(2 * x + 1, visit);
visit(tree[x]);
if (tree[2 * x + 2]) inOrderTraverse(2 * x + 2, visit);
}(0, function (value) {
console.log(value);
});
console.log('postOrder:');
void function postOrderTraverse(x, visit) {
if (tree[2 * x + 1]) postOrderTraverse(2 * x + 1, visit);
if (tree[2 * x + 2]) postOrderTraverse(2 * x + 2, visit);
visit(tree[x]);
}(0, function (value) {
console.log(value);
});
}()); // 求从tree到node结点路径的递归算法
function findPath(tree, node, path, i) {
var found = false;
void function recurse(tree, i) {
if (tree == node) {
found = true;
return;
}
path[i] = tree;
if (tree.leftChild) recurse(tree.leftChild, i + 1);
if (tree.rightChild && !found) recurse(tree.rightChild, i + 1);
if (!found) path[i] = null;
}(tree, i);
} var global = Function('return this;')();
</script>
</body>
</html>Atas ialah kandungan terperinci js实现数据结构: 树和二叉树,二叉树的遍历和基本操作方法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Analisis mendalam bagi komponen kumpulan senarai Bootstrap
- Penjelasan terperinci tentang fungsi JavaScript kari
- Contoh lengkap penjanaan kata laluan JS dan pengesanan kekuatan (dengan muat turun kod sumber demo)
- Angularjs menyepadukan UI WeChat (weui)
- Cara cepat bertukar antara Cina Tradisional dan Cina Ringkas dengan JavaScript dan helah untuk tapak web menyokong pertukaran antara kemahiran_javascript Cina Ringkas dan Tradisional