


php-ml是一个使用PHP编写的机器学习库。虽然我们知道,python或者是C++提供了更多机器学习的库,但实际上,他们大多都略显复杂,配置起来让很多新手感到绝望。php-ml这个机器学习库虽然没有特别高大上的算法,但其具有最基本的机器学习、分类等算法,我们的小公司做一些简单的数据分析、预测等等都是够用的。我们的项目中,追求的应该是性价比,而不是过分的效率和精度。一些算法和库看上去非常厉害,但如果我们考虑快速上线,而我们的技术人员没有机器学习方面的经验,那么复杂的代码和配置反而会拖累我们的项目。而如果我们本身就是做一个简单的机器学习应用,那么研究复杂库和算法的学习成本很显然高了点,而且,项目出了奇奇怪怪的问题,我们能解决吗?需求改变了怎么办?相信大家都有过这种经历:做着做着,程序忽然报错,自己怎么都搞不清楚原因,上谷歌或百度一搜,只搜出一条满足条件的问题,在五年、十年前提问,然后零回复。。。所以,选择最简单最高效、性价比最高的做法是必须的。php-ml的速度不算慢(赶紧换php7吧),而且精度也不错,毕竟算法都一样,而且php是基于c的。博主最看不惯的就是,拿python和Java,PHP之间比性能,比适用范围。真要性能,请你拿C开发。真要追求适用范围,也请用C,甚至汇编。。。
首先,我们要使用这个库,需要先下载这个库。在github可以下载到这个库文件(https://github.com/php-ai/php-ml)。当然,更推荐使用composer来下载该库,自动配置。
当下载好了以后,我们可以看一看这个库的文档,文档都是一些简单的小示例,我们可以自己建一个文件尝试一下。都浅显易懂。接下来,我们来拿实际的数据测试一下。数据集一个是Iris花蕊的数据集,另一个由于记录丢失,所以不知道是有关什么的数据了。。。
Iris花蕊部分数据,有三种不同的分类:
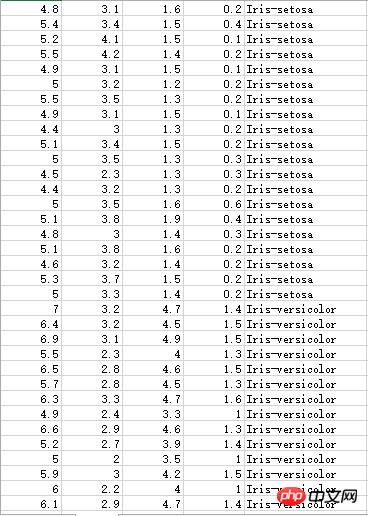
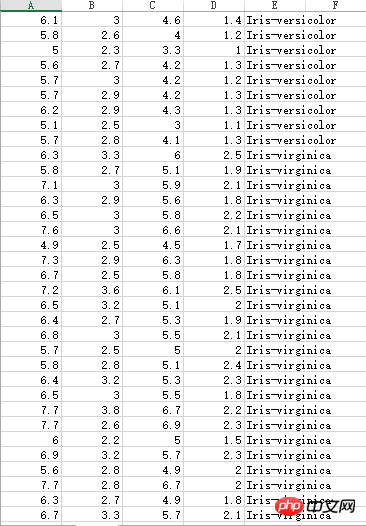
不知名数据集,小数点被打成了逗号,所以计算时还需要处理一下:

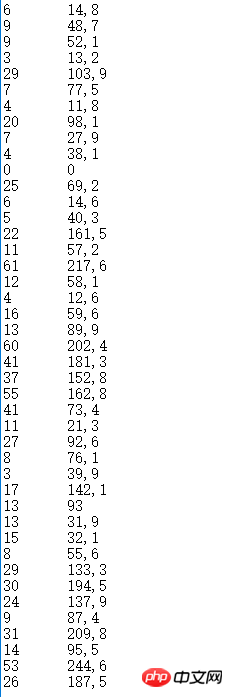
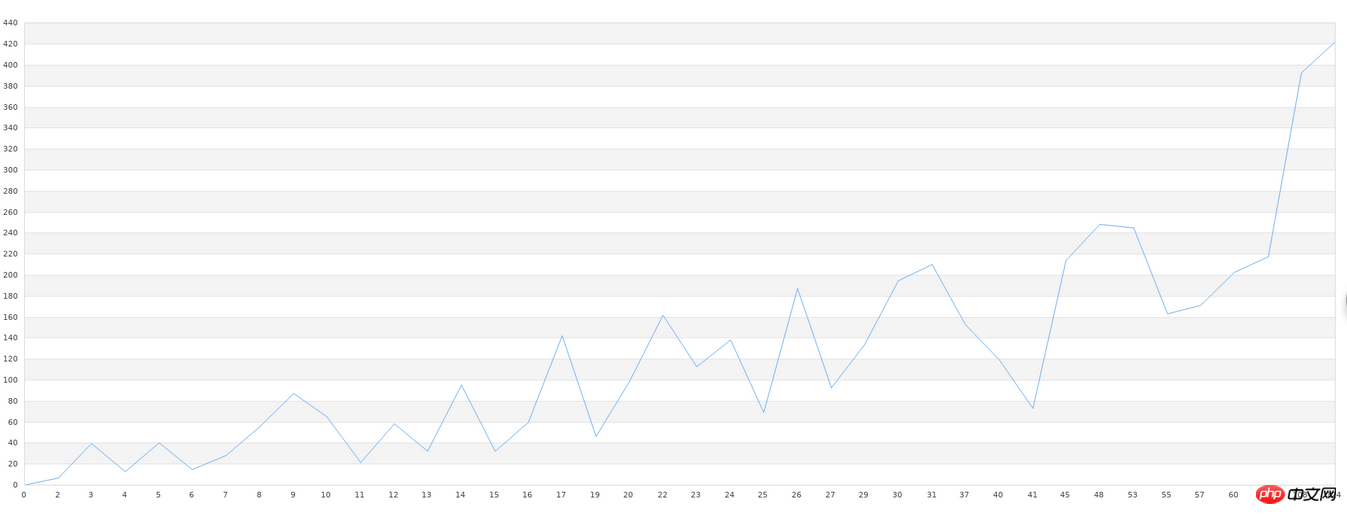
我们先处理不知名数据集。首先,我们的不知名数据集的文件名为data.txt。而这个数据集刚好可以先绘制成x-y折线图。所以,我们先将原数据绘制成一个折线图。由于x轴比较长,所以我们只需要看清楚它大致的形状即可:
绘制采用了php的jpgraph库,代码如下:
<?php
include_once './src/jpgraph.php';
include_once './src/jpgraph_line.php';
$g = new Graph(1920,1080);//jpgraph的绘制操作
$g->SetScale("textint");
$g->title->Set('data');
//文件的处理
$file = fopen('data.txt','r');
$labels = array();
while(!feof($file)){
$data = explode(' ',fgets($file));
$data[1] = str_replace(',','.',$data[1]);//数据处理,将数据中的逗号修正为小数点
$labels[(int)$data[0]] = (float)$data[1];//这里将数据以键值的方式存入数组,方便我们根据键来排序
}
ksort($labels);//按键的大小排序
$x = array();//x轴的表示数据
$y = array();//y轴的表示数据
foreach($labels as $key=>$value){
array_push($x,$key);
array_push($y,$value);
}
$linePlot = new LinePlot($y);
$g->xaxis->SetTickLabels($x);
$linePlot->SetLegend('data');
$g->Add($linePlot);
$g->Stroke();在有了这个原图做对比,我们接下来进行学习。我们采用php-ml中的LeastSquars来进行学习。我们测试的输出需要存入文件,方便我们可以画一个对比图。学习代码如下:
<?php
require 'vendor/autoload.php';
use Phpml\Regression\LeastSquares;
use Phpml\ModelManager;
$file = fopen('data.txt','r');
$samples = array();
$labels = array();
$i = 0;
while(!feof($file)){
$data = explode(' ',fgets($file));
$samples[$i][0] = (int)$data[0];
$data[1] = str_replace(',','.',$data[1]);
$labels[$i] = (float)$data[1];
$i ++;
}
fclose($file);
$regression = new LeastSquares();
$regression->train($samples,$labels);
//这个a数组是根据我们对原数据处理后的x值给出的,做测试用。
$a = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];
for($i = 0; $i < count($a); $i ++){
file_put_contents("putput.txt",($regression->predict([$a[$i]]))."\n",FILE_APPEND); //以追加的方式存入文件
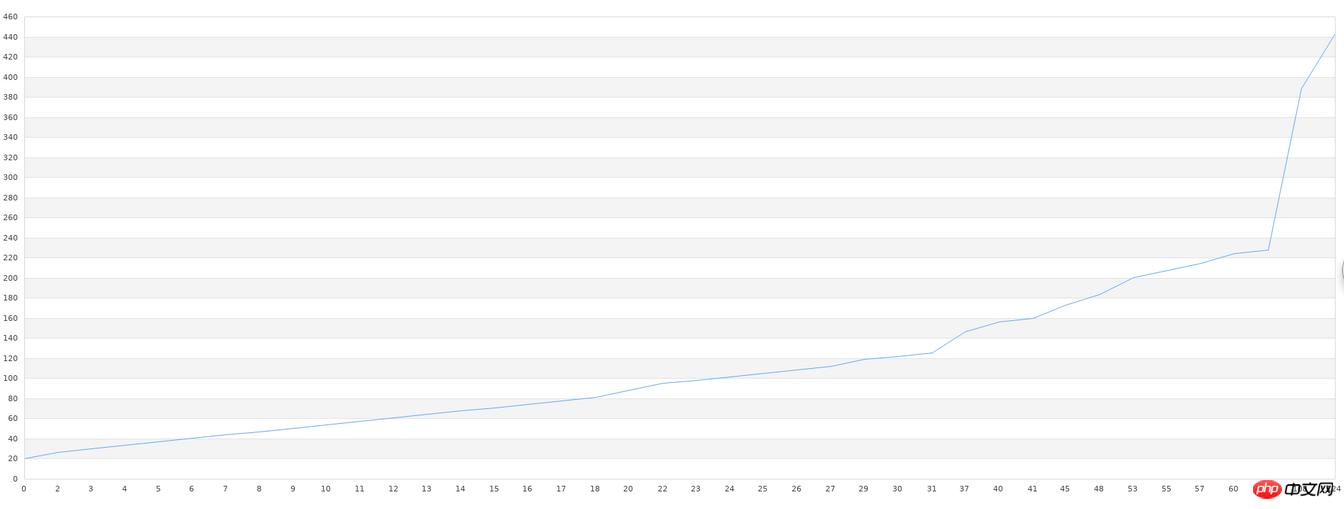
}之后,我们将存入文件的数据读出来,绘制一个图形,先贴最后的效果图:
代码如下:
<?php
include_once './src/jpgraph.php';
include_once './src/jpgraph_line.php';
$g = new Graph(1920,1080);
$g->SetScale("textint");
$g->title->Set('data');
$file = fopen('putput.txt','r');
$y = array();
$i = 0;
while(!feof($file)){
$y[$i] = (float)(fgets($file));
$i ++;
}
$x = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,20,22,23,24,25,26,27,29,30,31,37,40,41,45,48,53,55,57,60,61,108,124];
$linePlot = new LinePlot($y);
$g->xaxis->SetTickLabels($x);
$linePlot->SetLegend('data');
$g->Add($linePlot);
$g->Stroke();可以发现,图形出入还是比较大的,尤其是在图形锯齿比较多的部分。不过,这毕竟是40组数据,我们可以看出,大概的图形趋势是吻合的。一般的库在做这种学习时,数据量低的情况下,准确度都非常低。要达到比较高的精度,需要大量的数据,万条以上的数据量是必要的。如果达不到这个数据要求,那我们使用任何库都是徒劳的。所以,机器学习的实践中,真正难的不在精度低、配置复杂等技术问题,而是数据量不够,或者质量太低(一组数据中无用的数据太多)。在做机器学习之前,对数据的预先处理也是必要的。
接下来,我们来对花蕊数据进行测试。一共三种分类,由于我们下载到的是csv数据,所以我们可以使用php-ml官方提供的操作csv文件的方法。而这里是一个分类问题,所以我们选择库提供的SVC算法来进行分类。我们把花蕊数据的文件名定为Iris.csv,代码如下:
<?php require 'vendor/autoload.php'; use Phpml\Classification\SVC; use Phpml\SupportVectorMachine\Kernel; use Phpml\Dataset\CsvDataset; $dataset = new CsvDataset('Iris.csv' , 4, false); $classifier = new SVC(Kernel::LINEAR,$cost = 1000); $classifier->train($dataset->getSamples(),$dataset->getTargets()); echo $classifier->predict([$argv[1],$argv[2],$argv[3],$argv[4]]);//$argv是命令行参数,调试这种程序使用命令行较方便
是不是很简单?短短12行代码就搞定了。接下来,我们来测试一下。根据我们上面贴出的图,当我们输入5 3.3 1.4 0.2的时候,输出应该是Iris-setosa。我们看一下:

看,至少我们输入一个原来就有的数据,得到了正确的结果。但是,我们输入原数据集中没有的数据呢?我们来测试两组:
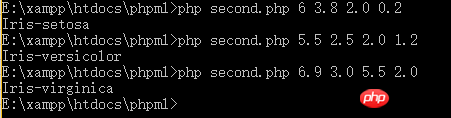
由我们之前贴出的两张图的数据看,我们输入的数据在数据集中并不存在,但分类按照我们初步的观察来看,是合理的。
所以,这个机器学习库对于大多数的人来说,都是够用的。而大多数鄙视这个库鄙视那个库,大谈性能的人,基本上也不是什么大牛。真正的大牛已经忙着捞钱去了,或者正在做学术研究等等。我们更多的应该是掌握算法,了解其中的道理和玄机,而不是夸夸其谈。当然,这个库并不建议用在大型项目上,只推荐小型项目或者个人项目等。
jpgraph只依赖GD库,所以下载引用之后就可以使用,大量的代码都放在了绘制图形和初期的数据处理上。由于库的出色封装,学习代码并不复杂。需要所有代码或者测试数据集的小伙伴可以留言或者私信等,我提供完整的代码,解压即用
Atas ialah kandungan terperinci PHP机器学习库php-ml的实例教程. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bagaimanakah jenis membayangkan jenis PHP, termasuk jenis skalar, jenis pulangan, jenis kesatuan, dan jenis yang boleh dibatalkan?Apr 17, 2025 am 12:25 AM
Bagaimanakah jenis membayangkan jenis PHP, termasuk jenis skalar, jenis pulangan, jenis kesatuan, dan jenis yang boleh dibatalkan?Apr 17, 2025 am 12:25 AMJenis PHP meminta untuk meningkatkan kualiti kod dan kebolehbacaan. 1) Petua Jenis Skalar: Oleh kerana Php7.0, jenis data asas dibenarkan untuk ditentukan dalam parameter fungsi, seperti INT, Float, dan lain -lain. 2) Return Type Prompt: Pastikan konsistensi jenis nilai pulangan fungsi. 3) Jenis Kesatuan Prompt: Oleh kerana Php8.0, pelbagai jenis dibenarkan untuk ditentukan dalam parameter fungsi atau nilai pulangan. 4) Prompt jenis yang boleh dibatalkan: membolehkan untuk memasukkan nilai null dan mengendalikan fungsi yang boleh mengembalikan nilai null.
 Bagaimanakah PHP mengendalikan pengklonan objek (kata kunci klon) dan kaedah sihir __clone?Apr 17, 2025 am 12:24 AM
Bagaimanakah PHP mengendalikan pengklonan objek (kata kunci klon) dan kaedah sihir __clone?Apr 17, 2025 am 12:24 AMDalam PHP, gunakan kata kunci klon untuk membuat salinan objek dan menyesuaikan tingkah laku pengklonan melalui kaedah Magic \ _ _ _. 1. Gunakan kata kunci klon untuk membuat salinan cetek, mengkloning sifat objek tetapi bukan sifat objek. 2. Kaedah klon \ _ \ _ boleh menyalin objek bersarang untuk mengelakkan masalah menyalin cetek. 3. Beri perhatian untuk mengelakkan rujukan pekeliling dan masalah prestasi dalam pengklonan, dan mengoptimumkan operasi pengklonan untuk meningkatkan kecekapan.
 PHP vs Python: Gunakan Kes dan AplikasiApr 17, 2025 am 12:23 AM
PHP vs Python: Gunakan Kes dan AplikasiApr 17, 2025 am 12:23 AMPHP sesuai untuk pembangunan web dan sistem pengurusan kandungan, dan Python sesuai untuk sains data, pembelajaran mesin dan skrip automasi. 1.PHP berfungsi dengan baik dalam membina laman web dan aplikasi yang cepat dan berskala dan biasanya digunakan dalam CMS seperti WordPress. 2. Python telah melakukan yang luar biasa dalam bidang sains data dan pembelajaran mesin, dengan perpustakaan yang kaya seperti numpy dan tensorflow.
 Huraikan tajuk caching HTTP yang berbeza (mis., Cache-Control, ETAG, Modified Last).Apr 17, 2025 am 12:22 AM
Huraikan tajuk caching HTTP yang berbeza (mis., Cache-Control, ETAG, Modified Last).Apr 17, 2025 am 12:22 AMPemain utama dalam tajuk cache HTTP termasuk kawalan cache, ETAG, dan modifikasi terakhir. 1.Cache-Control digunakan untuk mengawal dasar caching. Contoh: Cache-Control: Max-Age = 3600, Awam. 2. ETAG mengesahkan perubahan sumber melalui pengenal unik, Contoh: ETAG: "686897696A7C876B7E". 3. Modified Last Menunjukkan Masa Pengubahsuaian Terakhir Sumber, Contoh: Modified Last: Wed, 21OCT201507: 28: 00GMT.
 Terangkan hashing kata laluan yang selamat di PHP (mis., Password_hash, password_verify). Mengapa tidak menggunakan MD5 atau SHA1?Apr 17, 2025 am 12:06 AM
Terangkan hashing kata laluan yang selamat di PHP (mis., Password_hash, password_verify). Mengapa tidak menggunakan MD5 atau SHA1?Apr 17, 2025 am 12:06 AMDalam php, kata laluan_hash dan kata laluan 1) password_hash menjana hash yang mengandungi nilai garam untuk meningkatkan keselamatan. 2) Kata Laluan_verify Sahkan kata laluan dan pastikan keselamatan dengan membandingkan nilai hash. 3) MD5 dan SHA1 terdedah dan kekurangan nilai garam, dan tidak sesuai untuk keselamatan kata laluan moden.
 PHP: Pengenalan kepada bahasa skrip sisi pelayanApr 16, 2025 am 12:18 AM
PHP: Pengenalan kepada bahasa skrip sisi pelayanApr 16, 2025 am 12:18 AMPHP adalah bahasa skrip sisi pelayan yang digunakan untuk pembangunan web dinamik dan aplikasi sisi pelayan. 1.Php adalah bahasa yang ditafsirkan yang tidak memerlukan kompilasi dan sesuai untuk perkembangan pesat. 2. Kod PHP tertanam dalam HTML, menjadikannya mudah untuk membangunkan laman web. 3. PHP memproses logik sisi pelayan, menghasilkan output HTML, dan menyokong interaksi pengguna dan pemprosesan data. 4. PHP boleh berinteraksi dengan pangkalan data, penyerahan borang proses, dan melaksanakan tugas-tugas sampingan pelayan.
 PHP dan Web: Meneroka kesan jangka panjangnyaApr 16, 2025 am 12:17 AM
PHP dan Web: Meneroka kesan jangka panjangnyaApr 16, 2025 am 12:17 AMPHP telah membentuk rangkaian sejak beberapa dekad yang lalu dan akan terus memainkan peranan penting dalam pembangunan web. 1) PHP berasal pada tahun 1994 dan telah menjadi pilihan pertama bagi pemaju kerana kemudahan penggunaannya dan integrasi lancar dengan MySQL. 2) Fungsi terasnya termasuk menghasilkan kandungan dinamik dan mengintegrasikan dengan pangkalan data, yang membolehkan laman web dikemas kini secara real time dan dipaparkan secara peribadi. 3) Aplikasi dan ekosistem PHP yang luas telah mendorong kesan jangka panjangnya, tetapi ia juga menghadapi kemas kini versi dan cabaran keselamatan. 4) Penambahbaikan prestasi dalam beberapa tahun kebelakangan ini, seperti pembebasan Php7, membolehkannya bersaing dengan bahasa moden. 5) Pada masa akan datang, PHP perlu menangani cabaran baru seperti kontena dan microservices, tetapi fleksibiliti dan komuniti aktif menjadikannya boleh disesuaikan.
 Mengapa menggunakan PHP? Kelebihan dan faedah dijelaskanApr 16, 2025 am 12:16 AM
Mengapa menggunakan PHP? Kelebihan dan faedah dijelaskanApr 16, 2025 am 12:16 AMManfaat utama PHP termasuk kemudahan pembelajaran, sokongan pembangunan web yang kukuh, perpustakaan dan kerangka yang kaya, prestasi tinggi dan skalabilitas, keserasian silang platform, dan keberkesanan kos. 1) mudah dipelajari dan digunakan, sesuai untuk pemula; 2) integrasi yang baik dengan pelayan web dan menyokong pelbagai pangkalan data; 3) mempunyai rangka kerja yang kuat seperti Laravel; 4) Prestasi tinggi dapat dicapai melalui pengoptimuman; 5) menyokong pelbagai sistem operasi; 6) Sumber terbuka untuk mengurangkan kos pembangunan.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

