
Rumah >pembangunan bahagian belakang >Tutorial Python >python是如何爬取散文网的文章的?
python是如何爬取散文网的文章的?

- 零下一度asal
- 2017-07-03 09:39:311712semak imbas
配置python 2.7
bs4
requests安装 用pip进行安装 sudo pip install bs4
sudo pip install requests
简要说明一下bs4的使用因为是爬取网页 所以就介绍find 跟find_all
find跟find_all的不同在于返回的东西不同 find返回的是匹配到的第一个标签及标签里的内容
find_all返回的是一个列表
比如我们写一个test.html 用来测试find跟find_all的区别。内容是:
<html> <head> </head> <body> <div id="one"><a></a></div> <div id="two"><a href="#">abc</a></div> <div id="three"><a href="#">three a</a><a href="#">three a</a><a href="#">three a</a></div> <div id="four"><a href="#">four<p>four p</p><p>four p</p><p>four p</p> a</a></div> </body> </html>
<br/>
然后test.py的代码为:
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('div') print s.find_all('div') print "------------------------------" print s.find('div',id='one') print s.find_all('div',id='one') print "------------------------------" print s.find('div',id="two") print s.find_all('div',id="two") print "------------------------------" print s.find('div',id="three") print s.find_all('div',id="three") print "------------------------------" print s.find('div',id="four") print s.find_all('div',id="four") print "------------------------------"
<br/>
运行以后我们可以看到结果当获取指定标签时候两者区别不大当获取一组标签的时候两者的区别就会显示出来

所以我们在使用时候要注意到底要的是什么,否则会出现报错
接下来就是通过requests 获取网页信息了,我不太懂别人为什么要写heard跟其他的东西
我直接进行网页访问,通过get方式获取散文网几个分类的二级网页然后通过一个组的测试,把所有的网页爬取一遍
def get_html():
url = ""
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel'] for doc in two_html:
i=1 if doc=='sanwen':print "running sanwen -----------------------------" if doc=='shige':print "running shige ------------------------------" if doc=='zawen':print 'running zawen -------------------------------' if doc=='suibi':print 'running suibi -------------------------------' if doc=='rizhi':print 'running ruzhi -------------------------------' if doc=='nove':print 'running xiaoxiaoshuo -------------------------' while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)if res.status_code==200:
soup(res.text)
i+=i
<br/>
这部分的代码中我没有对res.status_code不是200的进行处理,导致的问题是会不显示错误,爬取的内容会有丢失。然后分析散文网的网页,发现是www.sanwen.net/rizhi/&p=1
p最大值是10这个不太懂,上次爬盘多多是100页,算了算了以后再分析。然后就通过get方法获取每页的内容。
获取每页内容以后就是分析作者跟题目了代码是这样的
def soup(html_text):
s = BeautifulSoup(html_text,'lxml')
link = s.find('div',class_='categorylist').find_all('li') for i in link:if i!=s.find('li',class_='page'):
title = i.find_all('a')[1]
author = i.find_all('a')[2].text
url = title.attrs['href']
sign = re.compile(r'(//)|/')
match = sign.search(title.text)
file_name = title.text if match:
file_name = sign.sub('a',str(title.text))
<br/>
获取标题的时候出现坑爹的事,请问大佬们写散文你标题加斜杠干嘛,不光加一个还有加两个的,这个问题直接导致我后面写入文件的时候文件名出现错误,于是写正则表达式,我给你改行了吧。
最后就是获取散文内容了,通过每页的分析,获得文章地址,然后直接获取内容,本来还想直接通过改网页地址一个一个的获得呢,这样也省事了。
def get_content(url):
res = requests.get(''+url) if res.status_code==200:
soup = BeautifulSoup(res.text,'lxml')
contents = soup.find('div',class_='content').find_all('p')
content = ''for i in contents:
content+=i.text+'\n'return content
<br/>
最后就是写入文件保存ok
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
三个函数获取散文网的散文,不过有问题,问题在于不知道为什么有些散文丢失了我只能获取到大概400多篇文章,这跟散文网的文章是差很多很多的,但是确实是一页一页的获取来的,这个问题希望大佬帮忙看看。可能应该做网页无法访问的处理,当然我觉得跟我宿舍这个破网有关系
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n') f.write(author+'\n') content=get_content(url) f.write(content) f.close()
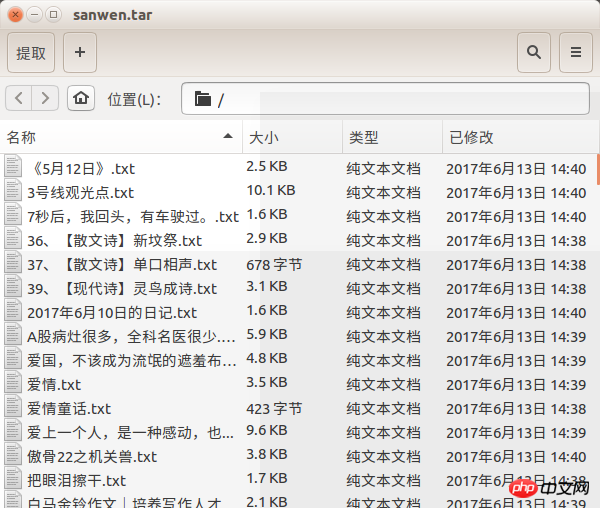
差点忘了效果图

Atas ialah kandungan terperinci python是如何爬取散文网的文章的?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!