
Rumah >hujung hadapan web >tutorial js >js中关于闭包的详细介绍
js中关于闭包的详细介绍

- 零下一度asal
- 2017-06-29 11:35:441253semak imbas
1. 什么是闭包?
来看一些关于闭包的定义:
闭包是指有权访问另一个函数作用域中变量的函数 --《JS高级程序设计第三版》 p178
函数对象可以通过作用域链相关联起来,函数体内部的变量都可以保存在函数作用域内,这种特性称为 ‘闭包’ 。 --《JS权威指南》 p183
内部函数可以访问定义它们的外部函数的参数和变量(除了
this和arguments)。 --《JS语言精粹》 p36
来个定义总结
可以访问外部函数作用域中变量的
函数被内部函数访问的外部函数的变量可以保存在外部函数作用域内而不被回收---这是核心,后面我们遇到闭包都要想到,我们要重点关注被闭包引用的这个变量。
来创建个简单的闭包
var sayName = function(){var name = 'jozo';return function(){
alert(name);
}
};var say = sayName();
say();来解读后面两个语句:
var say = sayName():返回了一个匿名的内部函数保存在变量say中,并且引用了外部函数的变量name,由于垃圾回收机制,sayName函数执行完毕后,变量name并没有被销毁。say():执行返回的内部函数,依然能访问变量name,输出 'jozo' .
2. 闭包中的作用域链
理解作用域链对理解闭包也很有帮助。
变量在作用域中的查找方式应该都很熟悉了,其实这就是顺着作用域链往上查找的。
当函数被调用时:
先创建一个执行环境(execution context),及相应的作用域链;
将arguments和其他命名参数的值添加到函数的活动对象(activation object)
作用域链:当前函数的活动对象优先级最高,外部函数的活动对象次之,外部函数的外部函数的活动对象依次递减,直至作用域链的末端--全局作用域。优先级就是变量查找的先后顺序;
先来看个普通的作用域链:
function sayName(name){return name;
}var say = sayName('jozo');这段代码包含两个作用域:a.全局作用域;b.sayName函数的作用域,也就是只有两个变量对象,当执行到对应的执行环境时,该变量对象会成为活动对象,并被推入到执行环境作用域链的前端,也就是成为优先级最高的那个。 看图说话:

这图在JS高级程序设计书上也有,我重新绘了遍。
在创建sayName()函数时,会创建一个预先包含变量对象的作用域链,也就是图中索引为1的作用域链,并且被保存到内部的[[Scope]]属性中,当调用sayName()函数的时候,会创建一个执行环境,然后通过复制函数的[[Scope]]属性中的对象构建起作用域链,此后,又有一个活动对象(图中索引为0)被创建,并被推入执行环境作用域链的前端。
一般来说,当函数执行完毕后,局部活动对象就会被销毁,内存中仅保存全局作用域。但是,闭包的情况又有所不同 :
再来看看看闭包的作用域链:
function sayName(name){return function(){return name;
}
}var say = sayName('jozo');这个闭包实例比上一个例子多了一个匿名函数的作用域:
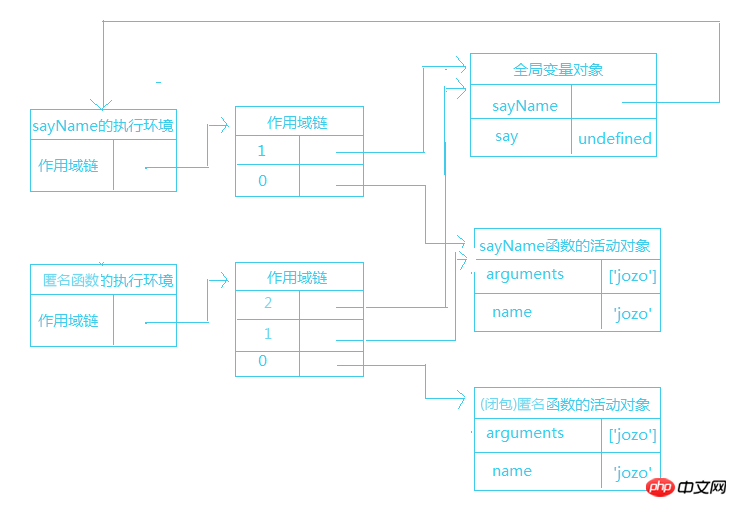
在匿名函数从sayName()函数中被返回后,它的作用域链被初始化为包含sayName()函数的活动对象和全局变量对象。这样,匿名函数就可以访问在sayName()中定义的所有变量和参数,更为重要的是,sayName()函数在执行完毕后,其活动对象也不会被销毁,因为匿名函数的作用域链依然在引用这个活动对象,换句话说,sayName()函数执行完后,其执行环境的作用域链会被销毁,但他的活动对象会留在内存中,知道匿名函数会销毁。这个也是后面要讲到的内存泄露的问题。
作用域链问题不写那么多了,写书上的东西也很累 o(╯□╰)o
3. 闭包的实例
实例1:实现累加
// 方式1var a = 0;var add = function(){
a++;
console.log(a)
}add();add();//方式2 :闭包var add = (function(){
var a = 0;
return function(){
a++;
console.log(a);
}
})();
console.log(a); //undefinedadd();add();
相比之下方式2更加优雅,也减少全局变量,将变量私有化实例2 :给每个li添加点击事件
var oli = document.getElementsByTagName('li'); var i; for(i = 0;i < 5;i++){
oli[i].onclick = function(){
alert(i);
}
} console.log(i); // 5 //执行匿名函数
(function(){
alert(i); //5
}());上面是一个经典的例子,我们都知道执行结果是都弹出5,也知道可以用闭包解决这个问题,但是我刚开始始终不能明白为什么每次弹出都是5,为什么闭包可以解决这问题。后来捋一捋还是把它弄清晰了:
a. 先来分析没用闭包前的情况:for循环中,我们给每个li点击事件绑定了一个匿名函数,匿名函数中返回了变量i的值,当循环结束后,变量i的值变为5,此时我们再去点击每个li,也就是执行相应的匿名函数(看上面的代码),这是变量i已经是5了,所以每个点击弹出5. 因为这里返回的每个匿名函数都是引用了同一个变量i,如果我们新建一个变量保存循环执行时当前的i的值,然后再让匿名函数应用这个变量,最后再返回这个匿名函数,这样就可以达到我们的目的了,这就是运用闭包来实现的!
b. 再来分析下运用闭包时的情况:
var oli = document.getElementsByTagName('li'); var i; for(i = 0;i < 5;i++){
oli[i].onclick = (function(num){ var a = num; // 为了说明问题 return function(){
alert(a);
}
})(i)
} console.log(i); // 5这里for循环执行时,给点击事件绑定的匿名函数传递i后立即执行返回一个内部的匿名函数,因为参数是按值传递的,所以此时形参num保存的就是当前i的值,然后赋值给局部变量 a,然后这个内部的匿名函数一直保存着a的引用,也就是一直保存着当前i的值。 所以循环执行完毕后点击每个li,返回的匿名函数执行弹出各自保存的 a 的引用的值。
4. 闭包的运用
我们来看看闭包的用途。事实上,通过使用闭包,我们可以做很多事情。比如模拟面向对象的代码风格;更优雅,更简洁的表达出代码;在某些方面提升代码的执行效率。
1. 匿名自执行函数
我们在实际情况下经常遇到这样一种情况,即有的函数只需要执行一次,其内部变量无需维护,比如UI的初始化,那么我们可以使用闭包:
//将全部li字体变为红色
(function(){ var els = document.getElementsByTagName('li');for(var i = 0,lng = els.length;i < lng;i++){
els[i].style.color = 'red';
}
})();我们创建了一个匿名的函数,并立即执行它,由于外部无法引用它内部的变量,
因此els,i,lng这些局部变量在执行完后很快就会被释放,节省内存!
关键是这种机制不会污染全局对象。
2. 实现封装/模块化代码
var person= function(){ //变量作用域为函数内部,外部无法访问 var name = "default"; return {
getName : function(){
return name;
},
setName : function(newName){
name = newName;
}
}
}();console.log(person.name);//直接访问,结果为undefined
console.log(person.getName()); //default
person.setName("jozo");
console.log(person.getName()); //jozo3. 实现面向对象中的对象
这样不同的对象(类的实例)拥有独立的成员及状态,互不干涉。虽然JavaScript中没有类这样的机制,但是通过使用闭包,
我们可以模拟出这样的机制。还是以上边的例子来讲:
function Person(){ var name = "default"; return {
getName : function(){
return name;
},
setName : function(newName){
name = newName;
}
}
};
var person1= Person();
print(person1.getName());
john.setName("person1");
print(person1.getName()); // person1
var person2= Person();
print(person2.getName());
jack.setName("erson2");
print(erson2.getName()); //person2Person的两个实例person1 和 person2 互不干扰!因为这两个实例对name这个成员的访问是独立的 。
5. 内存泄露及解决方案
垃圾回收机制
说到内存管理,自然离不开JS中的垃圾回收机制,有两种策略来实现垃圾回收:标记清除 和 引用计数;
标记清除:垃圾收集器在运行的时候会给存储在内存中的所有变量都加上标记,然后,它会去掉环境中的变量的标记和被环境中的变量引用的变量的标记,此后,如果变量再被标记则表示此变量准备被删除。 2008年为止,IE,Firefox,opera,chrome,Safari的javascript都用使用了该方式;
引用计数:跟踪记录每个值被引用的次数,当声明一个变量并将一个引用类型的值赋给该变量时,这个值的引用次数就是1,如果这个值再被赋值给另一个变量,则引用次数加1。相反,如果一个变量脱离了该值的引用,则该值引用次数减1,当次数为0时,就会等待垃圾收集器的回收。
这个方式存在一个比较大的问题就是循环引用,就是说A对象包含一个指向B的指针,对象B也包含一个指向A的引用。 这就可能造成大量内存得不到回收(内存泄露),因为它们的引用次数永远不可能是 0 。早期的IE版本里(ie4-ie6)采用是计数的垃圾回收机制,闭包导致内存泄露的一个原因就是这个算法的一个缺陷。
我们知道,IE中有一部分对象并不是原生额javascript对象,例如,BOM和DOM中的对象就是以COM对象的形式实现的,而COM对象的垃圾回收机制采用的就是引用计数。因此,虽然IE的javascript引擎采用的是标记清除策略,但是访问COM对象依然是基于引用计数的,因此只要在IE中设计COM对象就会存在循环引用的问题!
举个栗子:
window.onload = function(){var el = document.getElementById("id");
el.onclick = function(){
alert(el.id);
}
}这段代码为什么会造成内存泄露?
el.onclick= function () {
alert(el.id);
};执行这段代码的时候,将匿名函数对象赋值给el的onclick属性;然后匿名函数内部又引用了el对象,存在循环引用,所以不能被回收;
解决方法:
window.onload = function(){var el = document.getElementById("id");var id = el.id; //解除循环引用
el.onclick = function(){
alert(id);
}
el = null; // 将闭包引用的外部函数中活动对象清除
}6. 总结闭包的优缺点
优点:
可以让一个变量常驻内存 (如果用的多了就成了缺点
避免全局变量的污染
私有化变量
缺点
因为闭包会携带包含它的函数的作用域,因此会比其他函数占用更多的内存
引起内存泄露
Atas ialah kandungan terperinci js中关于闭包的详细介绍. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Analisis mendalam bagi komponen kumpulan senarai Bootstrap
- Penjelasan terperinci tentang fungsi JavaScript kari
- Contoh lengkap penjanaan kata laluan JS dan pengesanan kekuatan (dengan muat turun kod sumber demo)
- Angularjs menyepadukan UI WeChat (weui)
- Cara cepat bertukar antara Cina Tradisional dan Cina Ringkas dengan JavaScript dan helah untuk tapak web menyokong pertukaran antara kemahiran_javascript Cina Ringkas dan Tradisional