
Rumah >Java >javaTutorial >编写高效代码(一) 关于数组和集合
编写高效代码(一) 关于数组和集合
- 巴扎黑asal
- 2017-06-26 10:42:361640semak imbas
阅读目录
建议65:避开基本类型数组转换列表陷阱
建议66:asList方法产生的List的对象不可更改
建议67:不同的列表选择不同的遍历算法
建议68:频繁插入和删除时使用LinkList
建议69:列表相等只关心元素数据
建议65:避开基本类型数组转换列表陷阱
我们在开发中经常会使用Arrays和Collections这两个工具类和列表之间转换,非常方便,但也有时候会出现一些奇怪的问题,来看如下代码:

1 public class Client65 {
2 public static void main(String[] args) {
3 int data [] = {1,2,3,4,5};
4 List list= Arrays.asList(data);
5 System.out.println("列表中的元素数量是:"+list.size());
6 }
7 }

也许你会说,这很简单,list变量的元素数量当然是5了。但是运行后打印出来的列表数量为1。
事实上data确实是一个有5个元素的int类型数组,只是通过asList转换成列表后就只有一个元素了,这是为什么呢?其他4个元素到什么地方去了呢?
我们仔细看一下Arrays.asList的方法说明:输入一个变长参数,返回一个固定长度的列表。注意这里是一个变长参数,看源码:
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}asList方法输入的是一个泛型变长参数,我们知道基本类型是不能泛型化的,也就是说8个基本类型不能作为泛型参数,要想作为泛型参数就必须使用其所对应的包装类型,那前面的例子传递了一个int类型的数组,为何程序没有报编译错误呢?
在Java中,数组是一个对象,它是可以泛型化的,也就是说我们的例子是把一个int类型的数组作为了T的类型,所以在转换后在List中就只有一个类型为int数组的元素了,我们打印出来看看,代码如下:

1 public class Client65 {
2 public static void main(String[] args) {
3 int data [] = {1,2,3,4,5};
4 List list= Arrays.asList(data);
5 System.out.println("元素类型是:"+list.get(0).getClass());
6 System.out.println("前后是否相等:"+data.equals(list.get(0)));
7 }
8 }

输出的结果是: 元素类型是:class [I 前后是否相等:true
很明显,放在列表中的元素时一个int数组,可能有人要问了,为什么"元素类型:"后的class是"[I"?我们并没有指明是数组(Array)类型呀!这是因为JVM不可能输出Array类型,因为Array是属于java.lang.reflect包的,它是通过反射访问数组元素的工具类。在Java中任何一个一维数组的类型都是 " [I " ,究其原因就是Java并没有定义数组这一个类,它是在编译器编译的时候生成的,是一个特殊的类,在JDK的帮助中也没有任何数组类的信息。
弄清楚了问题,修改也很easy,直接使用包装类即可,部分代码如下:
Integer data [] = {1,2,3,4,5};把int替换为Integer即可让输出元素数量为5.需要说明的是,不仅仅是int类型的数组有这个问题,其它7个基本类型的数组也存在相似的问题,这就需要大家注意了,在把基本类型数组转换为列表时,要特别小心asList方法的陷阱,避免出现程序逻辑混乱的情况。
注意:原始类型数组不能作为asList的输入参数,否则会引起程序逻辑混乱。
建议66:asList方法产生的List的对象不可更改
上一个建议指出了asList方法在转换基本类型数组时存在的问题,接着我们看一下asList方法返回的列表有何特殊的地方,代码如下:

1 public class Client66 {
2 public static void main(String[] args) {
3 // 五天工作制
4 Week days[] = { Week.Mon, Week.Tue, Week.Wed, Week.Thu, Week.Fri };
5 // 转换为列表
6 List<Week> list = Arrays.asList(days);
7 // 增加周六为工作日
8 list.add(Week.Sat);
9 /* do something */
10 }
11 }
12 enum Week {
13 Sun, Mon, Tue, Wed, Thu, Fri, Sat
14 }

很简单的程序呀,默认声明的工作日(workDays)是从周一到周五,偶尔周六也会算作工作日加入到工作日列表中,不过,这段程序执行时会不会有什么问题呢?编译没有任何问题,但是一运行,却出现了如下结果:
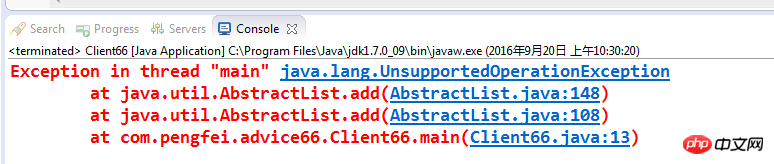
UnsupportedOperationException,不支持的操作,居然不支持list的add方法,这是什么原因呢?我们看看asList方法的源代码:
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}直接new了一个ArrayList对象返回,难道ArrayList不支持add方法,不可能呀!可能,问题就出现在这个ArrayList类上,此ArrayList非java.util.ArrayList,而是Arrays工具类的一个内部类,其构造函数如下所示:

1 private static class ArrayList<E> extends AbstractList<E>
2 implements RandomAccess, java.io.Serializable
3 {
4 private static final long serialVersionUID = -2764017481108945198L;
5 private final E[] a;
6
7 ArrayList(E[] array) {
8 if (array==null)
9 throw new NullPointerException();
10 a = array;
11 }
12 /*其它方法略*/
13 }

这个ArrayList是一个静态私有内部类,除了Arrays能访问外,其它类都不能访问,仔细看这个类,它没有提供add方法,那肯定是父类AbstractList提供了,来看代码:

1 public boolean add(E e) {
2 add(size(), e);
3 return true;
4 }
5
6 public void add(int index, E element) {
7 throw new UnsupportedOperationException();
8 }

父类确实提供了,但没有提供具体的实现,所以每个子类都需要自己覆写add方法,而Arrays的内部类ArrayList没有覆写,因此add一个元素就报错了。
我们深入地看看这个ArrayList静态内部类,它仅仅实现了5个方法:
size:元素数量
get:获得制定元素
set:重置某一元素值
contains:是否包含某元素
toArray:转化为数组,实现了数组的浅拷贝
把这几个方法的源代码展示一下:

1 //元素数量
2 public int size() {
3 return a.length;
4 }
5
6 public Object[] toArray() {
7 return a.clone();
8 }
9 //转化为数组,实现了数组的浅拷贝
10 public <T> T[] toArray(T[] a) {
11 int size = size();
12 if (a.length < size)
13 return Arrays.copyOf(this.a, size,
14 (Class<? extends T[]>) a.getClass());
15 System.arraycopy(this.a, 0, a, 0, size);
16 if (a.length > size)
17 a[size] = null;
18 return a;
19 }
20 //获得指定元素
21 public E get(int index) {
22 return a[index];
23 }
24 //重置某一元素
25 public E set(int index, E element) {
26 E oldValue = a[index];
27 a[index] = element;
28 return oldValue;
29 }
30
31 public int indexOf(Object o) {
32 if (o==null) {
33 for (int i=0; i<a.length; i++)
34 if (a[i]==null)
35 return i;
36 } else {
37 for (int i=0; i<a.length; i++)
38 if (o.equals(a[i]))
39 return i;
40 }
41 return -1;
42 }
43 //是否包含元素
44 public boolean contains(Object o) {
45 return indexOf(o) != -1;
46 }
对于我们经常使用list.add和list.remove方法它都没有实现,也就是说asList返回的是一个长度不可变的列表,数组是多长,转换成的列表也就是多长,换句话说此处的列表只是数组的一个外壳,不再保持列表的动态变长的特性,这才是我们关注的重点。有些开发人员喜欢这样定义个初始化列表:
List<String> names= Arrays.asList("张三","李四","王五");
一句话完成了列表的定义和初始化,看似很便捷,却隐藏着重大隐患---列表长度无法修改。想想看,如果这样一个List传递到一个允许添加的add操作的方法中,那将会产生何种结果,如果有这种习惯的javaer,请慎之戒之,除非非常自信该List只用于只读操作。
建议67:不同的列表选择不同的遍历算法
我们思考这样一个案例:统计一个省的各科高考平均值,比如数学平均分是多少,语文平均分是多少等,这是每年招生办都会公布的数据,我们来想想看该算法应如何实现。当然使用数据库中的一个SQL语句就可能求出平均值,不过这不再我们的考虑之列,这里还是使用纯Java的算法来解决之,看代码:

1 public class Client67 {
2 public static void main(String[] args) {
3 // 学生数量 80万
4 int stuNum = 80 * 10000;
5 // List集合,记录所有学生的分数
6 List<Integer> scores = new ArrayList<Integer>(stuNum);
7 // 写入分数
8 for (int i = 0; i < stuNum; i++) {
9 scores.add(new Random().nextInt(150));
10 }
11 // 记录开始计算 时间
12 long start = System.currentTimeMillis();
13 System.out.println("平均分是:" + average(scores));
14 long end = System.currentTimeMillis();
15 System.out.println("执行时间:" + (end - start) + "ms");
16 }
17
18 public static int average(List<Integer> scores) {
19 int sum = 0;
20 // 遍历求和
21 for (int i : scores) {
22 sum += i;
23 }
24 return sum / scores.size();
25 }
26 }

把80万名学生的成绩放到一个ArrayList数组中,然后通过foreach方法遍历求和,再计算平均值,程序很简单,输出结果:
平均分是:74
执行时间:11ms
仅仅计算一个算术平均值就花了11ms,不要说什么其它诸如加权平均值,补充平均值等算法,那花的时间肯定更长。我们仔细分析一下average方法,加号操作是最基本的,没有什么可以优化的,剩下的就是一个遍历了,问题是List的遍历可以优化吗?
我们尝试一下,List的遍历还有另外一种方式,即通过下标方式来访问,代码如下:

1 public static int average(List<Integer> scores) {
2 int sum = 0;
3 // 遍历求和
4 for (int i = 0; i < scores.size(); i++) {
5 sum += scores.get(i);
6 }
7 return sum / scores.size();
8 }

不再使用foreach遍历,而是采用下标方式遍历,我们看看输出结果:
平均分是:74
执行时间:8ms
执行时间已经下降,如果数据量更大,会更明显。那为什么我们使用下标方式遍历数组可以提高的性能呢?
这是因为ArrayList数组实现了RandomAccess接口(随机存取接口),这样标志着ArrayList是一个可以随机存取的列表。在Java中,RandomAccess和Cloneable、Serializable一样,都是标志性接口,不需要任何实现,只是用来表明其实现类具有某种特质的,实现了Cloneable表明可以被拷贝,实现了Serializable接口表明被序列化了,实现了RandomAccess接口则表明这个类可以随机存取,对我们的ArrayList来说也就标志着其数据元素之间没有关联,即两个位置相邻的元素之间没有相互依赖和索引关系,可以随机访问和存取。我们知道,Java的foreach语法时iterator(迭代器)的变形用法,也就是说上面的foreach与下面的代码等价:
for (Iterator<Integer> i = scores.iterator(); i.hasNext();) {
sum += i.next();
}那我们再想想什么是迭代器,迭代器是23中设计模式中的一种,"提供一种方法访问一个容器对象中的各个元素,同时又无须暴露该对象的内部细节",也就是说对于ArrayList,需要先创建一个迭代器容器,然后屏蔽内部遍历细节,对外提供hasNext、next等方法。问题是ArrayList实现RandomAccess接口,表明元素之间本来没有关系,可是,为了使用迭代器就需要强制建立一种相互"知晓"的关系,比如上一个元素可以判断是否有下一个元素,以及下一个元素时什么等关系,这也就是foreach遍历耗时的原因。
Java的ArrayList类加上了RandomAccess接口,就是在告诉我们,“ArrayList是随机存取的,采用下标方式遍历列表速度回更快”,接着又有一个问题,为什么不把RandomAccess接口加到所有List的实现类上呢?
那是因为有些List的实现类不是随机存取的,而是有序存取的,比如LinkedList类,LinkedList类也是一个列表,但它实现了双向链表,每个数据节点都有三个数据项:前节点的引用(Previous Node)、本节点元素(Node Element)、后继结点的引用(Next Node),这是数据结构的基本知识,不多讲了,也就是说在LinkedList中的两个元素本来就是有关联的,我知道你的存在,你也知道我的存在。那大家想想看,元素之间已经有关联了,使用foreach也就是迭代器方式是不是效率更高呢?我们修改一下例子,代码如下:

1 public static void main(String[] args) {
2 // 学生数量 80万
3 int stuNum = 80 * 10000;
4 // List集合,记录所有学生的分数
5 List<Integer> scores = new LinkedList<Integer>();
6 // 写入分数
7 for (int i = 0; i < stuNum; i++) {
8 scores.add(new Random().nextInt(150));
9 }
10 // 记录开始计算 时间
11 long start = System.currentTimeMillis();
12 System.out.println("平均分是:" + average(scores));
13 long end = System.currentTimeMillis();
14 System.out.println("执行时间:" + (end - start) + "ms");
15 }
16
17 public static int average(List<Integer> scores) {
18 int sum = 0;
19 // 遍历求和
20 for (int i : scores) {
21 sum += i;
22 }
23 return sum / scores.size();
24 }

输出结果为: 平均分是:74 执行时间:12ms 。执行效率还好。但是比ArrayList就慢了,但如果LinkedList采用下标方式遍历:效率会如何呢?我告诉你会很慢。直接分析一下源码:
1 public E get(int index) {
2 checkElementIndex(index);
3 return node(index).item;
4 }由node方法查找指定下标的节点,然后返回其包含的元素,看node方法:

1 Node<E> node(int index) {
2 // assert isElementIndex(index);
3
4 if (index < (size >> 1)) {
5 Node<E> x = first;
6 for (int i = 0; i < index; i++)
7 x = x.next;
8 return x;
9 } else {
10 Node<E> x = last;
11 for (int i = size - 1; i > index; i--)
12 x = x.prev;
13 return x;
14 }
15 }

看懂了吗?程序会先判断输入的下标与中间值(size右移一位,也就是除以2了)的关系,小于中间值则从头开始正向搜索,大于中间值则从尾节点反向搜索,想想看,每一次的get方法都是一个遍历,"性能"两字从何说去呢?
明白了随机存取列表和有序存取列表的区别,我们的average方法就必须重构了,以便实现不同的列表采用不同的遍历方式,代码如下:

1 public static int average(List<Integer> scores) {
2 int sum = 0;
3
4 if (scores instanceof RandomAccess) {
5 // 可以随机存取,则使用下标遍历
6 for (int i = 0; i < scores.size(); i++) {
7 sum += scores.get(i);
8 }
9 } else {
10 // 有序存取,使用foreach方式
11 for (int i : scores) {
12 sum += i;
13 }
14 }
15 return sum / scores.size();
16 }

如此一来,列表的遍历就可以"以不变应万变"了,无论是随机存取列表还是有序列表,它都可以提供快速的遍历。
注意:列表遍历不是那么简单的,适时选择最优的遍历方式,不要固化为一种。
建议68:频繁插入和删除时使用LinkList
上一个建议介绍了列表的遍历方式,也就是“读” 操作,本建议将介绍列表的"写"操作:即插入、删除、修改动作。
(1)、插入元素:列表中我们使用最多的是ArrayList,下面来看看它的插入(add方法)算法,源代码如下:

1 public void add(int index, E element) {
2 //检查下标是否越界
3 rangeCheckForAdd(index);
4 //若需要扩容,则增大底层数组的长度
5 ensureCapacityInternal(size + 1); // Increments modCount!!
6 //给index下标之后的元素(包括当前元素)的下标加1,空出index位置
7 System.arraycopy(elementData, index, elementData, index + 1,
8 size - index);
9 //赋值index位置元素
10 elementData[index] = element;
11 //列表长度加1
12 size++;
13 }

注意看arrayCopy方法,只要插入一个元素,其后的元素就会向后移动一位,虽然arrayCopy是一个本地方法,效率非常高,但频繁的插入,每次后面的元素都要拷贝一遍,效率就更低了,特别是在头位置插入元素时,现在的问题是,开发中确实会遇到要插入的元素的情况,哪有什么更好的方法解决此效率问题吗?
有,使用LinkedList即可。我么知道LinkedList是一个双向列表,它的插入只是修改了相邻元素的next和previous引用,其插入算法(add方法)如下:

1 public void add(int index, E element) {
2 checkPositionIndex(index);
3
4 if (index == size)
5 linkLast(element);
6 else
7 linkBefore(element, node(index));
8 }


1 void linkLast(E e) {
2 final Node<E> l = last;
3 final Node<E> newNode = new Node<>(l, e, null);
4 last = newNode;
5 if (l == null)
6 first = newNode;
7 else
8 l.next = newNode;
9 size++;
10 modCount++;
11 }


1 void linkBefore(E e, Node<E> succ) {
2 // assert succ != null;
3 final Node<E> pred = succ.prev;
4 final Node<E> newNode = new Node<>(pred, e, succ);
5 succ.prev = newNode;
6 if (pred == null)
7 first = newNode;
8 else
9 pred.next = newNode;
10 size++;
11 modCount++;
12 }

这个方法,第一步检查是否越界,下来判断插入元素的位置与列表的长度比较,如果相等,调用linkLast,否则调用linkBefore方法。但这两个方法的共同点都是双向链表插入算法,把自己插入到链表,然后再把前节点的next和后节点的previous指向自己。想想看,这样插入一个元素的过程中,没有任何元素会有拷贝过程,只是引用地址变了,那效率自然就高了。
(2)、删除元素:插入了解清楚了,我们再来看看删除动作。ArrayList提供了删除指定位置上的元素,删除指定元素,删除一个下标范围内的元素集等删除动作。三者的实现原理基本相似,都是找索引位置,然后删除。我们以最常用的删除指定下标的方法(remove方法)为例来看看删除动作的性能到底如何,源码如下:

1 public E remove(int index) {
2 //下标校验
3 rangeCheck(index);
4 //修改计数器加1
5 modCount++;
6 //记录要删除的元素
7 E oldValue = elementData(index);
8 //有多少个元素向前移动
9 int numMoved = size - index - 1;
10 if (numMoved > 0)
11 //index后的元素向前移动一位
12 System.arraycopy(elementData, index+1, elementData, index,
13 numMoved);
14 //列表长度减1
15 elementData[--size] = null; // Let gc do its work
16 //返回删除的值
17 return oldValue;
18 }

注意看,index位置后的元素都向前移动了一位,最后一个位置空出来了,这又是一个数组拷贝,和插入一样,如果数据量大,删除动作必然会暴露出性能和效率方面的问题。ArrayList其它的两个删除方法与此类似,不再赘述。
我么再来看LinkedList的删除动作。LinkedList提供了非常多的删除操作,比如删除指定位置元素,删除头元素等,与之相关的poll方法也会执行删除动作,下面来看最基本的删除指定位置元素的方法remove,源代码如下:
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
1 E unlink(Node<E> x) {
2 // assert x != null;
3 final E element = x.item;
4 final Node<E> next = x.next;
5 final Node<E> prev = x.prev;
6
7 if (prev == null) {
8 first = next;
9 } else {
10 prev.next = next;
11 x.prev = null;
12 }
13
14 if (next == null) {
15 last = prev;
16 } else {
17 next.prev = prev;
18 x.next = null;
19 }
20
21 x.item = null;
22 size--;
23 modCount++;
24 return element;
25 }


1 private static class Node<E> {
2 E item;
3 Node<E> next;
4 Node<E> prev;
5
6 Node(Node<E> prev, E element, Node<E> next) {
7 this.item = element;
8 this.next = next;
9 this.prev = prev;
10 }
11 }

这也是双向链表标准删除算法,没有任何耗时的操作,全部都是引用指针的变更,效率自然高了。
(3)、修改元素:写操作还有一个动作,修改元素值,在这一点上LinkedList输给了ArrayList,这是因为LinkedList是按顺序存储的,因此定位元素必然是一个遍历过程,效率大打折扣,我们来看Set方法的代码:

1 public E set(int index, E element) {
2 checkElementIndex(index);
3 //定位节点
4 Node<E> x = node(index);
5 E oldVal = x.item;
6 //节点元素替换
7 x.item = element;
8 return oldVal;
9 }

看似很简洁,但是这里使用了node方法定位元素,上一个建议中我们已经说明了LinkedList这种顺序存取列表的元素定位方式会折半遍历,这是一个极耗时的操作,而ArrayList的修改动作则是数组元素的直接替换,简单高效。
在修改动作上,LinkedList比ArrayList慢很多,特别是要进行大量的修改时,两者完全不在一个数量级上。
上面通过分析源码完成了LinkedList与ArrayList之间的PK,其中LinkedList胜两局:删除和插入效率高;ArrayList胜一局:修改元素效率高。总体来说,在写方面LinkedList占优势,而且在实际使用中,修改是一个比较少的动作。因此有大量写的操作(更多的是插入和删除),推荐使用LinkedList。不过何为少量?何为大量呢?
这就依赖于咱们在开发中系统了,具体情况具体分析了。
建议69:列表相等只关心元素数据
我们来看一个比较列表相等的例子,代码如下:

1 public class Client69 {
2 public static void main(String[] args) {
3 ArrayList<String> strs = new ArrayList<String>();
4 strs.add("A");
5
6 Vector<String> strs2 = new Vector<String>();
7 strs2.add("A");
8
9 System.out.println(strs.equals(strs2));
10 }
11 }

两个类都不同,一个是ArrayList,一个是Vector,那结果肯定不相等了。真是这样吗?但其实结果为true,也就是两者相等。
我们分析一下,两者为何相等,两者都是列表(List),都实现了List接口,也都继承了AbstractList抽象类,其equals方法是在AbstractList中定义的,我们来看源代码:

1 public boolean equals(Object o) {
2 if (o == this)
3 return true;
4 //是否是列表,注意这里:只要实现List接口即可
5 if (!(o instanceof List))
6 return false;
7 //通过迭代器访问List的所有元素
8 ListIterator<E> e1 = listIterator();
9 ListIterator e2 = ((List) o).listIterator();
10 //遍历两个List的元素
11 while (e1.hasNext() && e2.hasNext()) {
12 E o1 = e1.next();
13 Object o2 = e2.next();
14 //只要存在着不相等就退出
15 if (!(o1==null ? o2==null : o1.equals(o2)))
16 return false;
17 }
18 //长度是否也相等
19 return !(e1.hasNext() || e2.hasNext());
20 }

看到没,这里只要实现了List接口就成,它不关心List的具体实现类,只要所有元素相等,并且长度也相等就表明两个List是相等的,与具体的容量类型无关。也就是说,上面的例子虽然一个是Arraylist,一个是Vector,只要里面的元素相等,那结果也就相等。
Java如此处理也确实是在为开发者考虑,列表只是一个容器,只要是同一种类型的容器(如List),不用关心,容器的细节差别,只要确定所有的元素数据相等,那这两个列表就是相等的,如此一来,我们在开发中就不用太关注容器的细节了,可以把注意力更多地放在数据元素上,而且即使中途重构容器类型,也不会对相等的判断产生太大的影响。
其它的集合类型,如Set、Map等于此相同,也是只关心集合元素,不用考虑集合类型。
注意:判断集合是否相等时只须关注元素是否相等即可。
Atas ialah kandungan terperinci 编写高效代码(一) 关于数组和集合. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!