


3. 离线数据分析流程介绍
注:本环节主要感受数据分析系统的宏观概念及处理流程,初步理解hadoop等框架在其中的应用环节,不用过于关注代码细节
一个应用广泛的数据分析系统:“web日志数据挖掘”
3.1 需求分析
3.1.1 案例名称
“网站或APP点击流日志数据挖掘系统”。
3.1.2 案例需求描述
“Web点击流日志”包含着网站运营很重要的信息,通过日志分析,我们可以知道网站的访问量,哪个网页访问人数最多,哪个网页最有价值,广告转化率、访客的来源信息,访客的终端信息等。
3.1.3 数据来源
本案例的数据主要由用户的点击行为记录
获取方式:在页面预埋一段js程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发ajax请求到后台servlet程序,用log4j记录下事件信息,从而在web服务器(nginx、tomcat等)上形成不断增长的日志文件。
形如:
58.215.204.118 - - [18/Sep/2013:06:51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0" |
3.2 数据处理流程
3.2.1 流程图解析
本案例跟典型的BI系统极其类似,整体流程如下:

但是,由于本案例的前提是处理海量数据,因而,流程中各环节所使用的技术则跟传统BI完全不同,后续课程都会一一讲解:
1) 数据采集:定制开发采集程序,或使用开源框架FLUME
2) 数据预处理:定制开发mapreduce程序运行于hadoop集群
3) 数据仓库技术:基于hadoop之上的Hive
4) 数据导出:基于hadoop的sqoop数据导入导出工具
5) 数据可视化:定制开发web程序或使用kettle等产品
6) 整个过程的流程调度:hadoop生态圈中的oozie工具或其他类似开源产品
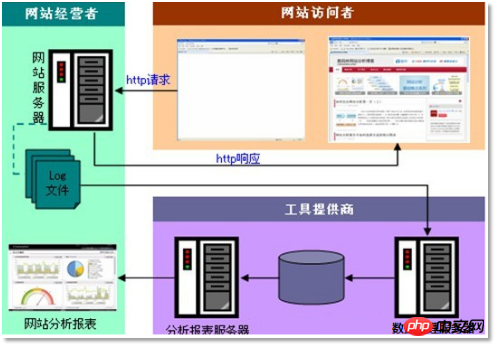
3.2.2 项目技术架构图

3.2.3 项目相关截图(感性认识,欣赏即可)
a) Mapreudce程序运行

b) 在Hive中查询数据

c) 将统计结果导入mysql
./sqoop export --connect jdbc:mysql://localhost:3306/weblogdb --username root --password root --table t_display_xx --export-dir /user/hive/warehouse/uv/dt=2014-08-03 |
3.3 项目最终效果
经过完整的数据处理流程后,会周期性输出各类统计指标的报表,在生产实践中,最终需要将这些报表数据以可视化的形式展现出来,本案例采用web程序来实现数据可视化
效果如下所示:

Atas ialah kandungan terperinci 离线数据分析流程介绍. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bagaimanakah saya menggunakan Maven atau Gradle untuk Pengurusan Projek Java Lanjutan, Membina Automasi, dan Resolusi Ketergantungan?Mar 17, 2025 pm 05:46 PM
Bagaimanakah saya menggunakan Maven atau Gradle untuk Pengurusan Projek Java Lanjutan, Membina Automasi, dan Resolusi Ketergantungan?Mar 17, 2025 pm 05:46 PMArtikel ini membincangkan menggunakan Maven dan Gradle untuk Pengurusan Projek Java, membina automasi, dan resolusi pergantungan, membandingkan pendekatan dan strategi pengoptimuman mereka.
 Bagaimanakah saya membuat dan menggunakan perpustakaan Java Custom (fail JAR) dengan pengurusan versi dan pergantungan yang betul?Mar 17, 2025 pm 05:45 PM
Bagaimanakah saya membuat dan menggunakan perpustakaan Java Custom (fail JAR) dengan pengurusan versi dan pergantungan yang betul?Mar 17, 2025 pm 05:45 PMArtikel ini membincangkan membuat dan menggunakan perpustakaan Java tersuai (fail balang) dengan pengurusan versi dan pergantungan yang betul, menggunakan alat seperti Maven dan Gradle.
 Bagaimanakah saya melaksanakan caching pelbagai peringkat dalam aplikasi java menggunakan perpustakaan seperti kafein atau cache jambu?Mar 17, 2025 pm 05:44 PM
Bagaimanakah saya melaksanakan caching pelbagai peringkat dalam aplikasi java menggunakan perpustakaan seperti kafein atau cache jambu?Mar 17, 2025 pm 05:44 PMArtikel ini membincangkan pelaksanaan caching pelbagai peringkat di Java menggunakan kafein dan cache jambu untuk meningkatkan prestasi aplikasi. Ia meliputi persediaan, integrasi, dan faedah prestasi, bersama -sama dengan Pengurusan Dasar Konfigurasi dan Pengusiran PRA Terbaik
 Bagaimanakah saya boleh menggunakan JPA (Java Constence API) untuk pemetaan objek-objek dengan ciri-ciri canggih seperti caching dan malas malas?Mar 17, 2025 pm 05:43 PM
Bagaimanakah saya boleh menggunakan JPA (Java Constence API) untuk pemetaan objek-objek dengan ciri-ciri canggih seperti caching dan malas malas?Mar 17, 2025 pm 05:43 PMArtikel ini membincangkan menggunakan JPA untuk pemetaan objek-relasi dengan ciri-ciri canggih seperti caching dan pemuatan malas. Ia meliputi persediaan, pemetaan entiti, dan amalan terbaik untuk mengoptimumkan prestasi sambil menonjolkan potensi perangkap. [159 aksara]
 Bagaimanakah mekanisme kelas muatan Java berfungsi, termasuk kelas yang berbeza dan model delegasi mereka?Mar 17, 2025 pm 05:35 PM
Bagaimanakah mekanisme kelas muatan Java berfungsi, termasuk kelas yang berbeza dan model delegasi mereka?Mar 17, 2025 pm 05:35 PMKelas kelas Java melibatkan pemuatan, menghubungkan, dan memulakan kelas menggunakan sistem hierarki dengan bootstrap, lanjutan, dan pemuat kelas aplikasi. Model delegasi induk memastikan kelas teras dimuatkan dahulu, yang mempengaruhi LOA kelas tersuai


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

Dreamweaver Mac版
Alat pembangunan web visual

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

