
Rumah >pembangunan bahagian belakang >tutorial php >Windows下怎么安装tesseract-ocr 4.00并配置?
Windows下怎么安装tesseract-ocr 4.00并配置?

- 零下一度asal
- 2017-06-23 14:09:145099semak imbas
最近要做文字识别,不让直接用别人的接口,所以只能尝试去用开源的类库。tesseract-ocr是惠普公司开源的一个文字识别项目,通过它可以快速搭建图文识别系统,帮助我们开发出能识别图片的ocr系统。因为Windows环境开发,我也就必须在windows环境安装系统。
第一步:下载安装包
根据,我找到非官方的安装包,好像我只看到64位的安装包http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe,下载后直接安装即可,但是要记得你的安装目录,我们等会配置环境变量要用。
如果不是做英文的图文识别,还需要下载其他语言的识别包。
简体字识别包:
繁体字识别包:
第二步:安装
直接执行下载好的tesseract-ocr-setup-4.00.00dev.exe,下一步、下一步安装。
第三步:配置环境变量
注意:我的系统是win7,其他系统应该差不多,跟配置java变量一样
复制你的安装地址,我的是安装在C:\Program Files (x86)\Tesseract-OCR,界面如下:
复制安装路径“C:\Program Files (x86)\Tesseract-OCR”,进入“控制面板\系统和安全\系统”,点击
“系统保护”

进入到以下界面:
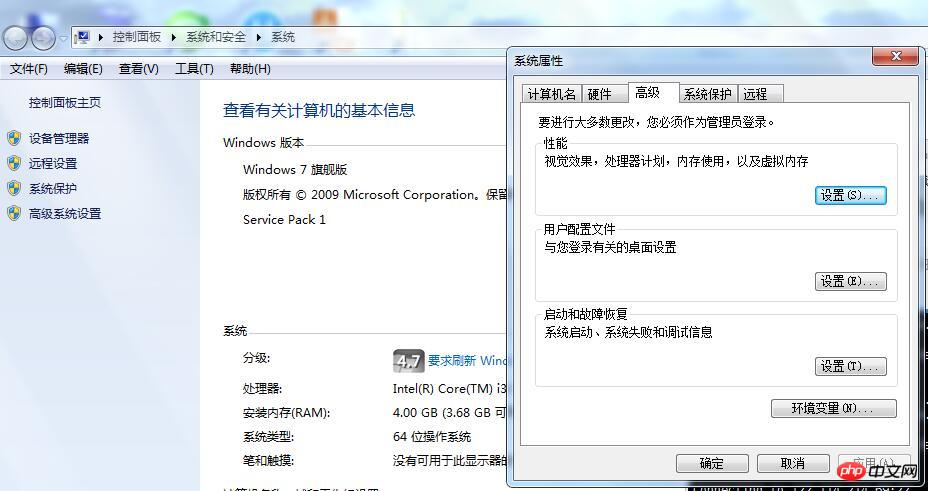
点击环境变量,进入配置以下界面:
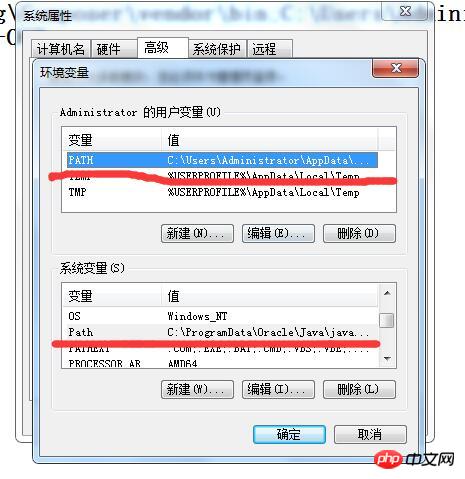
把刚才的安装路径“C:\Program Files (x86)\Tesseract-OCR”添加到红线划的PATH和Path,注意,添加时候开头用“;”跟之前的变量隔开,结尾以“;”结尾。下面是我的配置信息样本:
C:\Users\Administrator\AppData\Roaming\Composer\vendor\bin;C:\Users\Administrator\AppData\Roaming\npm;C:\Program Files (x86)\Tesseract-OCR;
配置好了点击保存。
打开命令终端,输入:tesseract -v,可以看到版本信息

如果出现报错,估计是环境变量没配置好。
到这里,我们就算安装完成了,但是,我们的系统还是无法识别中文的,我们要去下载简体汉字、繁体汉字语言包(上文给了地址了),下载好之后放到安装目录的tessconfigs目录下即可。
补充:因为没有配置全局变量,无法跨盘执行数据转换,这里我们在环境变量那增加一个配置信息
系统变量—->新建:

增加一个TESSDATA_PREFIX变量名,变量值还是我的安装路径C:\Program Files (x86)\Tesseract-OCR;
Atas ialah kandungan terperinci Windows下怎么安装tesseract-ocr 4.00并配置?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Semua simbol ungkapan dalam ungkapan biasa (ringkasan)