
Rumah >Java >javaTutorial >java序列化存取实现对象克隆的实例详解
java序列化存取实现对象克隆的实例详解

- Y2Jasal
- 2017-04-26 10:05:301347semak imbas
本篇文章是对序列化存取实现java对象深度克隆的方法进行了详细的分析介绍,需要的朋友参考下
我们知道,在java中,将一个非原型类型类型的对象引用,赋值给另一个对象的引用之后,这两个引用就指向了同一个对象,如:
代码如下:
public class DeepCloneTest { private class CloneTest { private Long myLong = new Long(1); } public static void main(String args[]) { new DeepCloneTest().Test(); } public void Test() { CloneTest ct1 = new CloneTest(); CloneTest ct2 = ct1; // to see if ct1 and ct2 are one same reference. System.out.println("ct1: " + ct1); System.out.println("ct2: " + ct2); // if ct1 and ct2 point to one same object, then ct1.myLong == ct2.myLong. System.out.println("ct1.myLong: " + ct1.myLong); System.out.println("ct2.myLong: " + ct2.myLong); // we change ct2's myLong ct2.myLong = 2L; // to see whether ct1's myLong was changed. System.out.println("ct1.myLong: " + ct1.myLong); System.out.println("ct2.myLong: " + ct2.myLong); }}out put:
ct1: DeepCloneTest$CloneTest@c17164
ct2: DeepCloneTest$CloneTest@c17164
ct1.myLong: 1
ct2.myLong: 1
ct1.myLong: 2
ct2.myLong: 2
这个很easy,估计学java的都知道(不知道的是学java的么?)。
在内存中,对象的引用存放在栈中,对象的数据,存放在堆中,栈中的引用指向了堆中的对象。这里就是两个栈中的引用,指向了堆中的同一个对象,所以,当改变了 ct2 的 myLong,可以看到,ct1 的 myLong 值也随之改变,如果用图来表示,就很容易理解了:
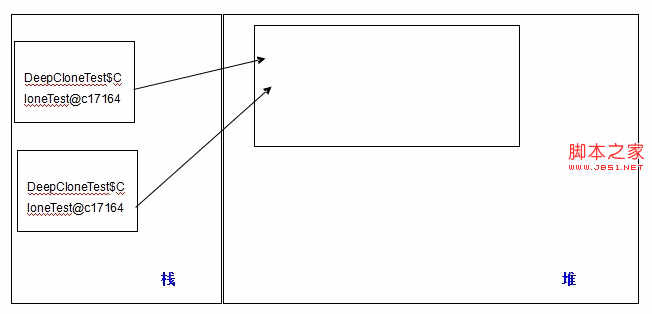
左边的是栈区,该区中有两个引用,值相同,它们指向了右边堆区的同一个对象。
大多时候,我们会用 java 语言的这一特性做我们想做的事情,比如,将对象的引用作为入参传入一个方法中,在方法中,对引用所指对象做相应修改。但有时,我们希望构造出一个和已经存在的对象具有完全相同的内容,但引用不同的对象,为此,可以这样做:
代码如下:
public class DeepCloneTest{ // must implements Cloneable. private class CloneTest implements Cloneable{ private Object o = new Object(); public CloneTest clone() { CloneTest ct = null; try { ct = (CloneTest)super.clone(); } catch (CloneNotSupportedException e) { e.printStackTrace(); } return ct; } } public static void main(String args[]) { new DeepCloneTest().Test(); } public void Test() { CloneTest ct1 = new CloneTest(); CloneTest ct2 = ct1.clone(); // to see if ct1 and ct2 are one same reference. System.out.println("ct1: " + ct1); System.out.println("ct2: " + ct2); // whether ct1.o == ct2.o ? yes System.out.println("ct1.o " + ct1.o); System.out.println("ct1.o " + ct1.o); }}out put:
ct1: DeepCloneTest$CloneTest@c17164
ct2: DeepCloneTest$CloneTest@1fb8ee3
ct1.o java.lang.Object@61de33
ct1.o java.lang.Object@61de33
从输出可以看出:ct1 和 ct2 确实是两个不同的引用,所以我们想当然的认为,ct1.o 和 ct2.o 也是两个不同的对象了,但从输出可以看出并非如此!ct1.o 和 ct2.o 是同一个对象!原因在于,虽然用到了克隆,但上面只是浅度克隆,用图形来表示: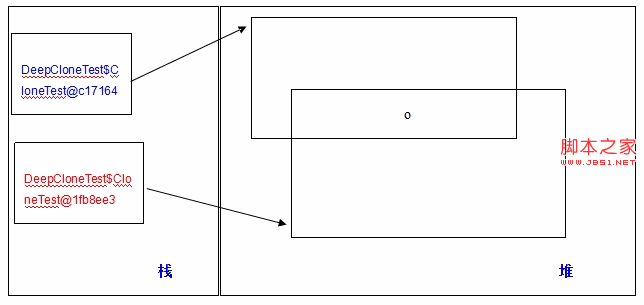
看到上面的 o 了么?其实是两个对象共享的。这就相当于,你本来有一个羊圈1,里面有一只羊,然后你又弄了一个羊圈2,在不将羊从羊圈1里牵出来的情况下,将羊也圈在了羊圈2中,你以为你有两条羊了,其实呢?大家都知道。
这就是浅度克隆的结果:如果你想让两个对象具有独立的 o,就必须再对 o 做克隆操作。可能有些人认为这没有什么,做就做呗,但想过没有,如果不止一个 o, 还有很多很多的类似 o 的东东,你都逐一去做克隆吗?显然是不太现实的。
一种解决方法是:将对象先序列化存储到流中,然后再从留中读出对象,这样就可以保证读取出来的数据和之前的对象,里面的值完全相同,就像是一个完全的拷贝。
代码如下:
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
public class DeepCloneTest {
// must implements Cloneable.
private class CloneTest implements Serializable{
private static final long serialVersionUID = 1L;
private Object o = new Object();
public CloneTest deepClone() {
CloneTest ct = null;
try {
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(this);
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois= new ObjectInputStream(bais);
ct = (CloneTest)ois.readObject();
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
return ct;
}
}
public static void main(String args[]) {
new DeepCloneTest().Test();
}
public void Test() {
CloneTest ct1 = new CloneTest();
CloneTest ct2 = ct1.deepClone();
// to see if ct1 and ct2 are one same reference.
System.out.println("ct1: " + ct1);
System.out.println("ct2: " + ct2);
// whether ct1.o == ct2.o ? no
System.out.println("ct1.o " + ct1.o);
System.out.println("ct1.o " + ct1.o);
}
}
这个时候,内存中的数据就是这样的了:
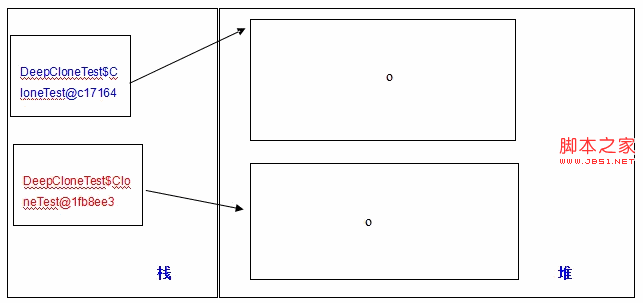
克隆任务完成。
Atas ialah kandungan terperinci java序列化存取实现对象克隆的实例详解. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!