
Rumah >pembangunan bahagian belakang >Tutorial Python >python解析XML文件实例(图)
python解析XML文件实例(图)

- PHPzasal
- 2017-04-23 16:44:513420semak imbas
如下使用xml.etree.ElementTree模块来解析XML文件。ElementTree模块中提供了两个类用来完成这个目的:
ElementTree 表示整个XML文件(一个树形结构)
Element 表示树中的一个元素(结点)
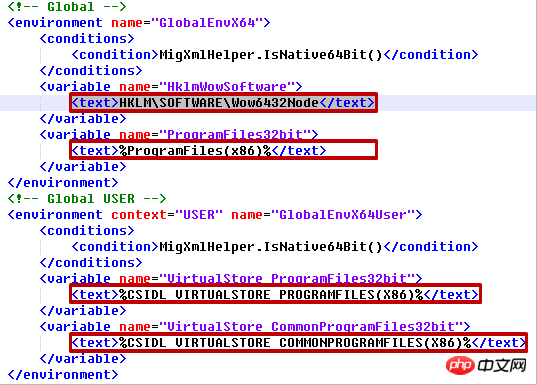
我们操作如下XML文件: migapp.xml

我们可以通过如下方式导入ElementTree模块: import xml.etree.ElementTree as ET
或者也可以仅导入parse解析器: from xml.etree.ElementTree import parse
首先需要打开一个xml文件,本地文件使用open函数,如果是互联网文件,则使用urlopen:
f = open( ' migapp.xml ' , ' rt ' , encoding= ' utf-8 ' )
然后对XML进行解析。
1 解析XML文件
1.1 解析根元素
tree = ET.parse(f) root = tree.getroot() print('root.tag =', root.tag) print('root.attrib =', root.attrib)

1.2 解析根的儿子
for child in root: # 仅可以解析出root的儿子,不能解析出root的子孙
print(child.tag)
print(child.attrib) # attrib is a dict
1.3 通过索引解析根的子孙
print(root[1][1].tag) print(root[1][1].text)

1.4 迭代解析出所有的指定element
for element in root.iter('environment'):
print(element.attrib)

1.5 几个有用的方法
# element.findall()解析出指定element的所有儿子
# element.find()解析出指定element的第一个儿子
# element.get()解析出指定element的属性attrib
for environment in root.findall('environment'):
first_variable = environment.find('variable')
print(first_variable.get('name'))
2 修改XML文件
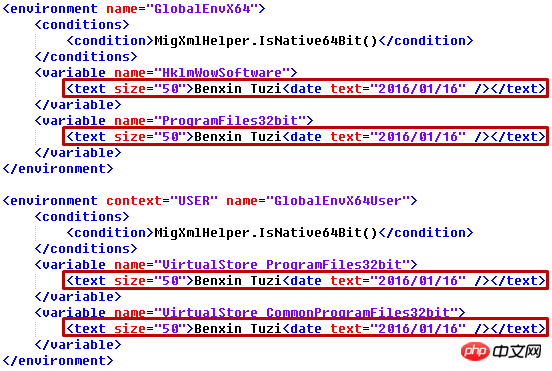
假设我们需要给每个text元素添加一个属性size="50",修改其text为"Benxin Tuzi",添加一个子元素date="2016/01/16"
for text in root.iter('text'):
text.set('size', '50')
text.text = 'Benxin Tuzi'
text.append(ET.Element('date', attrib={}, text='2016/01/16'))
tree.write('output.xml')migapp.xml 中的部分:
output.xml 中对应的部分:
3 说明事项
不要使用xml.py作为文件名,否则此时会发生如下错误:
ImportError: No module named 'xml.etree'; 'xml' is not a package
分析:
这是由于import时会先在当前路径下寻找,此时发现存在xml.py模块,而我们自己写的xml.py当然不是一个package
注意:
删除xml.py后仍然不能成功解释,那是因为当前路径中还生成了xml.pyc,而该文件的优先级要高于xml.py,因此解释器还是优先在xml.pyc中寻找,因此必须将该文件也删除掉,成功解决问题。
结论:
文件名尽量不要与包名或者模块名同名,即使你在脚本中不使用该模块或者包,否则可能发生奇怪的错误。
ElementTree模块中提供的很多解析函数都需要预先将整个XML文档读入内存中,这对于大型XML解析而言,不是一件好事,尤其是当我们从网络、管道中读取XML时,非阻塞式的解析非常重要。此时,我们可以使用ElementTree模块中的XMLPullParse类来处理。当然我们也可以选择ElementTree模块的iterparse()来代替,该方法在解析大型XML时也不需要全部读入内存。
Atas ialah kandungan terperinci python解析XML文件实例(图). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!