
Rumah >pembangunan bahagian belakang >Tutorial C#.Net >模拟HTTP请求实现网页自动操作及数据采集的方法
模拟HTTP请求实现网页自动操作及数据采集的方法

- Y2Jasal
- 2017-04-20 17:26:433076semak imbas
下面小编就为大家带来一篇模拟HTTP请求实现网页自动操作及数据采集的方法。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧
前言
网页可分为信息提供和业务操作类,信息提供如新闻、股票行情之类的网站。业务操作如网上营业厅、OA之类的。当然,也有很多网站同时具有这两种性质,像微博、豆瓣、淘宝这类网站,既提供信息,也实现某些业务。
普通上网方式一般都是手动操作(这个不需要解释:D)。但有时候人工手动操作的方式可能就无法胜任了,如爬取网络上大量数据,实时监测某个页面的变化,批量操作业务(如批量发微博,批量淘宝购物)、刷单等。由于操作量大,而且都是重复的操作,人工操作效率低下,且易出错。这时候就可以使用软件来自动操作了。
本人开发过多个这类软件,有网络爬虫、自动批量操作业务这类的。其中使用到的一个核心功能就是模拟HTTP请求。当然,有时会使用HTTPS协议,而且网站一般需要登陆后才能进一步操作,还有最重要的一点就是弄清楚网站的业务流程,即知道为了实现某个操作该在什么时候向哪个页面以什么方式提交什么数据,最后,要提取数据或知道操作结果,就还需要解析HTML。本文将一一阐述。
本文使用C#语言来展示代码,当然也可以用其它语言实现,原理是一样的。以登陆京东为实例。
模拟HTTP请求
C#模拟HTTP请求需要使用到如下类:
•WebRequest
•HttpWebRequest
•HttpWebResponse
•Stream
先创建一个请求对象(HttpWebRequest),设置相关的Headers信息后发送请求(如果是POST,还要把表单数据写入网络流),如果目标地址可访问,会得到一个响应对象(HttpWebResponse),从相应对象的网络流中就可读出返回结果。
示例代码如下:
String contentType = "application/x-www-form-urlencoded";
String accept = "image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/x-silverlight,
application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-ms-application, application/x-ms-xbap,
application/vnd.ms-xpsdocument, application/xaml+xml, application/x-silverlight-2-b1, */*";
String userAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36";
public String Get(String url, String encode = DEFAULT_ENCODE)
{
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "GET";
var html = ReadHtml(request, encode);
return html;
}
public String Post(String url, String param, String encode = DEFAULT_ENCODE)
{
Encoding encoding = System.Text.Encoding.UTF8;
byte[] data = encoding.GetBytes(param);
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "POST";
request.ContentLength = data.Length;
var outstream = request.GetRequestStream();
outstream.Write(data, 0, data.Length);
var html = ReadHtml(request, encode);
return html;
}
private void InitHttpWebRequestHeaders(HttpWebRequest request)
{
request.ContentType = contentType;
request.Accept = accept;
request.UserAgent = userAgent;
}
private String ReadHtml(HttpWebRequest request, String encode)
{
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.GetEncoding(encode));
String content = reader.ReadToEnd();
reader.Close();
stream.Close();
return content;
}可以看出,Get和Post方法的代码大部分都相似,所以代码进行了封装,提取了相同代码作为新的函数。
HTTPS请求
当网站使用https协议时,以上代码就可能会出现以下错误:
The underlying connection was closed: Could not establish trust relationship for
原因是证书错误,用浏览器打开会出现如下页面:
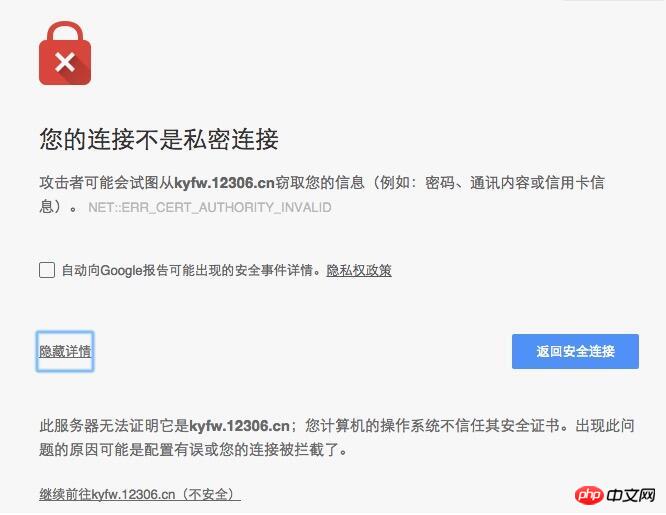
当点击继续前往xxx.xx(不安全)时,就可继续打开网页。在程序中,也只要模拟这一步就可以继续了。C#中只需设置ServicePointManager.ServerCertificateValidationCallback代理,在代理方法中直接返回true就行了。
private HttpWebRequest CreateHttpWebRequest(String url)
{
HttpWebRequest request;
if (IsHttpsProtocol(url))
{
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(CheckValidationResult);
request = WebRequest.Create(url) as HttpWebRequest;
request.ProtocolVersion = HttpVersion.Version10;
}
else
{
request = WebRequest.Create(url) as HttpWebRequest;
}
return request;
}
private HttpWebRequest CreateHttpWebRequest(String url)
{
HttpWebRequest request;
if (IsHttpsProtocol(url))
{
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(CheckValidationResult);
request = WebRequest.Create(url) as HttpWebRequest;
request.ProtocolVersion = HttpVersion.Version10;
}
else
{
request = WebRequest.Create(url) as HttpWebRequest;
}
return request;
}这样,就可正常访问https网站了。
记录Cookies实现身份认证
有些网站需要登录才能执行下一步操作,比如在京东购物需要先登录。网站服务器使用session来记录客户端用户,每一个session对应一个用户,而前面的代码每次创建一个请求都会重新建立一个session。即使登录成功,在执行下一步操作由于新创建了一个连接,登录也是无效的。这时就得想办法让服务器认为这一系列的请求来自同一个session。
客户端只有Cookies,为了在下次请求的时候让服务器知道该客户端对应哪个session,Cookies中会有一个记录session ID的记录。所以,只要Cookies相同,对服务器来说就是同一个用户。
这时需要使用到CookieContainer,顾名思义,这就是一个Cookies容器。HttpWebRequest有一个CookieContainer属性。只要把每次请求的Cookies都记录在CookieContainer,下次请求时设置HttpWebRequest的CookieContainer属性,由于Cookies相同,对于服务器来说就是同一个用户了。
public String Get(String url, String encode = DEFAULT_ENCODE)
{
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "GET";
request.CookieContainer = cookieContainer;
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
foreach (Cookie c in response.Cookies)
{
cookieContainer.Add(c);
}
}分析调试网站
以上就实现了模拟HTTP请求,当然,最重要的还是分析站。一般的情况都是没有文档、找不到网站开发人员,从一个黑盒子开始探索。分析工具有很多,推荐使用Chrome+插件Advanced Rest Client,Chrome的开发者工具能让我们知道打开一个网页时后台做了哪些操作与请求,Advanced Rest Client可模拟发送请求。
比如在登录京东时,会提交如下数据:
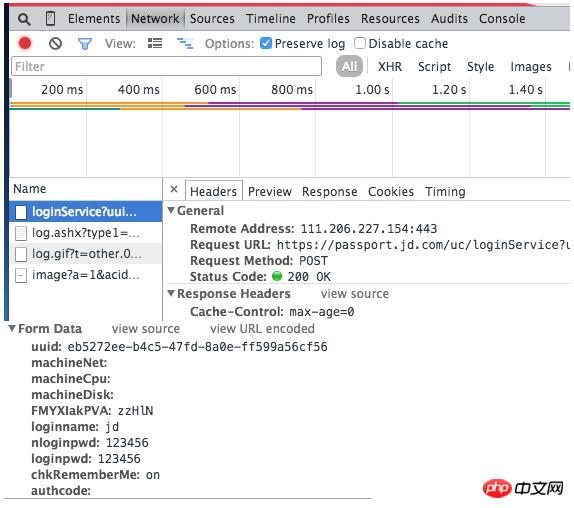
我们还能看到京东的密码居然是明文传输,安全性很让人担心啊!
还能看到返回的数据:

返回的是JSON数据,不过\u8d26这些是什么?其实这是Unicode编码,使用Unicode编码转换工具,即可转换成可读的文字,比如这次返回的结果是:账户名与密码不匹配,请重新输入。
解析HTML
HTTP请求获得的数据一般是HTML格式,有时也可能是Json或XML。需要解析才能提取有用数据。解析HTML的组件有:
•HTML Parser。多个平台可用,如Java/C#/Python。很久没用了。
•HtmlAgilityPack。通过通过XPath来解析HMTL。一直使用。 关于XPath教程,可以看W3School的XPath教程。
结语
本文介绍了开发模拟自动网页操作所需要的技能,从模拟HTTP/HTTPS请求,到Cookies、分析网站、解析HTML。代码旨在说明使用方法,并非完整代码,可能无法直接运行。
Atas ialah kandungan terperinci 模拟HTTP请求实现网页自动操作及数据采集的方法. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!