
Rumah >pembangunan bahagian belakang >Tutorial XML/RSS >XML中的树形结构与DOM文档对象模型的示例代码(图)
XML中的树形结构与DOM文档对象模型的示例代码(图)

- 黄舟asal
- 2017-03-10 19:26:212081semak imbas
这篇文章主要介绍了XML中的树形结构与DOM文档对象模型,文中举了JavaScript解析DOM对象的例子,需要的朋友可以参考下
树结构
XML 文档始终是描述性的。树状结构通常被称为 XML 树,它在描述 XML 文档的过程中扮演一个重要的角色。
这个树结构包含根(父)元素,子元素等等。通过使用树状结构,我们可以了解源自根元素的所有后续分支和子分支。解析从根元素开始,然后向下移动到指向某个元素的第一个分支,从这里开始处理第一个分支及其子节点。
示例
下面的示例演示了简单的 XML 树结构:
<?xml version="1.0"?>
<Company>
<Employee>
<FirstName>Tanmay</FirstName>
<LastName>Patil</LastName>
<ContactNo>1234567890</ContactNo>
<Email>tanmaypatil@xyz.com</Email>
<Address>
<City>Bangalore</City>
<State>Karnataka</State>
<Zip>560212</Zip>
</Address>
</Employee>
</Company>
下面的树结构表示上面的 XML 文档: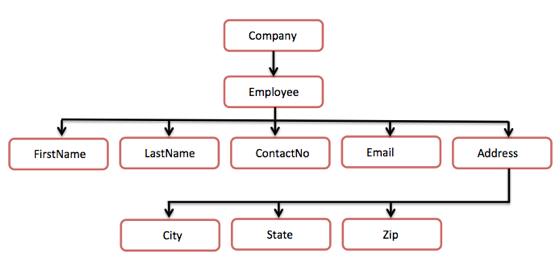
图中,有一个叫做 32c3713aa2138e0cde00114c704ab347 的根元素。里面又有一个 a7c15504e26c2dc9d33fa17ec3230b5f 元素。在雇员元素里面,又有 5 个分支,分别是 f2e90542b5a58058db8f193d5beb15a8,59167353502e8b7287d6dd485f7f1057,ee8c75b84e5f6309a3ff5787a453f502,d9a1fb039fef8fc6c3cf193249481d23 和 f2d2d42736253fc13ad1661a02a3d5ac。在 f2d2d42736253fc13ad1661a02a3d5ac 元素内,又有三个子分支,分别是 6c132ff3bb7a6c407d7ed87f2557a5a4,c29070a8b11e875ca4756dbf4d49d8f9 和 d2d7d3a911f6decdbaf6e47c4f11276f。
DOM文档对象模型
文档对象模型(DOM)是 XML 的基础。XML 文档有一个信息层次结构单位,被称作节点;DOM 是描述这些节点和它们之间关系的一种方式。
DOM 文档就是一个节点集合或者按照层次结构组织的信息块。这个层次结构允许开发人员导航这个节点树来查询特定的信息。由于它基于信息层次结构,DOM 也被认为是_基于节点树_的。
另一方面,XML DOM 还提供了一个 API,允许开发者在节点树的任意位置添加,编辑,移动或者移除节点,以便创建应用程序。
示例
下面的示例(sample.htm)将一个 XML 文档("address.xml")解析为一个 XML DOM 对象,然后用 JavaScript 提取了一些信息:
<!DOCTYPE html>
<html>
<body>
<h1>TutorialsPoint DOM example </h1>
<div>
<b>Name:</b> <span id="name"></span><br>
<b>Company:</b> <span id="company"></span><br>
<b>Phone:</b> <span id="phone"></span>
</div>
<script>
if (window.XMLHttpRequest) {// code for IE7+, Firefox, Chrome, Opera, Safari
xmlhttp = new XMLHttpRequest();
} else {// code for IE6, IE5
xmlhttp = new ActiveXObject("Microsoft.XMLHTTP");
}
xmlhttp.open("GET","/xml/address.xml",false);
xmlhttp.send();
xmlDoc=xmlhttp.responseXML;
document.getElementById("name").innerHTML=
xmlDoc.getElementsByTagName("name")[0].childNodes[0].nodeValue;
document.getElementById("company").innerHTML=
xmlDoc.getElementsByTagName("company")[0].childNodes[0].nodeValue;
document.getElementById("phone").innerHTML=
xmlDoc.getElementsByTagName("phone")[0].childNodes[0].nodeValue;
</script>
</body
</html>
address.xml 的内容如下:
<?xml version="1.0"?>
<contact-info>
<name>Tanmay Patil</name>
<company>TutorialsPoint</company>
<phone>(011) 123-4567</phone>
</contact-info>
我们可以把这两个文 sample.htm 和 address.xml 件保存到同一目录 /xml 中,然后通过在浏览器中打开的方式执行 sample.htm 文件。它应该生成如下所示结果:
这里,可以看到我们提取了每个子节点并显示了它们的值。
Atas ialah kandungan terperinci XML中的树形结构与DOM文档对象模型的示例代码(图). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!