
Rumah >pangkalan data >tutorial mysql >Mysql优化实验(一)-- 分区
Mysql优化实验(一)-- 分区

- 黄舟asal
- 2017-02-28 13:43:041845semak imbas
开发项目过程中总是提到优化的概念,本篇文章是对Mysql数据优化实践的一次探索旅程,简要介绍了分区原因,方法,分区表管理方法和一次简单的实践。
【为什么分区】
在大数据操作时,将数据表分而治之,将一张数据量很大的表分为一个更小的操作单元,每一个操作单元都会有一个单独的名称。同时,对于程序开发人员来说,分区和没有分区是一样的,通俗来说,mysql分区对于程序应用是透明的,只是数据库对数据的一次重新整理操作。
分区作用:
(1)提升性能。
分区的最终目的是提升性能,分区完成后,mysql针对每个分区生成特定数据文件和索引文件,检索时通过检索特定的部分数据,因此更好的执行和维护数据库。这是因为分区后表被指派到不同的物理驱动器上,同时访问多个分区时减少分区物理I/O争用。
(2)易于管理。
分区后,管理数据可以直接管理对应的分区。操作简单,当数据达到百万级别时,直接操作分区远比操作数据表来的更加直接。
(3)容错
分区完成后,一个分区被破坏后,不会影响其他数据。
【分区方法】
mysql 的分区方法有:RANGE分区、LIST分区、HASH分区、KEY分区。
RANGE分区:根据某个字段的值来进行分区管理,是在直接创建表时进行的分区。eg:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date, salary int ) partition by range(salary) ( partition p1 values less than (1000), partition p2 values less than (2000), partition p3 values less than maxvalue );
LIST分区:类似于RANG分区,不同的是,list分区是一个个散列值,RANG分区是根据某个字段范围进行分区。eg:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by list(deptno) ( partition p1 values in (10,15), partition p2 values in (20,25), partition p3 values in (30,35) );
HASH分区:确保数据在预先指定书目的分区中平均分布,分区时指定分区根据的列值和分区数量。eg:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by hash(year(birthdate)) partitions 4;
KEY分区:类似于HASH分区,区别于KEY分区只支持计算一列或多列,MySQL服务器提供其自身哈希函数,必须有一列或者多列包涵整数值。eg:
create table emp (empno varchar(20) not null , empname varchar(20), deptno int, birthdate date not null, salary int ) partition by key(birthdate) partitions 4;
【分区的管理操作方法】
删除分区:
alter table emp drop partition p1;
不可以删除hash或者key分区。
一次性删除多个分区,alter table emp drop partition p1,p2;
增加分区:
alter table emp add partition (partition p3 values less than (4000));
alter table empl add partition (partition p3 values in (40));
分解分区:
Reorganizepartition关键字可以对表的部分分区或全部分区进行修改,并且不会丢失数据。分解前后分区的整体范围应该一致。
alter table te
reorganize partition p1 into
(
partition p1 values less than (100),
partition p3 values less than (1000)
); ----不会丢失数据
合并分区:
Merge分区:把2个分区合并为一个。
alter table te
reorganize partition p1,p3 into
(partition p1 values less than (1000));
----不会丢失数据
重新定义hash分区表:
Alter table emp partition by hash(salary)partitions 7;
----不会丢失数据
重新定义range分区表:
Alter table emp partitionbyrange(salary)
(
partition p1 values less than (2000),
partition p2 values less than (4000)
); ----不会丢失数据
删除表的所有分区:
Alter table emp removepartitioning;--不会丢失数据
重建分区:
这和先删除保存在分区中的所有记录,然后重新插入它们,具有同样的效果。它可用于整理分区碎片。
ALTER TABLE emp rebuild partitionp1,p2;
优化分区:
如果从分区中删除了大量的行,或者对一个带有可变长度的行(也就是说,有VARCHAR,BLOB,或TEXT类型的列)作了许多修改,可以使用“ALTER TABLE ... OPTIMIZE PARTITION”来收回没有使用的空间,并整理分区数据文件的碎片。
ALTER TABLE emp optimize partition p1,p2;
分析分区:
读取并保存分区的键分布。
ALTER TABLE emp analyze partition p1,p2;
修补分区:
修补被破坏的分区。
ALTER TABLE emp repairpartition p1,p2;
检查分区:
可以使用几乎与对非分区表使用CHECK TABLE 相同的方式检查分区。
ALTER TABLE emp CHECK partition p1,p2;
这个命令可以告诉你表emp的分区p1,p2中的数据或索引是否已经被破坏。如果发生了这种情况,使用“ALTER TABLE ... REPAIR PARTITION”来修补该分区。
【分区实践】
1. 创建分区表和不分区表:
-- 创建分区表 CREATE TABLE part_tab (c1 int NULL, c2 VARCHAR(30), c3 date not null) PARTITION BY RANGE(year(c3)) (PARTITION p0 VALUES LESS THAN (1995), PARTITION p1 VALUES LESS THAN (1996) , PARTITION p2 VALUES LESS THAN (1997) , PARTITION p3 VALUES LESS THAN (1998) , PARTITION p4 VALUES LESS THAN (1999) , PARTITION p5 VALUES LESS THAN (2000) , PARTITION p6 VALUES LESS THAN (2001) , PARTITION p7 VALUES LESS THAN (2002) , PARTITION p8 VALUES LESS THAN (2003) , PARTITION p9 VALUES LESS THAN (2004) , PARTITION p10 VALUES LESS THAN (2010), PARTITION p11 VALUES LESS THAN (MAXVALUE) );
-- 创建没有分区表 CREATE TABLE nopart_tab (c1 int NULL, c2 VARCHAR(30), c3 date not null)
2. 创建大数据操作环境。为了测试结果的准确度提高,需要表中存在大数据,通过以下事务可在数据表中创建800万条数据:
-- 创建生成数据事物
CREATE PROCEDURE load_part_tab()
begin
declare v int default 0;
while v < 8000000
do
insert into part_tab
values (v,'testingpartitions',adddate('1995-01-01',(rand(v)*36520)mod 3652));
set v = v + 1;
end while;
end;
执行事务:call load_part_tab(); ,因为执行此事务执行的时间很长,我只在表中插入了283304条数据。
创建完成一张表后,可以将该表的数据复制到未分区表,这样执行速度会很快:
insert into test.nopart_tab select * from test.part_tab
3. 查看分区表分区结构:
-- 查询分区情况 select partition_name part, partition_expression expr, partition_description descr, table_rows from information_schema.partitions where table_schema = schema() and table_name='part_tab';
执行结果:
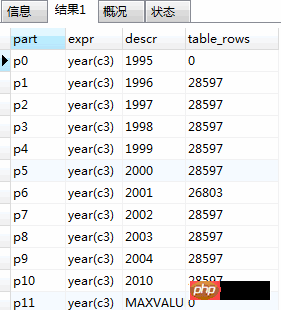
3. 测试速度:
执行分区表查询语句:
select count(*) from part_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
执行时间:

执行未分区表查询语句:
select count(*) from nopart_tab where c3 > date '1995-01-01'and c3 < date '1995-12-31';
执行时间:

从时间对比可以看出,同样的查询语句,分区表执行速度在20ms左右,未分区表在175ms左右,执行速度相差8倍左右,因此得出结论:分区表的执行速度要比未分区表执行速度快。
【分区局限性】
1. MySQL分区处理NULL值的方式
如果分区键所在列没有notnull约束。
如果是range分区表,那么null行将被保存在范围最小的分区。
如果是list分区表,那么null行将被保存到list为0的分区。
在按HASH和KEY分区的情况下,任何产生NULL值的表达式mysql都视同它的返回值为0。
为了避免这种情况的产生,建议分区键设置成NOT NULL。
2. 分区键必须是INT类型,或者通过表达式返回INT类型,可以为NULL。唯一的例外是当分
区类型为KEY分区的时候,可以使用其他类型的列作为分区键( BLOB or TEXT 列除外)。
3. 对分区表的分区键创建索引,那么这个索引也将被分区,分区键没有全局索引一说。
4. 只有RANG和LIST分区能进行子分区,HASH和KEY分区不能进行子分区。
5. 临时表不能被分区。
以上就是Mysql优化实验(一)-- 分区的内容,更多相关内容请关注PHP中文网(www.php.cn)!