
Rumah >pangkalan data >tutorial mysql >mysql如何删除表中的重复行并保留id较小(或者较大)的记录
mysql如何删除表中的重复行并保留id较小(或者较大)的记录

- 黄舟asal
- 2017-02-27 13:09:271321semak imbas
在实际录入数据库的过程中,如果数据量比较大的话,难免会因为一些原因,而录入多条重复的记录,那么应该如何操作才能删除重复行,并且保留一条id较大,或者较小的记录呢。
在本例中所用数据表结构如下所示tdb_goods
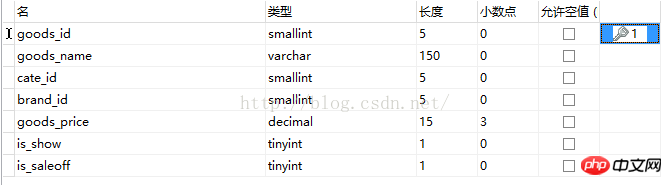
表中数据重复如图所示
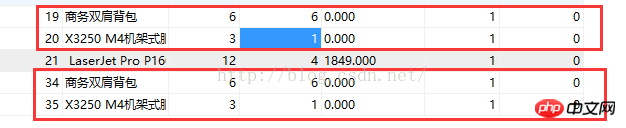
首先第一步,利用group by分组查出每组中数目大于2的(即重复记录的)内容
mysql> SELECT goods_id,goods_name FROM tdb_goods GROUP BY goods_name HAVING COUN T(goods_name)>=2; +----------+------------------------------+ | goods_id | goods_name | +----------+------------------------------+ | 20 | X3250 M4机架式服务器 2583i14 | | 19 | 商务双肩背包 | +----------+------------------------------+ 2 rows in set (0.01 sec)
然后使用LEFT JOIN使原始表和上述查询结果进行连接,删除重复记录,保留id较小的记录
mysql> DELETE t1 FROM tdb_goods AS t1 LEFT JOIN( SELECT goods_id,goods_name FROM tdb_goods GROUP BY goods_name HAVING COUNT(goods_name)>=2) AS t2 ON t1.goods_na me = t2.goods_name WHERE t1.goods_id>t2.goods_id; Query OK, 2 rows affected (0.06 sec)
从上述语句可以看出,条件是名称相同的,然后删除所有goods_id大的记录。这样就可以实现想要的效果。
如果想保留id较大的同理,如下所示
mysql> DELETE t1 FROM tdb_goods AS t1 LEFT JOIN( SELECT max(goods_id) AS goods_i d,goods_name FROM tdb_goods GROUP BY goods_name HAVING COUNT(goods_name)>=2) AS t2 ON t1.goods_name = t2.goods_name WHERE t1.goods_id<t2.goods_id; Query OK, 2 rows affected (0.03 sec)
注关于表连接,如有疑问请查看JOIN的用法。
以上就是mysql如何删除表中的重复行并保留id较小(或者较大)的记录的内容,更多相关内容请关注PHP中文网(www.php.cn)!
Kenyataan:
Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn
Artikel sebelumnya:mysql数据类型详细介绍Artikel seterusnya:MySQL字符函数的详细介绍