



比如说有个name列和一个eamil列,如果数据库里面有条记录的这两列的值相同(我说的是这条记录的对应的那两列的值相同,并不是同一条记录里面两列值相同)的话就自动删除其他多余的列而保留最新的那一条(也就是ID最小的那个,ID是一个自增主键)
——————————————————
也就是说表里面有两条记录的name都是admin,email都是abc@163.com,我只想保留其中一条,这该怎么做
回复内容:
其实你会用英文搜索的话。可以很方便在stack overflow上 找到相关的信息 真的学CS的就不要用百度了 用google你会发现一个不一样的世界的随便贴一个
sql - How can I remove duplicate rows?
稍微讲一下其中一个思路(里面有很多很好的答案 你可以自己去看)
就是做一个group by 保留其中id 最大的(你说自增长 id最大的应该就是最新的)就可以了
具体sql query 可以这样写
<span class="k">delete</span> <span class="k">from</span> <span class="n">test</span> <span class="k">where</span> <span class="n">id</span> <span class="k">not</span> <span class="k">in</span><span class="p">(</span>
<span class="k">select</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span><span class="p">,</span><span class="k">max</span><span class="p">(</span><span class="n">id</span><span class="p">)</span> <span class="k">from</span> <span class="n">test</span>
<span class="k">group</span> <span class="k">by</span> <span class="n">name</span><span class="p">,</span><span class="n">email</span> <span class="k">having</span> <span class="n">id</span> <span class="k">is</span> <span class="k">not</span> <span class="k">null</span><span class="p">)</span>
distinct
如果要保留id的最小值,例如:数据:
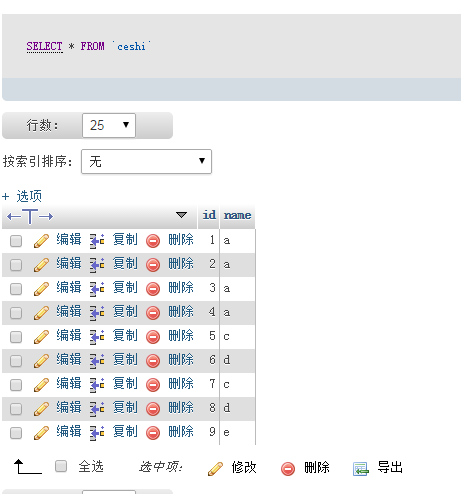

执行sql:select count(*) as count ,name,id from ceshi group by name
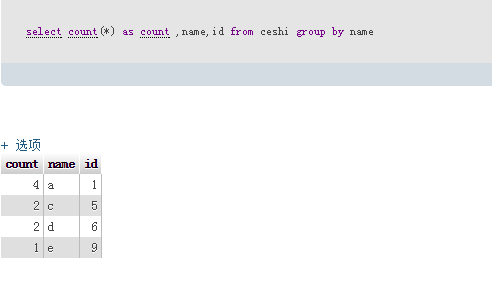 最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name)
最后要删除的sql为:delete from ceshi where id not in (select count(*) as count ,name,id from ceshi group by name)如果想保留id的最大值:
简单的办法是:delete from ceshi where id not in (select count(*) as count ,name,id from (select * from ceshi order by id desc) group by name) distinct 其实非常的简单,只需要把你这张表当成两张表来处理就行了。
DELETE p1 from TABLE p1, TABLE p2 WHERE p1.name = p2.name AND p1.email = p2.email AND p1.id 这里有个问题,题主说保留最新的那一条(也就是ID最小的那个),既然是递增,最新的不应该是最大的那条吗?
上面的的语句,p1.id '即可。
当然是用group by,count可以更精准控制重复n次的情况。不过目测楼主需求应该只要把重复的删掉,保留最新的就可以了。 DELETE FROM table WHERE id not in ( SELECT
tb.id FROM ( SELECT tmp.* FROM table tmp ) tb GROUP BY tb.field1, tb.field2,… );
table是表名,field是要去重的字段。 新建一个表,设置name,email为唯一索引,然后重新插入旧表数据

 Bagaimanakah jenis membayangkan jenis PHP, termasuk jenis skalar, jenis pulangan, jenis kesatuan, dan jenis yang boleh dibatalkan?Apr 17, 2025 am 12:25 AM
Bagaimanakah jenis membayangkan jenis PHP, termasuk jenis skalar, jenis pulangan, jenis kesatuan, dan jenis yang boleh dibatalkan?Apr 17, 2025 am 12:25 AMJenis PHP meminta untuk meningkatkan kualiti kod dan kebolehbacaan. 1) Petua Jenis Skalar: Oleh kerana Php7.0, jenis data asas dibenarkan untuk ditentukan dalam parameter fungsi, seperti INT, Float, dan lain -lain. 2) Return Type Prompt: Pastikan konsistensi jenis nilai pulangan fungsi. 3) Jenis Kesatuan Prompt: Oleh kerana Php8.0, pelbagai jenis dibenarkan untuk ditentukan dalam parameter fungsi atau nilai pulangan. 4) Prompt jenis yang boleh dibatalkan: membolehkan untuk memasukkan nilai null dan mengendalikan fungsi yang boleh mengembalikan nilai null.
 Bagaimanakah PHP mengendalikan pengklonan objek (kata kunci klon) dan kaedah sihir __clone?Apr 17, 2025 am 12:24 AM
Bagaimanakah PHP mengendalikan pengklonan objek (kata kunci klon) dan kaedah sihir __clone?Apr 17, 2025 am 12:24 AMDalam PHP, gunakan kata kunci klon untuk membuat salinan objek dan menyesuaikan tingkah laku pengklonan melalui kaedah Magic \ _ _ _. 1. Gunakan kata kunci klon untuk membuat salinan cetek, mengkloning sifat objek tetapi bukan sifat objek. 2. Kaedah klon \ _ \ _ boleh menyalin objek bersarang untuk mengelakkan masalah menyalin cetek. 3. Beri perhatian untuk mengelakkan rujukan pekeliling dan masalah prestasi dalam pengklonan, dan mengoptimumkan operasi pengklonan untuk meningkatkan kecekapan.
 PHP vs Python: Gunakan Kes dan AplikasiApr 17, 2025 am 12:23 AM
PHP vs Python: Gunakan Kes dan AplikasiApr 17, 2025 am 12:23 AMPHP sesuai untuk pembangunan web dan sistem pengurusan kandungan, dan Python sesuai untuk sains data, pembelajaran mesin dan skrip automasi. 1.PHP berfungsi dengan baik dalam membina laman web dan aplikasi yang cepat dan berskala dan biasanya digunakan dalam CMS seperti WordPress. 2. Python telah melakukan yang luar biasa dalam bidang sains data dan pembelajaran mesin, dengan perpustakaan yang kaya seperti numpy dan tensorflow.
 Huraikan tajuk caching HTTP yang berbeza (mis., Cache-Control, ETAG, Modified Last).Apr 17, 2025 am 12:22 AM
Huraikan tajuk caching HTTP yang berbeza (mis., Cache-Control, ETAG, Modified Last).Apr 17, 2025 am 12:22 AMPemain utama dalam tajuk cache HTTP termasuk kawalan cache, ETAG, dan modifikasi terakhir. 1.Cache-Control digunakan untuk mengawal dasar caching. Contoh: Cache-Control: Max-Age = 3600, Awam. 2. ETAG mengesahkan perubahan sumber melalui pengenal unik, Contoh: ETAG: "686897696A7C876B7E". 3. Modified Last Menunjukkan Masa Pengubahsuaian Terakhir Sumber, Contoh: Modified Last: Wed, 21OCT201507: 28: 00GMT.
 Terangkan hashing kata laluan yang selamat di PHP (mis., Password_hash, password_verify). Mengapa tidak menggunakan MD5 atau SHA1?Apr 17, 2025 am 12:06 AM
Terangkan hashing kata laluan yang selamat di PHP (mis., Password_hash, password_verify). Mengapa tidak menggunakan MD5 atau SHA1?Apr 17, 2025 am 12:06 AMDalam php, kata laluan_hash dan kata laluan 1) password_hash menjana hash yang mengandungi nilai garam untuk meningkatkan keselamatan. 2) Kata Laluan_verify Sahkan kata laluan dan pastikan keselamatan dengan membandingkan nilai hash. 3) MD5 dan SHA1 terdedah dan kekurangan nilai garam, dan tidak sesuai untuk keselamatan kata laluan moden.
 PHP: Pengenalan kepada bahasa skrip sisi pelayanApr 16, 2025 am 12:18 AM
PHP: Pengenalan kepada bahasa skrip sisi pelayanApr 16, 2025 am 12:18 AMPHP adalah bahasa skrip sisi pelayan yang digunakan untuk pembangunan web dinamik dan aplikasi sisi pelayan. 1.Php adalah bahasa yang ditafsirkan yang tidak memerlukan kompilasi dan sesuai untuk perkembangan pesat. 2. Kod PHP tertanam dalam HTML, menjadikannya mudah untuk membangunkan laman web. 3. PHP memproses logik sisi pelayan, menghasilkan output HTML, dan menyokong interaksi pengguna dan pemprosesan data. 4. PHP boleh berinteraksi dengan pangkalan data, penyerahan borang proses, dan melaksanakan tugas-tugas sampingan pelayan.
 PHP dan Web: Meneroka kesan jangka panjangnyaApr 16, 2025 am 12:17 AM
PHP dan Web: Meneroka kesan jangka panjangnyaApr 16, 2025 am 12:17 AMPHP telah membentuk rangkaian sejak beberapa dekad yang lalu dan akan terus memainkan peranan penting dalam pembangunan web. 1) PHP berasal pada tahun 1994 dan telah menjadi pilihan pertama bagi pemaju kerana kemudahan penggunaannya dan integrasi lancar dengan MySQL. 2) Fungsi terasnya termasuk menghasilkan kandungan dinamik dan mengintegrasikan dengan pangkalan data, yang membolehkan laman web dikemas kini secara real time dan dipaparkan secara peribadi. 3) Aplikasi dan ekosistem PHP yang luas telah mendorong kesan jangka panjangnya, tetapi ia juga menghadapi kemas kini versi dan cabaran keselamatan. 4) Penambahbaikan prestasi dalam beberapa tahun kebelakangan ini, seperti pembebasan Php7, membolehkannya bersaing dengan bahasa moden. 5) Pada masa akan datang, PHP perlu menangani cabaran baru seperti kontena dan microservices, tetapi fleksibiliti dan komuniti aktif menjadikannya boleh disesuaikan.
 Mengapa menggunakan PHP? Kelebihan dan faedah dijelaskanApr 16, 2025 am 12:16 AM
Mengapa menggunakan PHP? Kelebihan dan faedah dijelaskanApr 16, 2025 am 12:16 AMManfaat utama PHP termasuk kemudahan pembelajaran, sokongan pembangunan web yang kukuh, perpustakaan dan kerangka yang kaya, prestasi tinggi dan skalabilitas, keserasian silang platform, dan keberkesanan kos. 1) mudah dipelajari dan digunakan, sesuai untuk pemula; 2) integrasi yang baik dengan pelayan web dan menyokong pelbagai pangkalan data; 3) mempunyai rangka kerja yang kuat seperti Laravel; 4) Prestasi tinggi dapat dicapai melalui pengoptimuman; 5) menyokong pelbagai sistem operasi; 6) Sumber terbuka untuk mengurangkan kos pembangunan.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

