
Rumah >pembangunan bahagian belakang >Tutorial Python >python中文编码问题小结
python中文编码问题小结

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2016-06-16 08:41:321149semak imbas
中文编码问题一直是Python程序设计中很头痛的问题,本文对此较为详细的进行了总结归纳。具体如下:
当字符串是:'\u4e2d\u56fd'
>>>s=['\u4e2d\u56fd','\u6e05\u534e\u5927\u5b66']
>>>str=s[0].decode('unicode_escape') #.encode("EUC_KR")
>>>print str
中国
当字符串是:' 东亚学团一中'
>>>print unichr(19996) 东
ord()支持unicode,可以显示特定字符的unicode号码,如:
>>>print ord('A')
65
只要和Unicode连接,就会产生Unicode字串。如:
>>> 'help' 'help' >>> 'help,' + u'python' u'help,python'
对于ASCII(7位)兼容的字串,可和内置的str()函数把Unicode字串转换成ASCII字串。如:
>>> str(u'hello world') 'hello world'
对几个概念的理解:
ASCII码 用数据字 对应 相应的字符 如下图所示:
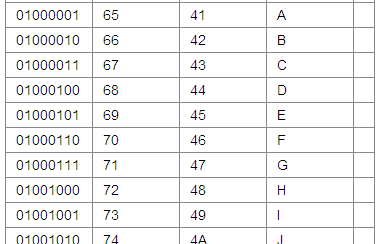
而中文 就是区位码对应汉字。如:“好” 的ASCII码为: 22909
unicode 编码 每个国家分一块。它有UTF-8、UTF-16、UTF-32等形式
中文范围 4E00-9FBF:这个范围内有 gbk,gb2312,
utf-8是基于unicode的 国际化的场合适合使用
gb2312和gb2312都是国标码 出现的较早 主要用于编解码常用汉字
希望本文所述对大家的Python程序设计有所帮助。
Kenyataan:
Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn
Artikel sebelumnya:跟老齐学Python之不要红头文件(1)Artikel seterusnya:python自动化测试之连接几组测试包实例