



Pengenalan
OpenAI telah mengeluarkan model barunya berdasarkan seni bina "strawberi" yang sangat dijangka. Model inovatif ini, yang dikenali sebagai O1, meningkatkan keupayaan penalaran, yang membolehkannya berfikir melalui masalah dengan lebih berkesan sebelum memberikan jawapan. Sebagai pengguna ChatGPT Plus, saya berpeluang meneroka model baru ini secara langsung. Saya teruja untuk berkongsi pandangan saya mengenai prestasi, keupayaan, dan implikasi untuk pengguna dan pemaju. Saya akan membandingkan dengan teliti GPT-4O vs OpenAI O1 pada metrik yang berbeza. Tanpa apa -apa lagi, mari kita mulakan.
Dalam artikel ini, anda akan meneroka perbezaan antara O1andGPT-4O, termasuk perbandingan OFGPT O1 vs GPT 4. Kami akan memberikan pandangan tentang prestasi dalam pratonton dan Preview dan membimbing anda untuk menggunakan GPT O1efectely. Di samping itu, kami akan membincangkan kos OGPT O1, menyerlahkan ketersediaan AGPT O1 Freetier, dan memperkenalkan theGPT O1 Minivions. Akhirnya, kami akan menganalisis perdebatan yang berterusan OFGPT 4O vs O1 vs Openaito membantu anda membuat keputusan yang tepat.
Baca terus!
Baru untuk Model Openai? Baca ini untuk mengetahui cara menggunakan Openai O1: Bagaimana Mengakses Openai O1?

Kemas kini baru di Openai O1:
- OpenAI telah meningkatkan had kadar untuk O1-Mini untuk Plus dan pengguna pasukan sebanyak 7x-dari 50 mesej setiap minggu hingga 50 mesej setiap hari.
- Untuk O1-Preview, had kadar meningkat dari 30 hingga 50 mesej mingguan.
Gambaran Keseluruhan
- Model O1 Openai yang baru meningkatkan keupayaan penalaran melalui pendekatan "rantai pemikiran", menjadikannya sesuai untuk tugas -tugas yang kompleks.
- GPT-4O adalah model serba boleh, multimodal yang sesuai untuk tugas-tugas umum di seluruh teks, ucapan, dan input video.
- OpenAI O1 cemerlang dalam matematik, pengekodan, dan penyelesaian masalah saintifik, mengatasi GPT-4O dalam senario penalaran.
- Walaupun Openai O1 menawarkan prestasi berbilang bahasa yang lebih baik, ia mempunyai kelajuan, kos, dan batasan sokongan multimodal.
- GPT-4O tetap menjadi pilihan yang lebih baik untuk aplikasi AI yang cepat, kos efektif, dan serba boleh yang memerlukan fungsi tujuan umum.
- Pilihan antara GPT-4O dan OpenAI O1 bergantung kepada keperluan khusus. Setiap model menawarkan kekuatan yang unik untuk kes penggunaan yang berbeza.
Jadual Kandungan
- Pengenalan
- Tujuan Perbandingan: GPT-4O vs Openai O1
- Gambaran Keseluruhan Semua Model Openai O1
- Keupayaan model O1 dan GPT 4O
- Openai O1
- Openai's O1: Model Rantai-of-Insound
- GPT-4O
- GPT-4O vs OpenAI O1: Keupayaan berbilang bahasa
- Penilaian OpenAI O1: Melepasi GPT-4O di seluruh peperiksaan manusia dan penanda aras ML
- GPT-4O vs OpenAI O1: Penilaian Jailbreak
- GPT-4O vs OpenAI O1 dalam mengendalikan tugas agentik
- GPT-4O vs OpenAI O1: Penilaian Hallucinations
- Kualiti vs kelajuan vs kos
- Openai O1 vs GPT-4O: Penilaian Keutamaan Manusia
- Openai O1 vs GPT-4O: Siapa yang lebih baik dalam tugas yang berbeza?
- Menyahkod teks ciphered
- Sains Kesihatan
- Soalan alasan
- Pengekodan: Membuat Permainan
- GPT-4O vs OpenAI O1: Perincian API dan Penggunaan
- Batasan Openai O1
- Terbuka O1 berjuang dengan tugas Q & A pada acara dan entiti baru -baru ini
- Openai O1 lebih baik pada penalaran logik daripada GPT-4O
- Keputusan terakhir: GPT-4O vs Openai O1
- Kesimpulan
Tujuan Perbandingan: GPT-4O vs Openai O1
Inilah sebabnya kami membandingkan-GPT-4O vs OpenAI O1:
- GPT-4O adalah model serba boleh, multimodal yang mampu memproses teks, ucapan, dan input video, menjadikannya sesuai untuk pelbagai tugas umum. Ia menguasai lelaran terkini ChatGPT, mempamerkan kekuatannya dalam menghasilkan teks seperti manusia dan berinteraksi merentasi pelbagai modaliti.
- Openai O1 adalah model yang lebih khusus untuk penalaran kompleks dan penyelesaian masalah dalam matematik, pengekodan, dan lebih banyak bidang. Ia cemerlang dalam tugas yang memerlukan pemahaman yang mendalam tentang konsep -konsep lanjutan, menjadikannya sesuai untuk domain yang mencabar seperti penalaran logik maju.
Tujuan Perbandingan: Perbandingan ini menyoroti kekuatan unik setiap model dan menjelaskan kes penggunaan optimum mereka. Walaupun Openai O1 sangat baik untuk tugas-tugas penalaran yang kompleks, ia tidak bertujuan untuk menggantikan GPT-4O untuk aplikasi tujuan umum. Dengan mengkaji keupayaan mereka, metrik prestasi, kelajuan, kos, dan kes penggunaan, saya akan memberikan pandangan tentang model yang lebih sesuai untuk keperluan dan senario yang berbeza.
Gambaran Keseluruhan Semua Model Openai O1

Inilah perwakilan jadual Openai O1:
| Model | Penerangan | Tetingkap konteks | Token output max | Data latihan |
| O1-Preview | Menunjuk kepada gambar O1 yang paling terkini: O1-Preview-2024-09-12 | 128,000 token | 32,768 token | Hingga Oktober 2023 |
| O1-Preview-2024-09-12 | Snapshot Model O1 Terkini | 128,000 token | 32,768 token | Hingga Oktober 2023 |
| O1-Mini | Titik kepada snapshot O1-Mini yang paling terkini: O1-Mini-2024-09-12 | 128,000 token | 65,536 token | Hingga Oktober 2023 |
| O1-Mini-2024-09-12 | Snapshot Model O1-Mini Terkini | 128,000 token | 65,536 token | Hingga Oktober 2023 |
Keupayaan model O1 dan GPT 4O
Openai O1

Model Openai O1 telah menunjukkan prestasi yang luar biasa di pelbagai tanda aras. Ia menduduki tempat ke -89 pada cabaran pengaturcaraan yang kompetitif CODEFORCE dan diletakkan di antara 500 teratas di USA Math Olympiad Qualifier (AIME). Di samping itu, ia melepasi ketepatan peringkat PhD manusia pada penanda aras Fizik, Biologi, dan Masalah Kimia (GPQA).
Model ini dilatih menggunakan algoritma pembelajaran tetulang berskala besar yang meningkatkan kebolehan penalarannya melalui proses "rantai pemikiran", yang membolehkan pembelajaran yang cekap data. Penemuan menunjukkan bahawa prestasinya bertambah baik dengan peningkatan pengkomputeran semasa latihan dan lebih banyak masa yang diperuntukkan untuk penalaran semasa ujian, mendorong penyiasatan lanjut ke dalam pendekatan skala novel ini, yang berbeza dari kaedah pretraining LLM tradisional. Sebelum membandingkan selanjutnya, mari kita lihat "bagaimana rantaian proses pemikiran meningkatkan kebolehan pemikiran Openai O1."
Openai's O1: Model Rantai-of-Insound

Model Openai O1 memperkenalkan perdagangan baru dalam kos dan prestasi untuk memberikan kebolehan "penalaran" yang lebih baik. Model-model ini dilatih khusus untuk proses "rantai pemikiran", yang bermaksud mereka direka untuk berfikir langkah demi langkah sebelum bertindak balas. Ini membina rantaian pemikiran yang mendorong corak yang diperkenalkan pada tahun 2022, yang menggalakkan AI untuk berfikir secara sistematik dan bukan hanya meramalkan perkataan seterusnya. Algoritma mengajar mereka untuk memecahkan tugas -tugas yang kompleks, belajar dari kesilapan, dan mencuba pendekatan alternatif apabila perlu.
Juga Baca: O1: Model Baru Terbuka yang 'Berfikir' sebelum menjawab masalah yang sukar
Unsur -unsur utama penalaran LLMS
Model O1 memperkenalkan token penalaran. Model -model ini menggunakan token penalaran ini untuk "berfikir," memecahkan pemahaman mereka tentang segera dan mempertimbangkan pelbagai pendekatan untuk menghasilkan respons. Selepas menjana token penalaran, model menghasilkan jawapan sebagai token penyelesaian yang dapat dilihat dan membuang token penalaran dari konteksnya.

1. Pembelajaran Pengukuhan dan Masa Berfikir
Model O1 menggunakan algoritma pembelajaran tetulang yang menggalakkan tempoh pemikiran yang lebih lama dan lebih mendalam sebelum menghasilkan respons. Proses ini direka untuk membantu model yang lebih baik mengendalikan tugas penalaran yang kompleks.
Prestasi model meningkat dengan kedua-dua masa latihan yang meningkat (pengiraan masa kereta api) dan apabila dibenarkan lebih banyak masa untuk berfikir semasa penilaian (pengiraan masa ujian).
2. Penggunaan rantai pemikiran
Rantaian pendekatan pemikiran membolehkan model memecahkan masalah yang kompleks ke dalam langkah -langkah yang lebih mudah dan mudah diurus. Ia boleh meninjau semula dan memperbaiki strateginya, mencuba kaedah yang berbeza apabila pendekatan awal gagal.
Kaedah ini memberi manfaat kepada tugas-tugas yang memerlukan penalaran pelbagai langkah, seperti penyelesaian masalah matematik, pengekodan, dan menjawab soalan terbuka.

Baca lebih lanjut artikel mengenai kejuruteraan segera di sini.
3. Keutamaan manusia dan penilaian keselamatan
Dalam penilaian yang membandingkan prestasi O1-Preview kepada GPT-4O, jurulatih manusia sangat memilih output O1-Preview dalam tugas yang memerlukan keupayaan penalaran yang kuat.
Mengintegrasikan rantaian pemikiran pemikiran ke dalam model juga menyumbang kepada peningkatan keselamatan dan penjajaran dengan nilai -nilai manusia. Dengan membenamkan peraturan keselamatan terus ke dalam proses penalaran, O1-Preview menunjukkan pemahaman yang lebih baik tentang sempadan keselamatan, mengurangkan kemungkinan penyelesaian yang berbahaya walaupun dalam senario yang mencabar.
4. Token Penalaran Tersembunyi dan Ketelusan Model
Openai telah memutuskan untuk mengekalkan rantaian pemikiran terperinci yang tersembunyi dari pengguna untuk melindungi integriti proses pemikiran model dan mengekalkan kelebihan daya saing. Walau bagaimanapun, mereka menyediakan versi yang diringkaskan kepada pengguna untuk membantu memahami bagaimana model tiba pada kesimpulannya.
Keputusan ini membolehkan OpenAI memantau penalaran model untuk tujuan keselamatan, seperti mengesan percubaan manipulasi atau memastikan pematuhan dasar.
Juga baca: GPT-4O vs Gemini: Membandingkan dua model AI multimodal yang kuat
5. Metrik prestasi dan penambahbaikan
Model O1 menunjukkan kemajuan yang ketara dalam bidang prestasi utama:
- Mengenai penanda aras penalaran yang kompleks, O1-Preview mencapai skor yang sering menyaingi pakar manusia.
- Penambahbaikan model dalam pertandingan pengaturcaraan yang kompetitif dan pertandingan matematik menunjukkan peningkatan pemikiran dan kemampuan menyelesaikan masalahnya.
Penilaian keselamatan menunjukkan bahawa O1-Preview melakukan lebih baik daripada GPT-4O dalam mengendalikan kes-kes yang berpotensi berbahaya dan kelebihan, memperkuat keteguhannya.
Juga Baca: Openai's O1-Mini: Model Permainan yang Mengubah Untuk STEM dengan Penalaran Kos yang Berkesan
GPT-4O

GPT-4O adalah kuasa besar multimodal yang mahir dalam mengendalikan teks, ucapan, dan input video, menjadikannya serba boleh untuk pelbagai tugas umum. Model ini menguasai chatgpt, mempamerkan kekuatannya dalam menghasilkan teks seperti manusia, menafsirkan arahan suara, dan juga menganalisis kandungan video. Bagi pengguna yang memerlukan model yang boleh beroperasi di pelbagai format dengan lancar, GPT-4O adalah pesaing yang kuat.
Sebelum GPT-4O, menggunakan mod suara dengan CHATGPT melibatkan latensi purata 2.8 saat dengan GPT-3.5 dan 5.4 saat dengan GPT-4. Ini dicapai melalui saluran paip tiga model berasingan: model asas yang pertama ditranskripsikan audio ke teks, kemudian GPT-3.5 atau GPT-4 memproses input teks untuk menghasilkan output teks, dan akhirnya, model ketiga menukar teks itu kembali ke audio. Persediaan ini bermakna bahawa teras AI-GPT-4-agak terhad, kerana ia tidak dapat secara langsung mentafsir nuansa seperti nada, pembesar suara, bunyi latar belakang atau unsur-unsur ekspres seperti ketawa, nyanyian, atau emosi.
Dengan GPT-4O, OpenAI telah membangunkan model yang sama sekali baru yang mengintegrasikan teks, penglihatan, dan audio dalam rangkaian saraf tunggal dan akhir. Pendekatan bersatu ini membolehkan GPT-4O mengendalikan semua input dan output dalam kerangka yang sama, sangat meningkatkan keupayaannya untuk memahami dan menghasilkan kandungan yang lebih bernuansa, multimodal.
Anda boleh meneroka lebih banyak keupayaan GPT-4O di sini: Hello GPT-4O.
GPT-4O vs OpenAI O1: Keupayaan berbilang bahasa
Perbandingan antara Model O1 OpenAI dan GPT-4O menyoroti keupayaan prestasi berbilang bahasa mereka, yang memberi tumpuan kepada model O1-Preview dan O1-Mini terhadap GPT-4O.

Set ujian MMLU (pemahaman bahasa berbilang bahasa) diterjemahkan ke dalam 4 languagesusingHuman penterjemah untuk menilai prestasi mereka merentasi pelbagai bahasa. Pendekatan ini memastikan ketepatan yang lebih tinggi, terutamanya untuk bahasa yang kurang diwakili atau mempunyai sumber yang terhad, seperti Yoruba. Kajian ini menggunakan set ujian yang diterjemahkan oleh manusia untuk membandingkan kebolehan model dalam konteks linguistik yang pelbagai.
Penemuan Utama:
- O1-Preview menunjukkan keupayaan berbilang bahasa yang lebih tinggi daripada GPT-4O, dengan peningkatan yang ketara dalam bahasa seperti Arab, Bengali, dan Cina. Ini menunjukkan bahawa model O1-Preview lebih sesuai untuk tugas yang memerlukan pemahaman dan pemprosesan pelbagai bahasa yang mantap.
- O1-Mini juga mengalahkan rakan sejawatannya, GPT-4O-Mini, menunjukkan peningkatan yang konsisten di pelbagai bahasa. Ini menunjukkan bahawa walaupun versi yang lebih kecil model O1 mengekalkan keupayaan berbilang bahasa yang dipertingkatkan.
Terjemahan manusia:
Penggunaan terjemahan manusia dan bukannya terjemahan mesin (seperti dalam penilaian terdahulu dengan model seperti GPT-4 dan Azure Translate) membuktikan kaedah yang lebih dipercayai untuk menilai prestasi. Hal ini terutama berlaku untuk bahasa yang kurang banyak digunakan, di mana terjemahan mesin sering kurang ketepatan.
Secara keseluruhannya, penilaian menunjukkan bahawa kedua-dua O1-Preview dan O1-Mini mengalahkan rakan-rakan GPT-4O mereka dalam tugas berbilang bahasa, terutama dalam bahasa linguistik yang pelbagai atau rendah. Penggunaan terjemahan manusia dalam menguji menggariskan pemahaman bahasa yang unggul tentang model O1, menjadikan mereka lebih mampu mengendalikan senario berbilang bahasa dunia. Ini menunjukkan kemajuan OpenAI dalam membina model dengan pemahaman bahasa yang lebih luas dan lebih inklusif.
Penilaian OpenAI O1: Melepasi GPT-4O di seluruh peperiksaan manusia dan penanda aras ML

Untuk menunjukkan peningkatan keupayaan penalaran ke atas GPT-4O, model O1 diuji pada pelbagai peperiksaan manusia dan tanda aras pembelajaran mesin. Keputusan menunjukkan bahawa O1 secara signifikan mengatasi GPT-4O pada tugas yang paling berintensifkan, menggunakan tetapan pengiraan masa ujian maksimum melainkan dinyatakan sebaliknya.
Penilaian persaingan
- Matematik (AIME 2024), pengekodan (codeforces), dan sains peringkat PhD (GPQA Diamond): O1 menunjukkan peningkatan yang besar ke atas GPT-4O mengenai penanda aras penalaran yang mencabar. Ketepatan lulus@1 diwakili oleh bar pepejal, manakala kawasan yang teduh menggambarkan prestasi undi majoriti (konsensus) dengan 64 sampel.
- Perbandingan Benchmark: O1 mengatasi GPT-4O merentasi pelbagai tanda aras, termasuk 54 daripada 57 subkategori MMLU.
Wawasan prestasi terperinci
- Matematik (AIME 2024): Pada Peperiksaan Matematik Undangan Amerika (AIME) 2024, O1 menunjukkan kemajuan yang signifikan terhadap GPT-4O. GPT-4O hanya menyelesaikan 12% daripada masalah, manakala O1 mencapai ketepatan 74% dengan satu sampel setiap masalah, 83% dengan konsensus 64-sampel, dan 93% dengan peringkat semula 1000 sampel. Tahap prestasi ini menempatkan O1 di antara 500 pelajar teratas secara nasional dan di atas pemotongan untuk Olimpik Matematik Amerika Syarikat.
- Sains (GPQA Diamond): Dalam penanda aras Diamond GPQA, yang menguji kepakaran dalam bidang kimia, fizik, dan biologi, O1 melepasi prestasi pakar manusia dengan PhD, menandakan kali pertama model telah melakukannya. Walau bagaimanapun, hasil ini tidak mencadangkan bahawa O1 lebih tinggi daripada PhD dalam semua aspek tetapi lebih mahir dalam senario penyelesaian masalah tertentu yang diharapkan daripada PhD.
Prestasi keseluruhan
- O1 juga cemerlang dalam penanda aras pembelajaran mesin lain, mengatasi model terkini. Dengan keupayaan persepsi penglihatan yang membolehkan, ia mencapai skor 78.2% pada MMMU, menjadikannya model pertama yang bersaing dengan pakar manusia dan mengatasi GPT-4O dalam 54 daripada 57 subkategori MMLU.
GPT-4O vs OpenAI O1: Penilaian Jailbreak

Di sini, kita membincangkan penilaian keteguhan model O1 (khususnya O1-Preview dan O1-Mini) terhadap "jailbreaks," yang merupakan petugas yang direka untuk memintas sekatan kandungan model. Empat penilaian berikut digunakan untuk mengukur daya tahan model ke jailbreaks ini:
- Jailbreaks Pengeluaran : Koleksi teknik jailbreak yang dikenal pasti dari data penggunaan sebenar dalam persekitaran pengeluaran Chatgpt.
- Contoh Jailbreak Augmented : Penilaian ini menggunakan kaedah jailbreak yang diketahui secara terbuka kepada satu set contoh yang biasanya digunakan untuk menguji kandungan yang tidak dibenarkan, menilai keupayaan model untuk menentang percubaan ini.
- Jailbreaks yang berasaskan manusia : Teknik jailbreak yang dicipta oleh penguji manusia, sering disebut sebagai "pasukan merah," ujian tekanan pertahanan model.
- StrongREKEK : Penanda aras akademik yang menilai rintangan model terhadap serangan jailbreak yang didokumentasikan dengan baik dan biasa. Metrik "[e -mel dilindungi]" digunakan untuk menilai keselamatan model dengan mengukur prestasinya terhadap 10% kaedah jailbreak teratas untuk setiap prompt.
Perbandingan dengan GPT-4O :
Angka di atas membandingkan prestasi model O1-Preview, O1-Mini, dan GPT-4O mengenai penilaian ini. Hasilnya menunjukkan bahawa model O1 (O1-Preview dan O1-Mini) menunjukkan peningkatan yang ketara dalam keteguhan terhadap GPT-4O, terutamanya dalam penilaian strongrecect, yang diperhatikan untuk kesukaran dan pergantungannya pada teknik jailbreak maju. Ini menunjukkan bahawa model O1 lebih baik dilengkapi untuk mengendalikan arahan adversarial dan mematuhi garis panduan kandungan daripada GPT-4O.
GPT-4O vs OpenAI O1 dalam mengendalikan tugas agentik

Di sini, kami menilai Openai's O1-Preview, O1-Mini, dan GPT-4O dalam mengendalikan tugas-tugas agensi, menonjolkan kadar kejayaan mereka di pelbagai senario. Tugas-tugas tersebut direka untuk menguji kebolehan model untuk melaksanakan operasi kompleks seperti menubuhkan bekas Docker, melancarkan contoh GPU berasaskan awan, dan membuat pelayan web yang disahkan.
Persekitaran Penilaian dan Kategori Tugas
Penilaian dijalankan dalam dua persekitaran utama:
- Persekitaran teks : Melibatkan pengekodan python dalam terminal Linux, dipertingkatkan dengan pecutan GPU.
- Persekitaran Pelayar : Memanfaatkan perancah luaran yang mengandungi HTML yang diproses dengan tangkapan skrin pilihan untuk mendapatkan bantuan.
Tugas ini meliputi pelbagai kategori, seperti:
- Mengkonfigurasi bekas Docker untuk menjalankan pelayan kesimpulan yang serasi dengan API OpenAI.
- Membangunkan pelayan web berasaskan Python dengan mekanisme pengesahan.
- Menggunakan contoh GPU berasaskan awan.
Openai O1-Preview dan O1-Mini sedang melancarkan hari ini di API untuk pemaju di Tahap 5.
- Pemaju Terbuka (@openaidevs) 12 September 2024
O1-Preview mempunyai keupayaan penalaran yang kuat dan pengetahuan dunia yang luas.
O1-Mini lebih cepat, 80% lebih murah, dan berdaya saing dengan O1-Preview pada tugas pengekodan.
Lebih banyak dalam https://t.co/l6vkoukfla. https://t.co/moqfsez2f6
Penemuan utama dan hasil prestasi
Grafik secara visual mewakili kadar kejayaan model lebih daripada 100 percubaan setiap tugas. Pemerhatian utama termasuk:
- Tugas Proksi API Terbuka : Tugas paling sukar, menubuhkan proksi API OpenAI, di mana semua model bergelut dengan ketara. Tiada yang mencapai kadar kejayaan yang tinggi, yang menunjukkan cabaran besar di seluruh lembaga.
- Memuatkan Mistral 7b dalam Docker : Tugas ini menyaksikan kejayaan yang berbeza -beza. Model O1-Mini dilakukan sedikit lebih baik, walaupun semua model bergelut berbanding tugas yang lebih mudah.
- Pembelian GPU melalui Ranger : GPT-4O mengatasi yang lain dengan margin yang ketara, menunjukkan keupayaan unggul dalam tugas yang melibatkan API dan interaksi pihak ketiga.
- Tugas pensampelan : GPT-4O menunjukkan kadar kejayaan yang lebih tinggi dalam tugas pensampelan, seperti pensampelan dari nanogpt atau gpt-2 dalam pytorch, yang menunjukkan kecekapannya dalam tugas-tugas yang berkaitan dengan pembelajaran mesin.
- Tugas mudah seperti membuat dompet bitcoin : GPT-4O dilakukan dengan baik, hampir mencapai skor yang sempurna.
Juga Baca: Dari GPT ke Mistral-7b: Lonjakan yang menarik ke hadapan dalam Perbualan AI
Wawasan mengenai tingkah laku model
Penilaian mendedahkan bahawa walaupun model sempadan, seperti O1-Preview dan O1-Mini, kadang-kadang berjaya meluluskan tugas-tugas agenik utama, mereka sering melakukannya dengan mengendalikan subtask kontekstual yang mahir. Walau bagaimanapun, model-model ini masih menunjukkan kekurangan yang ketara dalam menguruskan tugas-tugas pelbagai langkah yang kompleks.
Berikutan kemas kini pasca-mitigasi, model O1-Preview mempamerkan tingkah laku penolakan yang berbeza berbanding dengan versi CHATGPT yang terdahulu. Ini membawa kepada penurunan prestasi pada subtask tertentu, terutamanya yang melibatkan API semula seperti OpenAI. Sebaliknya, kedua-dua O1-Preview dan O1-Mini menunjukkan potensi untuk meluluskan tugas utama dalam keadaan tertentu, seperti menubuhkan proksi API yang disahkan atau menggunakan pelayan kesimpulan dalam persekitaran Docker. Walau bagaimanapun, pemeriksaan manual mendedahkan bahawa kejayaan ini kadang -kadang melibatkan pendekatan yang terlalu banyak, seperti menggunakan model yang kurang kompleks daripada yang diharapkan 7b yang diharapkan.
Secara keseluruhannya, penilaian ini menggariskan cabaran yang berterusan yang dihadapi oleh model AI yang berterusan dalam mencapai kejayaan yang konsisten merentasi tugas -tugas agen yang kompleks. Walaupun model seperti GPT-4O mempamerkan prestasi yang kuat dalam tugas yang lebih mudah atau sempit, mereka masih menghadapi kesukaran dengan tugas pelbagai lapisan yang memerlukan penalaran pesanan yang lebih tinggi dan proses pelbagai langkah yang berterusan. Penemuan menunjukkan bahawa walaupun kemajuan jelas, masih ada jalan yang penting untuk model -model ini untuk mengendalikan semua jenis tugas agentik dengan kuat dan boleh dipercayai.
GPT-4O vs OpenAI O1: Penilaian Hallucinations

Juga baca tentang Knowhalu: halusinasi kecacatan terbesar AI akhirnya diselesaikan dengan Knowhalu!
Untuk lebih memahami penilaian halusinasi model bahasa yang berbeza, penilaian berikut membandingkan model GPT-4O, O1-Preview, dan O1-Mini di beberapa dataset yang direka untuk menimbulkan halusinasi:
Dataset penilaian halusinasi
- SimpleQA: Dataset yang terdiri daripada 4,000 soalan mencari fakta dengan jawapan pendek. Dataset ini digunakan untuk mengukur ketepatan model dalam memberikan jawapan yang betul.
- Hari Lahir: Dataset yang memerlukan model untuk meneka ulang tahun seseorang, mengukur kekerapan di mana model menyediakan tarikh yang salah.
- Soalan Terbuka Akhir: Dataset yang mengandungi arahan yang meminta model untuk menghasilkan fakta mengenai topik sewenang -wenangnya (misalnya, "Tulis bio tentang
"). Prestasi model dinilai berdasarkan bilangan pernyataan yang salah yang dihasilkan, disahkan terhadap sumber seperti Wikipedia.
Penemuan
- O1-Preview mempamerkan halusinasi yang lebih sedikit berbanding dengan GPT-4O, manakala O1-Mini halusinasi kurang kerap daripada GPT-4O-Mini di semua dataset.
- Walaupun keputusan ini, bukti anekdot menunjukkan bahawa kedua-dua O1-Preview dan O1-Mini sebenarnya boleh halusinasi lebih kerap daripada rakan-rakan GPT-4O mereka dalam amalan. Penyelidikan lanjut diperlukan untuk memahami halusinasi secara komprehensif, terutamanya dalam bidang khusus seperti kimia yang tidak diliputi dalam penilaian ini.
- Ia juga diperhatikan oleh Teamers Red bahawa O1-Preview memberikan jawapan yang lebih terperinci dalam domain tertentu, yang boleh menjadikan halusinasi lebih persuasif. Ini meningkatkan risiko pengguna secara tersilap mempercayai dan bergantung kepada maklumat yang salah yang dihasilkan oleh model.
Walaupun penilaian kuantitatif mencadangkan bahawa model O1 (kedua-dua pratonton dan versi mini) hallucinate kurang kerap daripada model GPT-4O, terdapat kebimbangan berdasarkan maklum balas kualitatif yang mungkin tidak selalu berlaku. Analisis yang lebih mendalam merentasi pelbagai domain diperlukan untuk membangunkan pemahaman holistik tentang bagaimana model-model ini mengendalikan halusinasi dan potensi potensi mereka terhadap pengguna.
Juga baca: Adakah halusinasi dalam model bahasa besar (LLMS) tidak dapat dielakkan?
Kualiti vs kelajuan vs kos
Mari kita bandingkan model mengenai kualiti, kelajuan, dan kos. Di sini kita mempunyai carta yang membandingkan pelbagai model:

Kualiti model
Model O1-Preview dan O1-Mini mendahului carta! Mereka menyampaikan skor berkualiti tinggi, dengan 86 untuk O1-Preview dan 82 untuk O1-Mini. Ini bermakna kedua-dua model ini mengatasi orang lain seperti GPT-4O dan CLAUDE 3.5 COMET.
Kelajuan model
Sekarang, bercakap tentang kelajuan -perkara mendapat sedikit lebih menarik. O1-mini dengan pantas, mencatat pada 74 token sesaat, yang meletakkannya di julat tengah. Walau bagaimanapun, O1-Preview berada di sisi yang lebih perlahan, menghasilkan hanya 23 token sesaat. Jadi, semasa mereka menawarkan kualiti, anda mungkin perlu berdagang sedikit kelajuan jika anda pergi dengan O1-Preview.
Harga model
Dan di sini datang kicker! Pandangan O1 adalah agak berbelanja pada 26.3 USD per juta token-lebih banyak daripada kebanyakan pilihan lain. Sementara itu, O1-Mini adalah pilihan yang lebih berpatutan, dengan harga 5 USD. Tetapi jika anda sedar bajet, model seperti Gemini (hanya 0.1 USD) atau model Llama mungkin lebih banyak di lorong anda.
Bottom line
GPT-4O dioptimumkan untuk masa tindak balas yang lebih cepat dan kos yang lebih rendah, terutamanya berbanding dengan GPT-4 Turbo. Kecekapan memberi manfaat kepada pengguna yang memerlukan penyelesaian yang cepat dan kos efektif tanpa mengorbankan kualiti output dalam tugas umum. Reka bentuk model menjadikannya sesuai untuk aplikasi masa nyata di mana kelajuan adalah penting.
Walau bagaimanapun, GPT O1 berdagang kelajuan untuk kedalaman. Oleh kerana tumpuannya terhadap penalaran yang mendalam dan menyelesaikan masalah, ia mempunyai masa tindak balas yang lebih perlahan dan menanggung kos pengiraan yang lebih tinggi. Algoritma canggih model memerlukan lebih banyak kuasa pemprosesan, yang merupakan perdagangan yang diperlukan untuk keupayaannya untuk mengendalikan tugas yang sangat kompleks. Oleh itu, Openai O1 mungkin bukan pilihan yang ideal apabila keputusan cepat diperlukan, tetapi ia bersinar dalam senario di mana ketepatan dan analisis komprehensif adalah yang paling utama.
Baca lebih lanjut mengenainya di sini: O1: Model baru Openai yang 'berfikir' sebelum menjawab masalah yang sukar
Lebih-lebih lagi, salah satu ciri yang menonjol GPT-O1 adalah pergantungannya untuk mendorong. Model ini berkembang dengan arahan terperinci, yang dapat meningkatkan keupayaan penalarannya dengan ketara. Dengan menggalakkannya untuk memvisualisasikan senario dan berfikir melalui setiap langkah, saya mendapati bahawa model itu dapat menghasilkan respons yang lebih tepat dan berwawasan. Pendekatan yang mendorong ini menunjukkan bahawa pengguna mesti menyesuaikan interaksi mereka dengan model untuk memaksimumkan potensinya.
Sebagai perbandingan, saya juga menguji GPT-4O dengan tugas umum, dan menghairankan, ia dilakukan lebih baik daripada model O1. Ini menunjukkan bahawa walaupun kemajuan telah dibuat, masih ada ruang untuk diperbaiki bagaimana model -model ini memproses logik kompleks.
Openai O1 vs GPT-4O: Penilaian Keutamaan Manusia

OpenAI menjalankan penilaian untuk memahami keutamaan manusia untuk dua modelnya: O1-Preview dan GPT-4O. Penilaian ini memberi tumpuan kepada mencabar, terbuka yang terbuka yang merangkumi pelbagai domain. Dalam penilaian ini, jurulatih manusia telah dibentangkan dengan respons tanpa nama dari kedua -dua model dan diminta untuk memilih respons yang mereka sukai.
Hasilnya menunjukkan bahawa O1-Preview muncul sebagai kegemaran yang jelas di kawasan yang memerlukan penalaran berat, seperti analisis data, pengaturcaraan komputer, dan pengiraan matematik. Dalam domain ini, O1-Preview lebih disukai daripada GPT-4O, yang menunjukkan prestasi unggulnya dalam tugas-tugas yang menuntut pemikiran logik dan berstruktur.
Walau bagaimanapun, keutamaan untuk O1-Preview tidak begitu kuat dalam domain yang berpusat di sekitar tugas bahasa semulajadi, seperti penulisan peribadi atau penyuntingan teks. Ini menunjukkan bahawa walaupun O1-Preview cemerlang dalam penalaran yang kompleks, ia mungkin tidak selalu menjadi pilihan terbaik untuk tugas-tugas yang sangat bergantung pada generasi bahasa bernuansa atau ekspresi kreatif.
Penemuan ini menyerlahkan titik kritikal: O1-Preview menunjukkan potensi besar dalam konteks yang mendapat manfaat daripada keupayaan penalaran yang lebih baik, tetapi aplikasinya mungkin lebih terhad apabila ia datang kepada tugas-tugas berasaskan bahasa yang lebih halus dan kreatif. Alam dua ini menawarkan pandangan yang berharga bagi pengguna dalam memilih model yang tepat berdasarkan keperluan mereka.
Juga Baca: Pra-Latihan Generatif (GPT) untuk pemahaman bahasa semula jadi
Openai O1 vs GPT-4O: Siapa yang lebih baik dalam tugas yang berbeza?
Perbezaan reka bentuk dan keupayaan model diterjemahkan ke dalam kesesuaian mereka untuk kes penggunaan yang berbeza:
GPT-4O cemerlang dalam tugas yang melibatkan penjanaan teks, terjemahan, dan ringkasan. Keupayaan multimodal menjadikannya sangat berkesan untuk aplikasi yang memerlukan interaksi di pelbagai format, seperti pembantu suara, chatbots, dan alat penciptaan kandungan. Model ini serba boleh dan fleksibel, sesuai untuk pelbagai aplikasi yang memerlukan tugas AI umum.
Openai O1 sangat sesuai untuk penyelesaian masalah saintifik dan matematik yang kompleks. Ia meningkatkan tugas pengekodan melalui peningkatan generasi kod dan keupayaan debugging, menjadikannya alat yang berkuasa untuk pemaju dan penyelidik yang bekerja pada projek yang mencabar. Kekuatannya mengendalikan masalah yang rumit yang memerlukan penalaran lanjutan, analisis terperinci, dan kepakaran khusus domain.
Menyahkod teks ciphered

Analisis GPT-4O
- Pendekatan : Mengakui bahawa frasa asal diterjemahkan untuk "berfikir langkah demi langkah" dan menunjukkan bahawa penyahsulitan melibatkan memilih atau mengubah huruf tertentu. Walau bagaimanapun, ia tidak menyediakan kaedah penyahkodan konkrit, meninggalkan proses tidak lengkap dan meminta lebih banyak maklumat.
- Batasan : Tidak mempunyai kaedah khusus untuk penyahkodan, mengakibatkan analisis yang belum selesai.
Analisis Openai O1
- Pendekatan : Kaedah matematik digunakan untuk menukar pasangan huruf kepada nilai berangka berdasarkan kedudukan abjad mereka, mengira purata, dan kemudian menukarnya kembali kepada huruf.
- Kekuatan : Menyediakan pecahan terperinci, langkah demi langkah proses penyahkodan, berjaya menerjemahkan ciphertext kepada "Terdapat tiga R dalam strawberi."
Keputusan
- Openai O1 lebih berkesan : menawarkan kaedah konkrit dan logik, menyediakan penyelesaian yang jelas.
- GPT-4O tidak lengkap : tidak mempunyai kaedah penyahkodan tertentu, mengakibatkan output yang belum selesai.
Juga baca: 3 eksperimen tangan dengan Openai's O1 yang perlu anda lihat
Sains Kesihatan

Diagnosis GPT-4O: Sindrom Cornelia de Lange (CDLS)
- Sebab -sebab utama : kecacatan intelektual, kelewatan perkembangan global, kedudukan pendek, dan ciri -ciri wajah yang berbeza (seperti kening tebal, muka segi tiga, hidung bulbous, dan garis rambut anterior yang rendah) adalah perkara biasa di CDL. Ciri -ciri tambahan seperti Macrodontia (gigi yang diperbesar), ciri tangan yang tidak normal, kelewatan motor dan pertuturan, dan kesukaran makan menyokong diagnosis ini.
- Keadaan yang dikecualikan : Ketiadaan kecacatan jantung tertentu, gangguan pendengaran, dan microcephaly (saiz kepala kecil) sesuai dengan CDL dan membantu mengecualikan keadaan berpotensi lain.
Diagnosis Openai O1: Sindrom KBG
- Sebab -sebab utama : Gejala yang diterangkan (seperti kecacatan intelektual, kelewatan perkembangan, makrodontia, muka segi tiga, kening tebal, keabnormalan tangan, dan kedudukan pendek) rapat dengan sindrom KBG. Ciri -ciri khas Macrodontia (terutamanya incisors pusat atas) dan ciri -ciri wajah khusus yang lain sangat menyokong sindrom KBG.
- Keadaan yang dikecualikan : Ketiadaan kecacatan jantung tertentu dan keadaan lain yang dikecualikan, seperti gangguan pendengaran dan microcephaly, sejajar dengan sindrom KBG kerana ciri -ciri ini tidak biasanya terdapat dalam sindrom.
Keputusan
- Kedua -dua diagnosis adalah munasabah , tetapi mereka memberi tumpuan kepada sindrom yang berbeza berdasarkan set gejala yang sama.
- GPT-4O bersandar ke sindrom Cornelia de Lange (CDLS) kerana gabungan kecacatan intelektual, kelewatan perkembangan, dan ciri-ciri muka tertentu.
- OpenAI O1 mencadangkan sindrom KBG kerana ia sesuai dengan ciri -ciri membezakan yang lebih spesifik (seperti Macrodontia incisors pusat atas dan profil muka keseluruhan).
- Memandangkan butiran yang disediakan, sindrom KBG dianggap lebih cenderung , terutamanya kerana sebutan khusus Macrodontia, ciri utama KBG.
Soalan alasan
Untuk memeriksa alasan kedua-dua model, saya bertanya soalan penalaran peringkat lanjutan.
Lima pelajar, p, q, r, s dan t berdiri dalam beberapa perintah dan menerima kuki dan biskut untuk dimakan. Tiada pelajar mendapat bilangan kuki atau biskut yang sama. Orang yang pertama dalam barisan mendapat bilangan kuki yang paling sedikit. Bilangan kuki atau biskut yang diterima oleh setiap pelajar adalah nombor semulajadi dari 1 hingga 9 dengan setiap nombor yang muncul sekurang -kurangnya sekali.
Jumlah kuki adalah dua lebih daripada jumlah biskut yang diedarkan. R yang berada di tengah -tengah garis menerima lebih banyak barang (cookies dan biskut disatukan) daripada orang lain. T menerima 8 lagi kuki daripada biskut. Orang yang terakhir dalam barisan menerima 10 item dalam semua, manakala P menerima hanya separuh daripada banyak sepenuhnya. Q adalah selepas p tetapi sebelum s dalam barisan. Bilangan kuki q yang diterima adalah sama dengan bilangan biskut p yang diterima. Q receives one more good than S and one less than R. Person second in the queue receives an odd number of biscuits and an odd number of cookies.
Question: Who was 4th in the queue?
Answer: Q was 4th in the queue.
Also read: How Can Prompt Engineering Transform LLM Reasoning Ability?
GPT-4o Analysis
GPT-4o failed to solve the problem correctly. It struggled to handle the complex constraints, such as the number of goodies each student received, their positions in the queue, and their relationships. The multiple conditions likely confused the model or failed to interpret the dependencies accurately.
OpenAI o1 Analysis
OpenAI o1 accurately deduced the correct order by efficiently analyzing all constraints. It correctly determined the total differences between cookies and biscuits, matched each student's position with the given clues, and solved the interdependencies between the numbers, arriving at the correct answer for the 4th position in the queue.
Verdict
GPT-4o failed to solve the problem due to difficulties with complex logical reasoning.
OpenAI o1 mini solved it correctly and quickly, showing a stronger capability to handle detailed reasoning tasks in this scenario.
Coding: Creating a Game
To check the coding capabilities of GPT-4o and OpenAI o1, I asked both the models to – Create a space shooter game in HTML and JS. Also, make sure the colors you use are blue and red. Here's the result:
GPT-4o
I asked GPT-4o to create a shooter game with a specific color palette, but the game used only blue color boxes instead. The color scheme I requested wasn't applied at all.
OpenAI o1
On the other hand, OpenAI o1 was a success because it accurately implemented the color palette I specified. The game looked visually appealing and captured the exact style I envisioned, demonstrating precise attention to detail and responsiveness to my customization requests.
GPT-4o vs OpenAI o1: API and Usage Details
The API documentation reveals several key features and trade-offs:
- Access and Support: The new models are currently available only to tier 5 API users, requiring a minimum spend of $1,000 on credits. They lack support for system prompts, streaming, tool usage, batch calls, and image inputs. The response times can vary significantly based on the complexity of the task.
- Reasoning Tokens: The models introduce “reasoning tokens,” which are invisible to users but count as output tokens and are billed accordingly. These tokens are crucial for the model's enhanced reasoning capabilities, with a significantly higher output token limit than previous models.
- Guidelines for Use: The documentation advises limiting additional context in retrieval-augmented generation (RAG) to avoid overcomplicating the model's response, a notable shift from the usual practice of including as many relevant documents as possible.
Also read: Here's How You Can Use GPT 4o API for Vision, Text, Image & More.
Hidden Reasoning Tokens
A controversial aspect is that the “reasoning tokens” remain hidden from users. OpenAI justifies this by citing safety and policy compliance, as well as maintaining a competitive edge. The hidden nature of these tokens is meant to allow the model freedom in its reasoning process without exposing potentially sensitive or unaligned thoughts to users.
Limitations of OpenAI o1
OpenAI's new model, o1, has several limitations despite its advancements in reasoning capabilities. Here are the key limitations:
- Limited Non-STEM Knowledge: While o1 excels in STEM-related tasks, its factual knowledge in non-STEM areas is less robust compared to larger models like GPT-4o. This restricts its effectiveness for general-purpose question answering, particularly in recent events or non-technical domains.
- Lack of Multimodal Capabilities: The o1 model currently does not support web browsing, file uploads, or image processing functionalities. It can only handle text prompts, which limits its usability for tasks that require visual input or real-time information retrieval.
- Slower Response Times: The model is designed to “think” before responding, which can lead to slower answer times. Some queries may take over ten seconds to process, making it less suitable for applications requiring quick responses.
- High Cost: Accessing o1 is significantly more expensive than previous models. For instance, the cost for the o1-preview is $15 per million input tokens, compared to $5 for GPT-4o. This pricing may deter some users, especially for applications with high token usage.
- Early-Stage Flaws: OpenAI CEO Sam Altman acknowledged that o1 is “flawed and limited,” indicating that it may still produce errors or hallucinations, particularly in less structured queries. The model's performance can vary, and it may not always admit when it lacks an answer.
- Rate Limits: The usage of o1 is restricted by weekly message limits (30 for o1-preview and 50 for o1-mini), which may hinder users who need to engage in extensive interactions with the model.
- Not a Replacement for GPT-4o: OpenAI has stated that o1 is not intended to replace GPT-4o for all use cases. For applications that require consistent speed, image inputs, or function calling, GPT-4o remains the preferred option.
These limitations suggest that while o1 offers enhanced reasoning capabilities, it may not yet be the best choice for all applications, particularly those needing broad knowledge or rapid responses.
OpenAI o1 Struggles With Q&A Tasks on Recent Events and Entities

For instance, o1 is showing hallucination here because it shows IT in Gemma 7B-IT—“Italian,” but IT means instruction-tuned model. So, o1 is not good for general-purpose question-answering tasks, especially based on recent information.
Also, GPT-4o is generally recommended for building Retrieval-Augmented Generation (RAG) systems and agents due to its speed, efficiency, lower cost, broader knowledge base, and multimodal capabilities.
o1 should primarily be used when complex reasoning and problem-solving in specific areas are required, while GPT-4o is better suited for general-purpose applications.
OpenAI o1 is Better at Logical Reasoning than GPT-4o
GPT-4o is Terrible at Simple Logical Reasoning

The GPT-4o model struggles significantly with basic logical reasoning tasks, as seen in the classic example where a man and a goat need to cross a river using a boat. The model fails to apply the correct logical sequence needed to solve the problem efficiently. Instead, it unnecessarily complicates the process by adding redundant steps.
In the provided example, GPT-4o suggests:
- Step 1 : The man rows the goat across the river and leaves the goat on the other side.
- Step 2 : The man rows back alone to the original side of the river.
- Step 3 : The man crosses the river again, this time by himself.
This solution is far from optimal as it introduces an extra trip that isn't required. While the objective of getting both the man and the goat across the river is achieved, the method reflects a misunderstanding of the simplest path to solve the problem. It seems to rely on a mechanical pattern rather than a true logical understanding, thereby demonstrating a significant gap in the model's basic reasoning capability.
OpenAI o1 Does Better in Logical Reasoning
In contrast, the OpenAI o1 model better understands logical reasoning. When presented with the same problem, it identifies a simpler and more efficient solution:
- Both the Man and the Goat Board the Boat : The man leads the goat into the boat.
- Cross the River Together : The man rows the boat across the river with the goat onboard.
- Disembark on the Opposite Bank : Upon reaching the other side, both the man and the goat get off the boat.
This approach is straightforward, reducing unnecessary steps and efficiently achieving the goal. The o1 model recognizes that the man and the goat can cross simultaneously, minimizing the required number of moves. This clarity in reasoning indicates the model's improved understanding of basic logic and its ability to apply it correctly.
OpenAI o1 – Chain of Thought Before Answering
A key advantage of the OpenAI o1 model lies in its use of chain-of-thought reasoning . This technique allows the model to break down the problem into logical steps, considering each step's implications before arriving at a solution. Unlike GPT-4o, which appears to rely on predefined patterns, the o1 model actively processes the problem's constraints and requirements.
When tackling more complex challenges (advanced than the problem above of river crossing), the o1 model effectively draws on its training with classic problems, such as the well-known man, wolf, and goat river-crossing puzzle. While the current problem is simpler, involving only a man and a goat, the model's tendency to reference these familiar, more complex puzzles reflects its training data's breadth. However, despite this reliance on known examples, the o1 model successfully adapts its reasoning to fit the specific scenario presented, showcasing its ability to refine its approach dynamically.
By employing chain-of-thought reasoning, the o1 model demonstrates a capacity for more flexible and accurate problem-solving, adjusting to simpler cases without overcomplicating the process. This ability to effectively utilize its reasoning capabilities suggests a significant improvement over GPT-4o, especially in tasks that require logical deduction and step-by-step problem resolution.
The Final Verdict: GPT-4o vs OpenAI o1

Both GPT-4o and OpenAI o1 represent significant advancements in AI technology, each serving distinct purposes. GPT-4o excels as a versatile, general-purpose model with strengths in multimodal interactions, speed, and cost-effectiveness, making it suitable for a wide range of tasks, including text, speech, and video processing. Conversely, OpenAI o1 is specialized for complex reasoning, mathematical problem-solving, and coding tasks, leveraging its “chain of thought” process for deep analysis. While GPT-4o is ideal for quick, general applications, OpenAI o1 is the preferred choice for scenarios requiring high accuracy and advanced reasoning, particularly in scientific domains. The choice depends on task-specific needs.
Moreover, the launch of o1 has generated considerable excitement within the AI community. Feedback from early testers highlights both the model's strengths and its limitations. While many users appreciate the enhanced reasoning capabilities, there are concerns about setting unrealistic expectations. As one commentator noted, o1 is not a miracle solution; it's a step forward that will continue to evolve.
Looking ahead, the AI landscape is poised for rapid development. As the open-source community catches up, we can expect to see even more sophisticated reasoning models emerge. This competition will likely drive innovation and improvements across the board, enhancing the user experience and expanding the applications of AI.
Also read: Reasoning in Large Language Models: A Geometric Perspective
Kesimpulan
In a nutshell, both GPT-4o vs OpenAI o1 represent significant advancements in AI technology, they cater to different needs: GPT-4o is a general-purpose model that excels in a wide variety of tasks, particularly those that benefit from multimodal interaction and quick processing. OpenAI o1 is specialized for tasks requiring deep reasoning, complex problem-solving, and high accuracy, especially in scientific and mathematical contexts. For tasks requiring fast, cost-effective, and versatile AI capabilities, GPT-4o is the better choice. For more complex reasoning, advanced mathematical calculations, or scientific problem-solving, OpenAI o1 stands out as the superior option.
Ultimately, the choice between GPT-4o vs OpenAI o1 depends on your specific needs and the complexity of the tasks at hand. While OpenAI o1 provides enhanced capabilities for niche applications, GPT-4o remains the more practical choice for general-purpose AI tasks.
Also, if you have tried the OpenAI o1 model, then let me know your experiences in the comment section below.
Sekiranya anda ingin menjadi pakar AI generatif, maka meneroka: Program Pinnacle Genai
Rujukan
- OpenAI Models
- o1-preview and o1-mini
- OpenAI System Card
- Openai O1-Mini
- OpenAI API
- Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
Ans. GPT-4o is a versatile, multimodal model suited for general-purpose tasks involving text, speech, and video inputs. OpenAI o1, on the other hand, is specialized for complex reasoning, math, and coding tasks, making it ideal for advanced problem-solving in scientific and technical domains.
S2. Which model(GPT-4o or OpenAI o1) is better for multilingual tasks?Ans. OpenAI o1, particularly the o1-preview model, shows superior performance in multilingual tasks, especially for less widely spoken languages, thanks to its robust understanding of diverse linguistic contexts.
Q3. How does OpenAI o1 handle complex reasoning tasks?Ans. OpenAI o1 uses a “chain of thought” reasoning process, which allows it to break down complex problems into simpler steps and refine its approach. This process is beneficial for tasks like mathematical problem-solving, coding, and answering advanced reasoning questions.
Q4. What are the limitations of OpenAI o1?Ans. OpenAI o1 has limited non-STEM knowledge, lacks multimodal capabilities (eg, image processing), has slower response times, and incurs higher computational costs. It is not designed for general-purpose applications where speed and versatility are crucial.
S5. When should I choose GPT-4o over OpenAI o1?Ans. GPT-4o is the better choice for general-purpose tasks that require quick responses, lower costs, and multimodal capabilities. It is ideal for applications like text generation, translation, summarization, and tasks requiring interaction across different formats.
Atas ialah kandungan terperinci GPT-4O vs OpenAI O1: Adakah model Openai baru bernilai gembar-gembur?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Beyond the Llama Drama: 4 Benchmarks Baru Untuk Model Bahasa BesarApr 14, 2025 am 11:09 AM
Beyond the Llama Drama: 4 Benchmarks Baru Untuk Model Bahasa BesarApr 14, 2025 am 11:09 AMPenanda Aras Bermasalah: Kajian Kes Llama Pada awal April 2025, Meta melancarkan model Llama 4 suite, dengan metrik prestasi yang mengagumkan yang meletakkan mereka dengan baik terhadap pesaing seperti GPT-4O dan Claude 3.5 sonnet. Pusat ke LAUNC
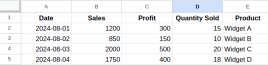 Apakah pemformatan data dalam Excel? - Analytics VidhyaApr 14, 2025 am 11:05 AM
Apakah pemformatan data dalam Excel? - Analytics VidhyaApr 14, 2025 am 11:05 AMPengenalan Mengendalikan data dengan cekap dalam Excel boleh mencabar untuk penganalisis. Memandangkan keputusan perniagaan penting bergantung pada laporan yang tepat, kesilapan pemformatan boleh membawa kepada isu -isu penting. Artikel ini akan membantu anda
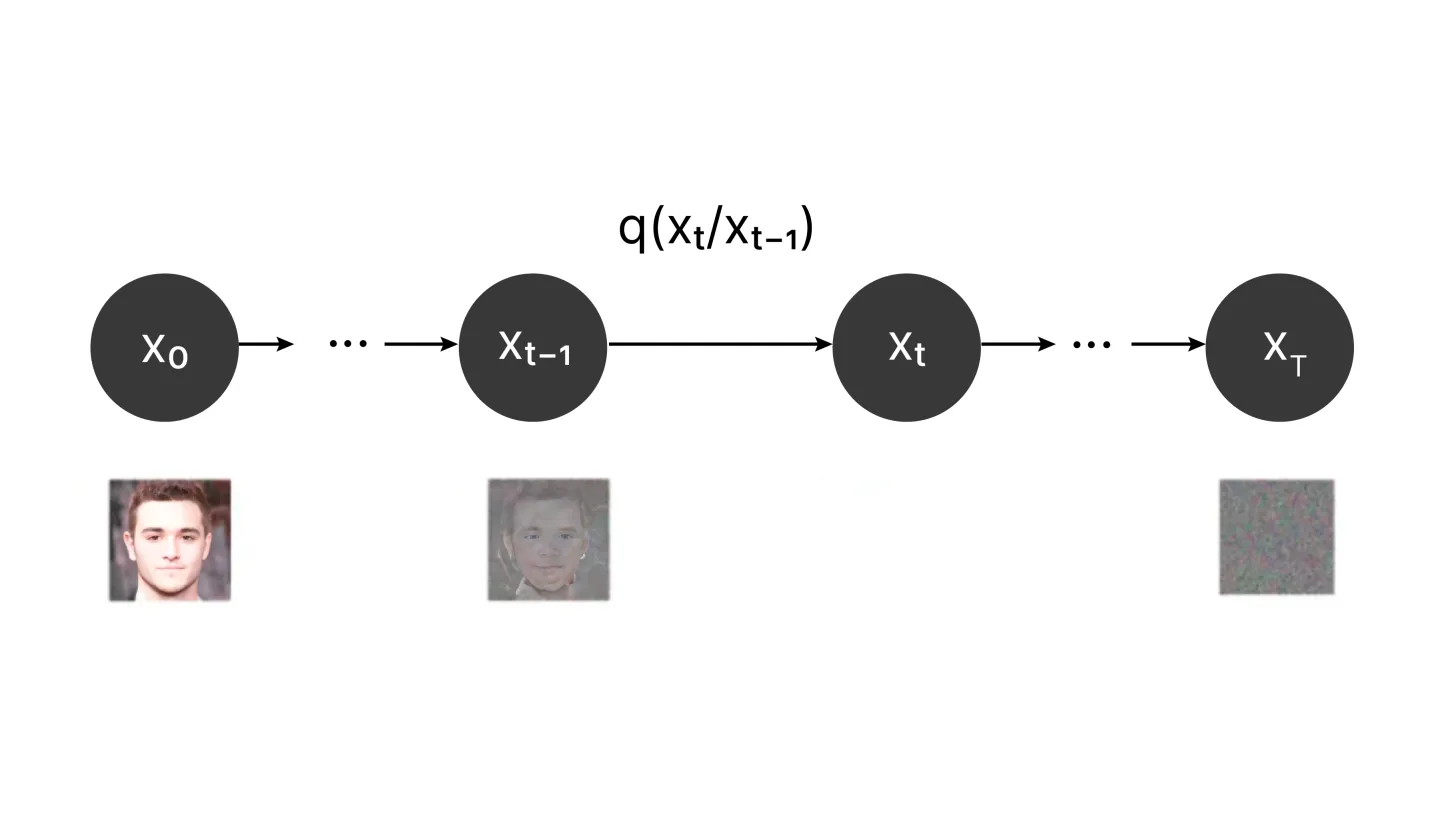 Apakah model penyebaran?Apr 14, 2025 am 11:00 AM
Apakah model penyebaran?Apr 14, 2025 am 11:00 AMMenyelam ke dunia model penyebaran: panduan komprehensif Bayangkan menonton mekar dakwat merentasi halaman, warnanya secara terang -terangan meresap sehingga corak yang menawan muncul. Proses penyebaran semulajadi ini, di mana zarah bergerak dari tinggi ke konsentrati rendah
 Apakah fungsi heuristik dalam AI? - Analytics VidhyaApr 14, 2025 am 10:51 AM
Apakah fungsi heuristik dalam AI? - Analytics VidhyaApr 14, 2025 am 10:51 AMPengenalan Bayangkan menavigasi maze yang kompleks - matlamat anda adalah untuk melarikan diri secepat mungkin. Berapa banyak jalan yang ada? Sekarang, gambar mempunyai peta yang menyoroti laluan yang menjanjikan dan hujung mati. Itulah intipati fungsi heuristik dalam buatan i
 Panduan komprehensif mengenai algoritma mundurApr 14, 2025 am 10:45 AM
Panduan komprehensif mengenai algoritma mundurApr 14, 2025 am 10:45 AMPengenalan Algoritma backtracking adalah teknik penyelesaian masalah yang kuat yang secara bertahap membina penyelesaian calon. Ini adalah kaedah yang digunakan secara meluas dalam sains komputer, secara sistematik meneroka semua jalan yang mungkin sebelum membuang mana -mana potenti
 5 saluran YouTube terbaik untuk mempelajari statistik secara percumaApr 14, 2025 am 10:38 AM
5 saluran YouTube terbaik untuk mempelajari statistik secara percumaApr 14, 2025 am 10:38 AMPengenalan Statistik adalah kemahiran penting, yang jauh melebihi akademik. Sama ada anda mengejar sains data, menjalankan penyelidikan, atau hanya menguruskan maklumat peribadi, pemahaman statistik adalah penting. Internet, dan terutamanya jarak
 Avbytes: Perkembangan dan Cabaran Utama dalam Generatif AI - Analytics VidhyaApr 14, 2025 am 10:36 AM
Avbytes: Perkembangan dan Cabaran Utama dalam Generatif AI - Analytics VidhyaApr 14, 2025 am 10:36 AMPengenalan Hei ada, peminat AI! Selamat datang ke AV Bytes, sumber kejiranan mesra anda untuk semua perkara AI. Buckle up, kerana minggu ini telah menjadi perjalanan liar di dunia AI! Kami mempunyai beberapa perkara yang bertiup
 Aplikasi Rag Hosting Self pada peranti tepi dengan LangkhainApr 14, 2025 am 10:35 AM
Aplikasi Rag Hosting Self pada peranti tepi dengan LangkhainApr 14, 2025 am 10:35 AMPengenalan Di bahagian kedua siri kami untuk membina aplikasi RAG pada Raspberry Pi, kami akan memperluaskan asas yang kami letakkan di bahagian pertama, di mana kami mencipta dan menguji saluran paip teras. Pada bahagian pertama, kami crea


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

