



Pengenalan
Model bahasa besar (LLMS) menyumbang kepada kemajuan pemprosesan bahasa semulajadi (NLP), tetapi mereka juga menimbulkan beberapa soalan penting mengenai kecekapan pengiraan. Model -model ini telah menjadi terlalu besar, jadi kos latihan dan kesimpulan tidak lagi dalam had yang munasabah.
Untuk menangani ini, Undang -undang Skala Chinchilla, yang diperkenalkan oleh Hoffmann et al. Pada tahun 2022, menyediakan rangka kerja pecah tanah untuk mengoptimumkan latihan LLM. Undang -undang Skala Chinchilla menawarkan panduan penting untuk mengukur LLM dengan cekap tanpa menjejaskan prestasi dengan mewujudkan hubungan antara saiz model, data latihan, dan sumber pengiraan. Kami akan membincangkannya secara terperinci dalam artikel ini.

Gambaran Keseluruhan
- Undang -undang skala Chinchilla mengoptimumkan latihan LLM dengan mengimbangi saiz model dan jumlah data untuk kecekapan yang dipertingkatkan.
- Wawasan skala baru menunjukkan bahawa model bahasa yang lebih kecil seperti Chinchilla dapat mengatasi yang lebih besar apabila dilatih pada lebih banyak data.
- Pendekatan Chinchilla mencabar skala LLM tradisional dengan mengutamakan kuantiti data berbanding saiz model untuk mengira kecekapan.
- Undang-undang Skala Chinchilla menawarkan pelan tindakan baru untuk NLP, membimbing pembangunan model yang berprestasi tinggi dan cekap.
- Undang -undang Skala Chinchilla memaksimumkan prestasi model bahasa dengan kos pengiraan yang minimum dengan menggandakan saiz model dan data latihan.
Jadual Kandungan
- Apakah Undang -undang Skala Chinchilla?
- Peralihan fokus: dari saiz model ke data
- Gambaran Keseluruhan Undang -undang Skala Chinchilla
- Penemuan Utama Undang -undang Skala Chinchilla
- Latihan pengiraan-optimum
- Bukti empirikal dari lebih daripada 400 model
- Anggaran yang disemak semula dan peningkatan berterusan
- Faedah pendekatan chinchilla
- Prestasi yang lebih baik
- Kos pengiraan yang lebih rendah
- Implikasi untuk penyelidikan dan pembangunan model masa depan
- Cabaran dan pertimbangan
- Soalan yang sering ditanya
Apakah Undang -undang Skala Chinchilla?
Kertas "Model Bahasa Besar Komputasi Latihan," yang diterbitkan pada tahun 2022, memberi tumpuan kepada mengenal pasti hubungan antara tiga faktor utama: saiz model, bilangan token, dan anggaran anggaran. Penulis mendapati bahawa model bahasa besar yang sedia ada (LLMs) seperti GPT-3 (parameter 175B), Gopher (280b), dan Megatron (530b) adalah sangat terurai. Walaupun model -model ini meningkat dalam saiz, jumlah data latihan kekal malar, yang membawa kepada prestasi suboptimal. Penulis mencadangkan bahawa saiz model dan bilangan token latihan mesti diperkatakan sama untuk latihan pengiraan-optimum. Untuk membuktikannya, mereka melatih sekitar 400 model, dari 70 juta hingga lebih 16 bilion parameter, menggunakan antara 5 dan 500 bilion token.
Berdasarkan penemuan ini, penulis melatih model baru yang dipanggil Chinchilla, yang menggunakan anggaran pengiraan yang sama seperti Gopher (280b) tetapi dengan hanya parameter 70B dan empat kali lebih banyak data latihan. Chinchilla mengatasi beberapa LLM yang terkenal, termasuk Gopher (280b), GPT-3 (175b), Jurassic-1 (178b), dan Megatron (530b). Hasil ini bercanggah dengan undang -undang skala yang dicadangkan oleh OpenAI dalam "Undang -undang Skala untuk LLMS," yang mencadangkan bahawa model yang lebih besar akan sentiasa melakukan lebih baik. Undang -undang skala Chinchilla menunjukkan bahawa model yang lebih kecil apabila dilatih pada lebih banyak data, dapat mencapai prestasi unggul. Pendekatan ini juga menjadikan model yang lebih kecil lebih mudah untuk menyesuaikan diri dan mengurangkan latensi kesimpulan.
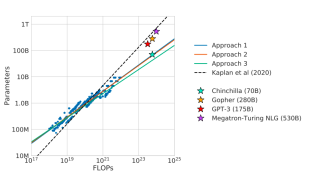
Grafik menunjukkan bahawa, walaupun lebih kecil, Chinchilla (70b) mengikuti nisbah pengiraan-ke-parameter yang berbeza dan mengatasi model yang lebih besar seperti Gopher dan GPT-3.
Pendekatan lain (1, 2, dan 3) meneroka cara yang berbeza untuk mengoptimumkan prestasi model berdasarkan peruntukan pengiraan.
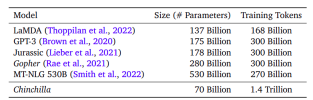
Dari angka ini, kita dapat melihat kelebihan Chinchilla walaupun chinchilla lebih kecil dalam saiz (parameter 70B), ia dilatih pada dataset yang lebih besar (1.4 trilion token), yang mengikuti prinsip yang diperkenalkan di Chinchilla skala-model yang lebih besar jika mereka lebih banyak. 530B mempunyai lebih banyak parameter tetapi dilatih pada token yang agak kurang, menunjukkan bahawa model -model ini mungkin tidak mengoptimumkan sepenuhnya potensi pengiraan mereka.
Peralihan fokus: dari saiz model ke data
Dari segi sejarah, tumpuan dalam meningkatkan prestasi LLM telah meningkatkan saiz model, seperti yang dilihat dalam model seperti GPT-3 dan Gopher. Ini didorong oleh penyelidikan Kaplan et al. (2020), yang mencadangkan hubungan kuasa undang-undang antara saiz model dan prestasi. Walau bagaimanapun, apabila model meningkat lebih besar, jumlah data latihan tidak skala dengan sewajarnya, mengakibatkan potensi pengiraan yang kurang dimanfaatkan. Undang-undang skala Chinchilla mencabar ini dengan menunjukkan bahawa peruntukan sumber yang lebih seimbang, terutamanya dari segi data dan saiz model, boleh membawa kepada model pengiraan-optimum yang melakukan lebih baik tanpa mencapai kerugian yang paling rendah.
Gambaran Keseluruhan Undang -undang Skala Chinchilla
Perdagangan antara saiz model, token latihan, dan kos pengiraan adalah teras undang-undang skala Chinchilla. Undang-undang mewujudkan keseimbangan pengiraan antara ketiga-tiga parameter ini:
- Saiz Model (N) : Bilangan parameter dalam model.
- Token Latihan (D) : Jumlah token yang digunakan semasa latihan.
- Kos pengiraan (c) : Jumlah sumber pengiraan yang diperuntukkan untuk latihan, biasanya diukur dalam flop (operasi titik terapung sesaat).
Undang -undang skala Chinchilla menunjukkan bahawa untuk prestasi optimum, kedua -dua saiz model dan jumlah data latihan harus skala pada kadar yang sama. Khususnya, bilangan token latihan juga harus berganda untuk setiap dua kali ganda saiz model. Pendekatan ini membezakan kaedah terdahulu, yang menekankan peningkatan saiz model tanpa cukup meningkatkan data latihan.
Hubungan ini dinyatakan secara matematik sebagai:
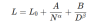
Di mana:
- L adalah kehilangan akhir model.
- L_0 adalah kerugian yang tidak dapat dielakkan, yang mewakili prestasi terbaik.
- A dan B adalah pemalar yang menangkap prestasi yang kurang baik model berbanding dengan proses generatif yang ideal.
- α dan β adalah eksponen yang menggambarkan bagaimana skala kerugian berkenaan dengan saiz model dan saiz data, masing -masing.
Penemuan Utama Undang -undang Skala Chinchilla
Berikut adalah penemuan utama Undang -undang Skala Chinchilla:
Latihan pengiraan-optimum
Undang -undang Skala Chinchilla menyoroti keseimbangan optimum antara saiz model dan jumlah data latihan. Khususnya, kajian mendapati bahawa nisbah anggaran 20 token latihan bagi setiap parameter model sangat sesuai untuk mencapai prestasi terbaik dengan anggaran pengiraan yang diberikan. Sebagai contoh, model Chinchilla, dengan 70 bilion parameter, dilatih pada 1.4 trilion token -empat kali lebih banyak daripada Gopher tetapi dengan parameter yang jauh lebih sedikit. Baki ini menghasilkan model yang jauh lebih baik daripada model yang lebih besar pada beberapa tanda aras.
Bukti empirikal dari lebih daripada 400 model
Untuk mendapatkan undang -undang skala chinchilla, Hoffmann et al. Dilatih lebih daripada 400 model pengubah, berukuran dari 70 juta hingga 16 bilion parameter, pada dataset sehingga 500 bilion token. Bukti empirikal sangat menyokong hipotesis bahawa model yang dilatih dengan lebih banyak data (pada anggaran pengiraan tetap) melakukan lebih baik daripada hanya meningkatkan saiz model sahaja.
Anggaran yang disemak semula dan peningkatan berterusan
Penyelidikan seterusnya telah berusaha untuk memperbaiki penemuan awal Hoffmann et al., Mengenal pasti kemungkinan pelarasan dalam anggaran parameter. Sesetengah kajian telah mencadangkan ketidakkonsistenan kecil dalam hasil asal dan telah mencadangkan anggaran yang disemak agar sesuai dengan data yang diperhatikan dengan lebih baik. Pelarasan ini menunjukkan bahawa penyelidikan lanjut diperlukan untuk memahami dinamik model skala sepenuhnya, tetapi pandangan teras undang -undang skala chinchilla tetap menjadi garis panduan yang berharga.
Faedah pendekatan chinchilla
Berikut adalah manfaat pendekatan Chinchilla:
Prestasi yang lebih baik
Chinchilla yang sama dengan saiz model dan data latihan menghasilkan hasil yang luar biasa. Walaupun lebih kecil daripada banyak model besar lain, Chinchilla mengatasi GPT-3, Gopher, dan juga model NLG megatron yang besar (530 bilion parameter) pada pelbagai tanda aras. Sebagai contoh, pada penanda aras Pemahaman Bahasa Multitask (MMLU) yang besar, Chinchilla mencapai ketepatan purata 67.5%, peningkatan yang ketara ke atas 60%Gopher.
Kos pengiraan yang lebih rendah
Pendekatan Chinchilla mengoptimumkan prestasi dan mengurangkan kos pengiraan dan tenaga untuk latihan dan kesimpulan. Model latihan seperti GPT-3 dan Gopher memerlukan sumber pengkomputeran yang besar, menjadikan penggunaannya dalam aplikasi dunia nyata yang mahal. Sebaliknya, saiz model kecil Chinchilla dan data latihan yang lebih luas menghasilkan keperluan pengiraan yang lebih rendah untuk penalaan dan kesimpulan, menjadikannya lebih mudah untuk aplikasi hiliran.
Implikasi untuk penyelidikan dan pembangunan model masa depan
Undang -undang skala Chinchilla menawarkan pandangan yang berharga untuk masa depan pembangunan LLM. Implikasi utama termasuk:
- Reka Bentuk Model Panduan: Memahami Cara Mengimbangi Saiz Model dan Data Latihan membolehkan penyelidik dan pemaju membuat keputusan yang lebih tepat apabila mereka bentuk model baru. Dengan mematuhi prinsip-prinsip yang digariskan dalam Undang-undang Skala Chinchilla, pemaju dapat memastikan bahawa model mereka adalah kedua-dua efisien dan berprestasi tinggi.
- Reka Bentuk Model Panduan : Pengetahuan tentang mengoptimumkan kelantangan dan oleh itu data latihan memberitahu penyelidikan dan reka bentuk model. Dalam skala garis panduan ini, perkembangan idea mereka akan beroperasi dalam definisi luas kecekapan tinggi tanpa penggunaan sumber komputer yang berlebihan.
- Pengoptimuman Prestasi : Undang -undang Skala Chinchilla menyediakan peta jalan untuk mengoptimumkan LLM. Dengan memberi tumpuan kepada skala yang sama, pemaju boleh mengelakkan perangkap model yang kurang latihan dan memastikan model dioptimumkan untuk tugas latihan dan kesimpulan.
- Eksplorasi Beyond Chinchilla : Ketika penyelidikan berterusan, strategi baru muncul untuk memperluaskan idea -idea Undang -undang Skala Chinchilla. Sebagai contoh, sesetengah penyelidik sedang menyiasat cara untuk mencapai tahap prestasi yang sama dengan sumber pengiraan yang lebih sedikit atau untuk meningkatkan prestasi model dalam persekitaran yang terkawal data. Penjelajahan ini mungkin menghasilkan saluran paip latihan yang lebih cekap.
Cabaran dan pertimbangan
Walaupun Undang -undang Skala Chinchilla menandakan satu langkah penting dalam memahami skala LLM, ia juga menimbulkan persoalan dan cabaran baru:
- Pengumpulan Data: Seperti halnya Chinchilla, melatih model dengan token 1.4 trilion menunjukkan ketersediaan banyak dataset berkualiti tinggi. Walau bagaimanapun, skala pengumpulan data dan pemprosesan menimbulkan masalah organisasi untuk penyelidik dan pemaju, serta masalah etika, seperti privasi dan kecenderungan.
- Bias dan ketoksikan: Walau bagaimanapun, pengurangan proporsional bias dan ketoksikan biasa model yang terlatih menggunakan undang -undang skala Chinchilla lebih mudah dan lebih cekap daripada semua masalah ketidakcekapan ini. Memandangkan LLMs berkembang berkuasa dan mencapai, memastikan keadilan dan mengurangkan output berbahaya akan menjadi bidang fokus penting untuk penyelidikan masa depan.
Kesimpulan
Undang -undang Skala Chinchilla mewakili kemajuan penting dalam pemahaman kita untuk mengoptimumkan latihan model bahasa yang besar. Dengan mewujudkan hubungan yang jelas antara saiz model, data latihan, dan kos pengiraan, undang-undang menyediakan rangka kerja yang komputasi untuk mengukur LLMs dengan cekap. Kejayaan model Chinchilla menunjukkan manfaat praktikal pendekatan ini, baik dari segi prestasi dan kecekapan sumber.
Sebagai penyelidikan di kawasan ini berterusan, prinsip -prinsip Undang -undang Skala Chinchilla mungkin akan membentuk masa depan pembangunan LLM, membimbing reka bentuk model yang mendorong sempadan apa yang mungkin dalam pemprosesan bahasa semulajadi sambil mengekalkan kemampanan dan kebolehcapaian.
Juga, jika anda mencari kursus AI generatif dalam talian, kemudian meneroka: Program Pinnacle Bename!
Soalan yang sering ditanya
Q1. Apakah Undang -undang Skala Chinchilla?Ans. Undang -undang Skala Chinchilla adalah rangka kerja empirikal yang menggambarkan hubungan optimum antara saiz model bahasa (bilangan parameter), jumlah data latihan (token), dan sumber pengiraan yang diperlukan untuk latihan. Ia bertujuan untuk meminimumkan pengiraan latihan sambil memaksimumkan prestasi model.
S2. Apakah parameter utama dalam undang -undang skala chinchilla? Ans. Parameter utama termasuk:
1. N: Bilangan parameter dalam model.
2. D: Bilangan token latihan.
3. C: Jumlah kos pengiraan dalam jepit.
4. L: Kerugian purata yang dicapai oleh model pada dataset ujian.
5. A dan B: Pemalar mencerminkan prestasi yang kurang baik berbanding dengan proses generatif yang ideal.
6. α dan β: Eksponen yang menerangkan bagaimana skala kerugian mengenai model dan saiz data, masing -masing.
Ans. Undang -undang menunjukkan bahawa kedua -dua saiz model dan token latihan harus skala pada kadar yang sama untuk prestasi optimum. Khususnya, untuk setiap dua kali ganda saiz model, bilangan token latihan juga harus berganda, biasanya bertujuan untuk nisbah sekitar 20 token setiap parameter.
Q4. Apakah beberapa kritikan atau batasan undang -undang skala chinchilla?Ans. Kajian baru -baru ini telah menunjukkan isu -isu yang berpotensi dengan anggaran asal Hoffmann et al., Termasuk ketidakkonsistenan dalam data yang dilaporkan dan selang keyakinan yang terlalu ketat. Sesetengah penyelidik berpendapat bahawa undang -undang skala mungkin terlalu sederhana dan tidak menyumbang kepada pelbagai pertimbangan praktikal dalam latihan model.
S5. Bagaimanakah undang -undang skala Chinchilla mempengaruhi perkembangan model bahasa baru -baru ini?Ans. Penemuan dari Undang -undang Skala Chinchilla telah memaklumkan beberapa proses reka bentuk dan latihan model yang terkenal, termasuk Suite Gemini Google. Ia juga telah mendorong perbincangan mengenai strategi "melampaui chinchilla", di mana penyelidik meneroka model latihan yang lebih besar daripada optimum mengikut undang -undang skala asal.
Atas ialah kandungan terperinci Apakah Undang -undang Skala Chinchilla?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Adakah Model Model ' S 7B Olympiccoder mengalahkan Claude 3.7?Apr 23, 2025 am 11:49 AM
Adakah Model Model ' S 7B Olympiccoder mengalahkan Claude 3.7?Apr 23, 2025 am 11:49 AMMemeluk Olimpikcoder-7B: Model Penaakulan Kod Terbuka Sumber Terbuka yang kuat Perlumbaan untuk membangunkan model bahasa yang tertumpu kepada kod unggul semakin meningkat, dan Hugging Face telah menyertai pertandingan dengan pesaing yang hebat: Olympiccoder-7b, produk
 4 ciri Gemini baru yang anda tidak dapat merinduiApr 23, 2025 am 11:48 AM
4 ciri Gemini baru yang anda tidak dapat merinduiApr 23, 2025 am 11:48 AMBerapa banyak daripada anda yang berharap AI dapat melakukan lebih daripada sekadar menjawab soalan? Saya tahu saya ada, dan sejak kebelakangan ini, saya kagum dengan bagaimana ia berubah. AI Chatbots bukan sekadar berbual lagi, mereka sedang membuat, Researchin
 Camunda menulis skor baru untuk orkestra ai agentikApr 23, 2025 am 11:46 AM
Camunda menulis skor baru untuk orkestra ai agentikApr 23, 2025 am 11:46 AMOleh kerana Smart AI mula diintegrasikan ke dalam semua peringkat platform dan aplikasi perisian perusahaan (kita harus menekankan bahawa terdapat kedua -dua alat teras yang kuat dan beberapa alat simulasi yang kurang dipercayai), kita memerlukan satu set baru keupayaan infrastruktur untuk menguruskan agen -agen ini. Camunda, sebuah syarikat orkestrasi proses yang berpusat di Berlin, Jerman, percaya ia dapat membantu Smart AI memainkan peranannya yang sewajarnya dan selaras dengan matlamat dan peraturan perniagaan yang tepat di tempat kerja digital yang baru. Syarikat ini kini menawarkan keupayaan orkestra pintar yang direka untuk membantu model organisasi, menggunakan dan mengurus ejen AI. Dari perspektif kejuruteraan perisian praktikal, apakah maksudnya? Integrasi proses kepastian dan bukan deterministik Syarikat itu mengatakan yang penting adalah untuk membolehkan pengguna (biasanya saintis data, perisian)
 Adakah nilai dalam pengalaman AI perusahaan yang dikendalikan?Apr 23, 2025 am 11:45 AM
Adakah nilai dalam pengalaman AI perusahaan yang dikendalikan?Apr 23, 2025 am 11:45 AMMenghadiri Google Cloud Seterusnya '25, saya berminat untuk melihat bagaimana Google akan membezakan tawaran AInya. Pengumuman baru -baru ini mengenai Agentspace (dibincangkan di sini) dan Suite Pengalaman Pelanggan (dibincangkan di sini) menjanjikan, menekankan perniagaan Valu
 Bagaimana untuk mencari model penyembuhan berbilang bahasa terbaik untuk kain anda?Apr 23, 2025 am 11:44 AM
Bagaimana untuk mencari model penyembuhan berbilang bahasa terbaik untuk kain anda?Apr 23, 2025 am 11:44 AMMemilih model penyembuhan berbilang bahasa yang optimum untuk sistem pengambilan semula (RAG) pengambilan anda Di dunia yang saling berkaitan hari ini, membina sistem AI berbilang bahasa yang berkesan adalah yang paling utama. Model penyembuhan berbilang bahasa yang teguh adalah penting untuk Re
 Musk: Robotaxis di Austin memerlukan campur tangan setiap 10,000 batuApr 23, 2025 am 11:42 AM
Musk: Robotaxis di Austin memerlukan campur tangan setiap 10,000 batuApr 23, 2025 am 11:42 AMPelancaran Austin Robotaxi Tesla: Melihat lebih dekat dengan tuntutan Musk Elon Musk baru-baru ini mengumumkan pelancaran Robotaxi yang akan datang di Tesla di Austin, Texas, pada mulanya mengerahkan armada kecil 10-20 kenderaan untuk alasan keselamatan, dengan rancangan untuk pengembangan pesat. H
 AI 'Apr 23, 2025 am 11:41 AM
AI 'Apr 23, 2025 am 11:41 AMCara kecerdasan buatan digunakan mungkin tidak dijangka. Pada mulanya, ramai di antara kita mungkin berfikir ia digunakan terutamanya untuk tugas kreatif dan teknikal, seperti menulis kod dan membuat kandungan. Walau bagaimanapun, satu tinjauan baru -baru ini yang dilaporkan oleh Harvard Business Review menunjukkan bahawa ini tidak berlaku. Kebanyakan pengguna mencari kecerdasan buatan bukan hanya untuk kerja, tetapi untuk sokongan, organisasi, dan juga persahabatan! Laporan itu mengatakan bahawa kes permohonan AI yang pertama adalah rawatan dan persahabatan. Ini menunjukkan bahawa ketersediaan 24/7 dan keupayaan untuk memberikan nasihat dan maklum balas yang jujur, jujur adalah nilai yang sangat baik. Sebaliknya, tugas pemasaran (seperti menulis blog, mewujudkan jawatan media sosial, atau salinan pengiklanan) yang lebih rendah pada senarai penggunaan popular. Mengapa ini? Mari kita lihat hasil penyelidikan dan bagaimana ia terus menjadi
 Syarikat berlumba ke arah pengangkatan ejen AIApr 23, 2025 am 11:40 AM
Syarikat berlumba ke arah pengangkatan ejen AIApr 23, 2025 am 11:40 AMKebangkitan agen AI mengubah landskap perniagaan. Berbanding dengan revolusi awan, kesan agen AI diramalkan secara eksponen lebih besar, menjanjikan untuk merevolusikan kerja pengetahuan. Keupayaan untuk mensimulasikan keputusan-maki manusia


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

