



Pembelajaran Mesin (ML) kini menjadi landasan teknologi moden, memperkasakan perniagaan dan penyelidik untuk membuat keputusan yang lebih tepat. disesuaikan dengan keperluan individu.

Jadual Kandungan
- Definisi pemilihan model
- Kepentingan pemilihan model
- Bagaimana untuk memilih set model awal?
- Bagaimana untuk memilih model terbaik dari model yang dipilih (teknik pemilihan model)?
- kesimpulannya
- Soalan yang sering ditanya
Definisi pemilihan model
Pemilihan model merujuk kepada proses mengenal pasti model pembelajaran mesin yang paling sesuai untuk tugas tertentu dengan menilai pelbagai pilihan berdasarkan prestasi model dan konsistensi dengan keperluan masalah. Ia melibatkan mempertimbangkan faktor -faktor seperti jenis masalah (mis., Klasifikasi atau regresi), ciri -ciri data, metrik prestasi yang relevan, dan tradeoffs antara underfitting dan overfitting. Keterbatasan praktikal, seperti sumber pengkomputeran dan keperluan untuk interpretasi, juga boleh mempengaruhi pilihan. Matlamatnya adalah untuk memilih model yang menyediakan prestasi terbaik dan memenuhi matlamat projek dan kekangan.
Kepentingan pemilihan model
Memilih model pembelajaran mesin yang betul (ML) adalah langkah penting dalam membangunkan penyelesaian AI yang berjaya. Kepentingan pemilihan model terletak pada kesannya terhadap prestasi, kecekapan, dan kemungkinan aplikasi ML. Inilah sebab -sebab pentingnya:
1. Ketepatan dan prestasi
Model yang berbeza adalah baik pada jenis tugas yang berbeza. Sebagai contoh, pokok keputusan mungkin sesuai untuk data diklasifikasikan, sementara rangkaian saraf konvolusi (CNN) adalah baik pada pengiktirafan imej. Memilih model yang salah boleh mengakibatkan ramalan suboptimal atau kadar kesilapan yang tinggi, mengurangkan kebolehpercayaan penyelesaian.
2. Kecekapan dan Skala
Kerumitan komputasi model ML mempengaruhi latihan dan masa kesimpulannya. Untuk aplikasi berskala besar atau masa nyata, model ringan seperti regresi linear atau hutan rawak mungkin lebih sesuai daripada rangkaian saraf intensif yang komputasi.
Model yang tidak dapat ditingkatkan dengan berkesan kerana peningkatan data boleh menyebabkan kesesakan.
3. Interpretabiliti
Bergantung pada permohonan, tafsiran mungkin menjadi keutamaan. Sebagai contoh, dalam bidang penjagaan kesihatan atau kewangan, pihak berkepentingan sering perlu mempunyai alasan yang jelas untuk ramalan. Model mudah (seperti regresi logistik) mungkin lebih baik untuk model kotak hitam (seperti rangkaian saraf yang mendalam).
4. Kebolehgunaan medan
Sesetengah model direka untuk jenis atau medan data tertentu. Manfaat ramalan siri masa dari model seperti Arima atau LSTM, sementara tugas pemprosesan bahasa semulajadi sering menggunakan arsitektur berasaskan penukar.
5. Keterbatasan Sumber
Tidak semua organisasi mempunyai kuasa pengkomputeran untuk menjalankan model kompleks. Model yang lebih mudah yang berfungsi dengan baik dalam kekangan sumber dapat membantu mengimbangi prestasi dan kemungkinan.
6. Berlebihan dan penyebaran
Model -model kompleks dengan banyak parameter mudah dipenuhi, menangkap bunyi dan bukannya corak laten. Memilih model yang umum dengan data baru memastikan prestasi sebenar yang lebih baik.
7. Kesesuaian
Keupayaan model untuk menyesuaikan diri dengan perubahan pengagihan data atau keperluan adalah penting dalam persekitaran dinamik. Sebagai contoh, algoritma pembelajaran dalam talian lebih sesuai untuk evolusi data masa nyata.
8. Masa Kos dan Pembangunan
Sesetengah model memerlukan banyak pelarasan hiperparameter, kejuruteraan ciri, atau data pelabelan, yang meningkatkan kos dan masa pembangunan. Memilih model yang betul dapat memudahkan pembangunan dan penempatan.
Bagaimana untuk memilih set model awal?
Pertama, anda perlu memilih satu set model berdasarkan data yang anda miliki dan tugas yang ingin anda lakukan. Ini akan menjimatkan masa anda berbanding dengan menguji setiap model ML.

1. Berdasarkan tugas:
- Klasifikasi: Jika matlamatnya adalah untuk meramalkan kategori (mis., "Spam" vs "non-spam"), maka model klasifikasi harus digunakan.
- Contoh model: regresi logistik, pokok keputusan, hutan rawak, mesin vektor sokongan (SVM), jiran k-terdekat (K-NN), rangkaian saraf.
- Regresi: Jika matlamatnya adalah untuk meramalkan nilai yang berterusan (mis., Harga rumah, harga saham), model regresi harus digunakan.
- Contoh model: regresi linear, pokok keputusan, regresi hutan rawak, regresi vektor sokongan, rangkaian saraf.
- Clustering: Jika matlamatnya adalah untuk mengumpulkan data ke dalam kluster tanpa tag sebelumnya, model clustering digunakan.
- Contoh model: k-mean, dbscan, kluster hierarki, model hibrid Gaussian.
- Pengesanan Anomali: Jika sasaran adalah untuk mengenal pasti peristiwa atau outlier yang jarang berlaku, gunakan algoritma pengesanan anomali.
- Contoh model: Hutan terpencil, SVM kelas tunggal, dan autoencoder.
- Ramalan Siri Masa: Jika matlamatnya adalah untuk meramalkan nilai masa depan berdasarkan data masa.
- Contoh model: Arima, pelicinan eksponen, LSTM, nabi.
2. Berdasarkan data
Jenis
- Data berstruktur (data jadual): Gunakan model seperti pokok keputusan, hutan rawak, xgboost, atau regresi logistik.
- Data tidak berstruktur (teks, imej, audio, dan lain -lain): Gunakan model seperti CNN (untuk imej), RNN atau penukar (untuk teks) atau model pemprosesan audio.
saiz
- Dataset kecil: Model mudah (seperti regresi logistik atau pokok keputusan) cenderung berfungsi dengan baik, kerana model kompleks mungkin terlalu banyak.
- Set data yang besar: Model pembelajaran mendalam (seperti rangkaian saraf, CNN, RNNs) lebih sesuai untuk memproses sejumlah besar data.
kualiti
- Nilai yang hilang: Sesetengah model (seperti hutan rawak) boleh mengendalikan nilai yang hilang, sementara yang lain (seperti SVM) perlu dianggap.
- Kebisingan dan Outliers: Model yang mantap (seperti hutan rawak) atau model dengan regularization (seperti Lasso) adalah pilihan yang baik untuk memproses data bunyi.
Bagaimana untuk memilih model terbaik dari model yang dipilih (teknik pemilihan model)?
Pemilihan model adalah aspek penting dalam pembelajaran mesin, yang membantu mengenal pasti model prestasi terbaik dalam dataset dan masalah tertentu. Kedua -dua teknik utama adalah kaedah resampling dan pengukuran kebarangkalian, masing -masing dengan kaedah penilaian model yang unik.
1. Kaedah resampling
Kaedah resampling melibatkan penyusunan semula dan penggunaan semula subset data untuk menguji prestasi model pada sampel yang tidak kelihatan. Ini membantu menilai keupayaan model untuk menyebarkan data baru. Dua teknik resampling utama adalah:
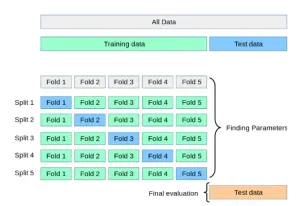
Cross-validation
Cross-validation adalah prosedur resampling sistematik yang digunakan untuk menilai prestasi model. Dalam kaedah ini:
- Set data dibahagikan kepada kumpulan atau lipatan.
- Satu kumpulan digunakan sebagai data ujian, dan selebihnya digunakan untuk latihan.
- Model ini dilatih dan dinilai secara berulang di semua lipatan.
- Kirakan prestasi purata semua lelaran untuk menyediakan metrik ketepatan yang boleh dipercayai.
Cross-validation amat berguna apabila membandingkan model seperti mesin vektor sokongan (SVM) dan regresi logistik untuk menentukan model mana yang lebih sesuai untuk masalah tertentu.
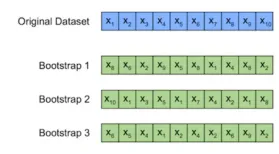
Kaedah Bootstrap
Bootstrap adalah teknik pensampelan di mana data secara rawak dicontohi dengan cara alternatif untuk menganggarkan prestasi model.
Ciri -ciri utama
- Terutamanya digunakan dalam set data yang lebih kecil.
- Saiz data sampel dan ujian sepadan dengan dataset asal.
- Sampel yang menghasilkan skor tertinggi biasanya digunakan.
Proses ini melibatkan secara rawak memilih nilai pemerhatian, merekodkannya, memasukkannya ke dalam dataset, dan mengulangi proses n kali. Sampel boot yang dihasilkan memberikan pandangan tentang keteguhan model.
2. Pengukuran kebarangkalian
Metrik kebarangkalian menilai prestasi model berdasarkan metrik statistik dan kerumitan. Pendekatan ini memberi tumpuan kepada mengimbangi prestasi dan kesederhanaan. Tidak seperti resampling, mereka tidak memerlukan set ujian berasingan kerana prestasi dikira menggunakan data latihan.
Garis Panduan Maklumat Akagi (AIC)
AIC menilai model dengan mengimbangi kebaikan dan kerumitannya. Ia berasal dari teori maklumat dan menghukum bilangan parameter dalam model untuk mengelakkan terlalu banyak.
Formula:

- Kebaikan Fit: Kemungkinan yang lebih tinggi bermakna pemasangan data yang lebih baik.
- Penalti Kerumitan: Istilah 2K menghukum model dengan lebih banyak parameter untuk mengelakkan terlalu banyak.
- Penjelasan: Semakin rendah skor AIC, semakin baik model. Walau bagaimanapun, AICs kadang -kadang boleh menjadi model yang terlalu kompleks kerana mereka mengimbangi kesesuaian dan kerumitan dan kurang ketat daripada piawaian lain.
Kriteria Maklumat Bayesian (BIC)
BIC adalah serupa dengan AIC, tetapi hukuman untuk kerumitan model lebih kuat, menjadikannya lebih konservatif. Ia amat berguna dalam pemilihan model untuk siri masa dan model regresi di mana overfitting adalah masalah.
Formula:

- Kebaikan Fit: Seperti AIC, kemungkinan yang lebih tinggi meningkatkan skor.
- Penalti Kerumitan: Istilah ini menghukum model dengan lebih banyak parameter, dan penalti meningkat apabila saiz sampel N meningkat.
- Penjelasan: BIC cenderung menjadi model yang lebih sederhana daripada AIC kerana ia bermakna penalti yang lebih ketat untuk parameter tambahan.
Panjang Penerangan Minimum (MDL)
MDL adalah prinsip yang memilih model yang memampatkan data yang paling cekap. Ia berakar dalam teori maklumat dan bertujuan untuk meminimumkan jumlah kos menerangkan model dan data.
Formula:

- Kesederhanaan dan kecekapan: MDL cenderung untuk memodelkan baki terbaik antara kesederhanaan (penerangan model yang lebih pendek) dan ketepatan (keupayaan untuk mewakili data).
- Mampatan: Model yang baik memberikan ringkasan ringkas data, dengan berkesan mengurangkan panjang keterangannya.
- Penjelasan: Model dengan MDL terendah lebih disukai.
kesimpulannya
Memilih model pembelajaran mesin terbaik untuk kes penggunaan tertentu memerlukan pendekatan sistematik, mengimbangi keperluan masalah, ciri data, dan batasan praktikal. Dengan memahami sifat tugas, struktur data, dan tradeoffs yang terlibat dalam kerumitan model, ketepatan, dan tafsiran, anda dapat menyempitkan model calon. Teknologi seperti metrik silang dan metrik kebarangkalian (AIC, BIC, MDL) memastikan bahawa calon-calon ini dinilai dengan ketat, membolehkan anda memilih model yang umum dan memenuhi matlamat anda.
Pada akhirnya, proses pemilihan model adalah berulang dan didorong oleh konteks. Adalah penting untuk mempertimbangkan kawasan masalah, kekangan sumber, dan keseimbangan antara prestasi dan kemungkinan. Dengan mengintegrasikan kepakaran domain, eksperimen, dan metrik penilaian dengan teliti, anda boleh memilih model ML yang bukan sahaja memberikan hasil yang terbaik, tetapi juga memenuhi keperluan praktikal dan operasi aplikasi anda.
Sekiranya anda mencari kursus AI/ML dalam talian, meneroka: program AI dan ML Black Belt Plus yang disahkan
Soalan yang sering ditanya
S1. Bagaimana saya tahu model ML yang terbaik?
A: Memilih model ML terbaik bergantung kepada jenis masalah (pengkategorian, regresi, kluster, dan lain -lain), saiz dan kualiti data, dan tradeoffs yang diperlukan antara ketepatan, tafsiran, dan kecekapan pengiraan. Mula -mula menentukan jenis masalah anda (mis., Regresi yang digunakan untuk meramalkan nombor atau klasifikasi yang digunakan untuk mengklasifikasikan data). Untuk set data yang lebih kecil atau apabila tafsiran adalah kritikal, gunakan model mudah seperti regresi linear atau pokok keputusan, dan untuk set data yang lebih besar yang memerlukan ketepatan yang lebih tinggi, menggunakan model yang lebih kompleks seperti hutan rawak atau rangkaian saraf. Sentiasa menilai model menggunakan metrik yang berkaitan dengan matlamat anda (mis., Ketepatan, ketepatan, dan RMSE) dan menguji pelbagai algoritma untuk mencari yang terbaik.
S2.
A: Untuk membandingkan dua model ML, menilai prestasi mereka pada dataset yang sama menggunakan metrik penilaian yang konsisten. Pecahkan data ke dalam latihan dan set ujian (atau gunakan pengesahan silang) untuk memastikan keadilan dan menilai setiap model menggunakan metrik yang berkaitan dengan soalan anda, seperti ketepatan, ketepatan, atau RMSE. Hasilnya dianalisis untuk menentukan model mana yang lebih baik, tetapi juga mempertimbangkan tradeoffs seperti tafsiran, masa latihan, dan skalabilitas. Jika perbezaan prestasi kecil, gunakan ujian statistik untuk mengesahkan kepentingannya. Akhirnya, model yang mengimbangi prestasi dengan keperluan sebenar kes penggunaan dipilih.
Q3.
A: Model ML terbaik untuk meramalkan jualan bergantung kepada dataset dan keperluan anda, tetapi model yang biasa digunakan termasuk algoritma meningkatkan kecerunan seperti regresi linear, pokok keputusan, atau XGBoost. Regresi linear berfungsi dengan baik untuk set data mudah dengan trend linear yang jelas. Untuk hubungan atau interaksi yang lebih kompleks, peningkatan kecerunan atau hutan rawak sering memberikan ketepatan yang lebih tinggi. Jika data melibatkan corak siri masa, model seperti Arima, Sarima, atau rangkaian memori jangka pendek (LSTM) yang panjang lebih sesuai. Pilih model yang mengimbangi prestasi ramalan, tafsiran, dan skalabilitas permintaan ramalan jualan.
Atas ialah kandungan terperinci Bagaimana untuk memilih model ML terbaik untuk usecase anda?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

![Tidak boleh menggunakan chatgpt! Menjelaskan sebab dan penyelesaian yang boleh diuji dengan segera [terbaru 2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) Tidak boleh menggunakan chatgpt! Menjelaskan sebab dan penyelesaian yang boleh diuji dengan segera [terbaru 2025]May 14, 2025 am 05:04 AM
Tidak boleh menggunakan chatgpt! Menjelaskan sebab dan penyelesaian yang boleh diuji dengan segera [terbaru 2025]May 14, 2025 am 05:04 AMChatgpt tidak boleh diakses? Artikel ini menyediakan pelbagai penyelesaian praktikal! Ramai pengguna mungkin menghadapi masalah seperti tidak dapat diakses atau tindak balas yang perlahan apabila menggunakan chatgpt setiap hari. Artikel ini akan membimbing anda untuk menyelesaikan masalah ini langkah demi langkah berdasarkan situasi yang berbeza. Punca ketidakmampuan dan penyelesaian masalah awal Chatgpt Pertama, kita perlu menentukan sama ada masalah itu berada di sisi pelayan Openai, atau masalah rangkaian atau peranti pengguna sendiri. Sila ikuti langkah di bawah untuk menyelesaikan masalah: Langkah 1: Periksa status rasmi Openai Lawati halaman Status Openai (status.openai.com) untuk melihat sama ada perkhidmatan ChATGPT berjalan secara normal. Sekiranya penggera merah atau kuning dipaparkan, ini bermakna terbuka
 Mengira risiko ASI bermula dengan minda manusiaMay 14, 2025 am 05:02 AM
Mengira risiko ASI bermula dengan minda manusiaMay 14, 2025 am 05:02 AMPada 10 Mei 2025, ahli fizik MIT Max Tegmark memberitahu The Guardian bahawa AI Labs harus mencontohi kalkulus ujian triniti Oppenheimer sebelum melepaskan kecerdasan super buatan. "Penilaian saya ialah 'Compton Constant', kebarangkalian perlumbaan
 Penjelasan yang mudah difahami tentang cara menulis dan menyusun lirik dan alat yang disyorkan di chatgptMay 14, 2025 am 05:01 AM
Penjelasan yang mudah difahami tentang cara menulis dan menyusun lirik dan alat yang disyorkan di chatgptMay 14, 2025 am 05:01 AMTeknologi penciptaan muzik AI berubah dengan setiap hari berlalu. Artikel ini akan menggunakan model AI seperti CHATGPT sebagai contoh untuk menerangkan secara terperinci bagaimana menggunakan AI untuk membantu penciptaan muzik, dan menerangkannya dengan kes -kes sebenar. Kami akan memperkenalkan bagaimana untuk membuat muzik melalui Sunoai, AI Jukebox pada muka yang memeluk, dan perpustakaan Python Music21. Dengan teknologi ini, semua orang boleh membuat muzik asli dengan mudah. Walau bagaimanapun, perlu diperhatikan bahawa isu hak cipta kandungan AI yang dihasilkan tidak boleh diabaikan, dan anda mesti berhati-hati apabila menggunakannya. Mari kita meneroka kemungkinan AI yang tidak terhingga dalam bidang muzik bersama -sama! Ejen AI terbaru Terbuka "Openai Deep Research" memperkenalkan: [Chatgpt] Ope
 Apa itu chatgpt-4? Penjelasan menyeluruh tentang apa yang boleh anda lakukan, harga, dan perbezaan dari GPT-3.5!May 14, 2025 am 05:00 AM
Apa itu chatgpt-4? Penjelasan menyeluruh tentang apa yang boleh anda lakukan, harga, dan perbezaan dari GPT-3.5!May 14, 2025 am 05:00 AMKemunculan CHATGPT-4 telah memperluaskan kemungkinan aplikasi AI. Berbanding dengan GPT-3.5, CHATGPT-4 telah meningkat dengan ketara. Ia mempunyai keupayaan pemahaman konteks yang kuat dan juga dapat mengenali dan menghasilkan imej. Ia adalah pembantu AI sejagat. Ia telah menunjukkan potensi yang besar dalam banyak bidang seperti meningkatkan kecekapan perniagaan dan membantu penciptaan. Walau bagaimanapun, pada masa yang sama, kita juga harus memberi perhatian kepada langkah berjaga -jaga dalam penggunaannya. Artikel ini akan menerangkan ciri-ciri CHATGPT-4 secara terperinci dan memperkenalkan kaedah penggunaan yang berkesan untuk senario yang berbeza. Artikel ini mengandungi kemahiran untuk memanfaatkan sepenuhnya teknologi AI terkini, sila rujuknya. Ejen AI Terbuka Terbuka, sila klik pautan di bawah untuk butiran "Penyelidikan Deep Openai"
 Menjelaskan Cara Menggunakan App ChatGPT! Fungsi Sokongan dan Perbualan Suara JepunMay 14, 2025 am 04:59 AM
Menjelaskan Cara Menggunakan App ChatGPT! Fungsi Sokongan dan Perbualan Suara JepunMay 14, 2025 am 04:59 AMApp ChatGPT: Melepaskan kreativiti anda dengan pembantu AI! Panduan pemula Aplikasi CHATGPT adalah pembantu AI yang inovatif yang mengendalikan pelbagai tugas, termasuk menulis, terjemahan, dan menjawab soalan. Ia adalah alat dengan kemungkinan tidak berkesudahan yang berguna untuk aktiviti kreatif dan pengumpulan maklumat. Dalam artikel ini, kami akan menerangkan dengan cara yang mudah difahami untuk pemula, dari cara memasang aplikasi telefon pintar ChATGPT, kepada ciri-ciri yang unik untuk aplikasi seperti fungsi input suara dan plugin, serta mata yang perlu diingat apabila menggunakan aplikasi. Kami juga akan melihat dengan lebih dekat sekatan plugin dan penyegerakan konfigurasi peranti-ke-peranti
 Bagaimana saya menggunakan versi chatgpt Cina? Penjelasan prosedur dan yuran pendaftaranMay 14, 2025 am 04:56 AM
Bagaimana saya menggunakan versi chatgpt Cina? Penjelasan prosedur dan yuran pendaftaranMay 14, 2025 am 04:56 AMChatgpt Versi Cina: Buka kunci pengalaman baru dialog Cina AI Chatgpt popular di seluruh dunia, adakah anda tahu ia juga menawarkan versi Cina? Alat AI yang kuat ini bukan sahaja menyokong perbualan harian, tetapi juga mengendalikan kandungan profesional dan serasi dengan Cina yang mudah dan tradisional. Sama ada pengguna di China atau rakan yang belajar bahasa Cina, anda boleh mendapat manfaat daripadanya. Artikel ini akan memperkenalkan secara terperinci bagaimana menggunakan versi CHATGPT Cina, termasuk tetapan akaun, input perkataan Cina, penggunaan penapis, dan pemilihan pakej yang berbeza, dan menganalisis potensi risiko dan strategi tindak balas. Di samping itu, kami juga akan membandingkan versi CHATGPT Cina dengan alat AI Cina yang lain untuk membantu anda memahami lebih baik kelebihan dan senario aplikasinya. Perisikan AI Terbuka Terbuka
 5 mitos ejen AI anda perlu berhenti mempercayai sekarangMay 14, 2025 am 04:54 AM
5 mitos ejen AI anda perlu berhenti mempercayai sekarangMay 14, 2025 am 04:54 AMIni boleh dianggap sebagai lonjakan seterusnya ke hadapan dalam bidang AI generatif, yang memberi kita chatgpt dan chatbots model bahasa besar yang lain. Daripada hanya menjawab soalan atau menghasilkan maklumat, mereka boleh mengambil tindakan bagi pihak kami, Inter
 Penjelasan yang mudah difahami tentang penyalahgunaan membuat dan menguruskan pelbagai akaun menggunakan chatgptMay 14, 2025 am 04:50 AM
Penjelasan yang mudah difahami tentang penyalahgunaan membuat dan menguruskan pelbagai akaun menggunakan chatgptMay 14, 2025 am 04:50 AMTeknik pengurusan akaun berganda yang cekap menggunakan CHATGPT | Penjelasan menyeluruh tentang cara menggunakan perniagaan dan kehidupan peribadi! ChatGPT digunakan dalam pelbagai situasi, tetapi sesetengah orang mungkin bimbang untuk menguruskan pelbagai akaun. Artikel ini akan menerangkan secara terperinci bagaimana untuk membuat pelbagai akaun untuk chatgpt, apa yang perlu dilakukan apabila menggunakannya, dan bagaimana untuk mengendalikannya dengan selamat dan cekap. Kami juga meliputi perkara penting seperti perbezaan dalam perniagaan dan penggunaan peribadi, dan mematuhi syarat penggunaan OpenAI, dan memberikan panduan untuk membantu anda menggunakan pelbagai akaun. Terbuka


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

