



jina embeddings v2: merevolusikan embedding teks dokumen lama
model penyembuhan teks semasa, seperti BERT, dikekang oleh had pemprosesan 512, menghalang prestasi mereka dengan dokumen yang panjang. Batasan ini sering membawa kepada kehilangan konteks dan pemahaman yang tidak tepat. Jina Embeddings v2 melepasi sekatan ini dengan menyokong urutan sehingga 8192 token, memelihara konteks penting dan meningkatkan ketepatan dan kaitan maklumat yang diproses dalam teks yang luas. Ini merupakan kemajuan besar dalam mengendalikan data teks yang kompleks.
Mata Pembelajaran Utama
- Memahami batasan model tradisional seperti Bert semasa memproses dokumen panjang.
- belajar bagaimana Jina Embeddings v2 mengatasi batasan-batasan ini melalui kapasiti 8192 dan seni bina lanjutan.
- Meneroka ciri-ciri inovatif Jina Embeddings v2, termasuk Alibi, Glu, dan metodologi latihan tiga peringkatnya.
- Menemui aplikasi dunia sebenar dalam penyelidikan undang-undang, pengurusan kandungan, dan ai generatif.
- Mendapatkan pengalaman praktikal dalam mengintegrasikan Jina Embeddings v2 ke dalam projek menggunakan perpustakaan muka yang memeluk.
Jadual Kandungan
cabaran membenamkan dokumen panjang
inovasi seni bina dan metodologi latihan- Penilaian Prestasi
- Aplikasi dunia sebenar
- perbandingan model
- Menggunakan Jina Embeddings v2 dengan muka memeluk
- Kesimpulan
- Soalan Lazim
- Cabaran membenamkan dokumen panjang
memproses dokumen panjang memberikan cabaran penting dalam pemprosesan bahasa semulajadi (NLP). Kaedah tradisional memproses teks dalam segmen, yang membawa kepada pemotongan konteks dan embeddings berpecah -belah yang menyalahgunakan dokumen asal. Ini mengakibatkan:
Meningkatkan tuntutan pengiraanPenggunaan memori yang lebih tinggi
- Mengurangkan prestasi dalam tugas yang memerlukan pemahaman yang komprehensif mengenai teks
- Jina Embeddings v2 secara langsung menangani isu -isu ini dengan meningkatkan had token kepada
- 8192 , menghapuskan keperluan untuk segmentasi yang berlebihan dan mengekalkan integriti semantik dokumen.
inovasi seni bina dan metodologi latihan
Jina Embeddings v2 meningkatkan keupayaan Bert dengan inovasi terkini: , mempelbagaikan perhitungannya. Model ini menggunakan varian encoder di mana semua token menghadiri satu sama lain, tidak seperti varian kausal yang digunakan dalam pemodelan bahasa.
Jina Embeddings v2 mencapai prestasi terkini di pelbagai tanda aras, termasuk penanda aras embedding teks besar-besaran (MTEB) dan dataset lama baru. Keputusan utama termasuk: Aplikasi dunia nyata Perbandingan model Jina Embeddings v2 cemerlang bukan sahaja dalam mengendalikan urutan panjang tetapi juga bersaing dengan model proprietari seperti Openai's Text-Embedding-Ada-002. Sifat sumber terbuka memastikan kebolehcapaian. Menggunakan Jina Embeddings v2 dengan muka memeluk Langkah 1: Pemasangan Langkah 2: Menggunakan Jina Embeddings dengan Transformers output: Mengendalikan urutan panjang:
Langkah 3: Menggunakan Jina Embeddings dengan Sentnal-Transformers
perpustakaan disediakan, bersama -sama dengan arahan untuk menetapkan
Jina Embeddings v2 adalah kemajuan yang signifikan dalam NLP, dengan berkesan menangani batasan memproses dokumen panjang. Keupayaannya meningkatkan aliran kerja yang sedia ada dan membuka kunci kemungkinan baru untuk bekerja dengan teks jangka panjang. (diringkaskan mata utama dari kesimpulan asal)
(Jawapan yang diringkaskan kepada Soalan Lazim)
Nota: Imej dikekalkan dalam format dan lokasi asalnya.
 Alibi Perhatian menggabungkan kecenderungan linear ke dalam setiap skor perhatian sebelum operasi SoftMax. Setiap kepala perhatian menggunakan skalar malar yang unik,
Alibi Perhatian menggabungkan kecenderungan linear ke dalam setiap skor perhatian sebelum operasi SoftMax. Setiap kepala perhatian menggunakan skalar malar yang unik,
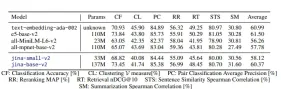
Ketepatan teratas dalam tugas -tugas seperti Klasifikasi Amazon Polarity dan Toksik.
carta ini membandingkan prestasi model embedding merentasi tugas pengambilan dan kluster dengan pelbagai urutan yang berbeza -beza.
!pip install transformers
!pip install -U sentence-transformers
import torch
from transformers import AutoModel
from numpy.linalg import norm
cos_sim = lambda a, b: (a @ b.T) / (norm(a) * norm(b))
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
embeddings = model.encode(['How is the weather today?', 'What is the current weather like today?'])
print(cos_sim(embeddings, embeddings))
embeddings = model.encode(['Very long ... document'], max_length=2048)
sentence_transformers.) max_seq_length
Atas ialah kandungan terperinci Jina Embeddings v2: Mengendalikan Dokumen Panjang Mudah. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Dari geseran ke aliran: bagaimana ai membentuk semula kerja undang -undangMay 09, 2025 am 11:29 AM
Dari geseran ke aliran: bagaimana ai membentuk semula kerja undang -undangMay 09, 2025 am 11:29 AMRevolusi teknologi undang -undang mendapat momentum, menolak profesional undang -undang untuk secara aktif merangkul penyelesaian AI. Rintangan pasif tidak lagi menjadi pilihan yang sesuai untuk mereka yang bertujuan untuk kekal berdaya saing. Mengapa penggunaan teknologi penting? Profesional undang -undang
 Inilah yang difikirkan oleh AI tentang anda dan mengetahui tentang andaMay 09, 2025 am 11:24 AM
Inilah yang difikirkan oleh AI tentang anda dan mengetahui tentang andaMay 09, 2025 am 11:24 AMRamai yang menganggap interaksi dengan AI tidak dikenali, berbeza dengan komunikasi manusia. Walau bagaimanapun, AI secara aktif profil pengguna semasa setiap sembang. Setiap cepat, setiap perkataan, dianalisis dan dikategorikan. Mari kita meneroka aspek kritikal AI Revo ini
 7 langkah untuk membina budaya korporat Ai yang berkembang majuMay 09, 2025 am 11:23 AM
7 langkah untuk membina budaya korporat Ai yang berkembang majuMay 09, 2025 am 11:23 AMStrategi kecerdasan buatan yang berjaya tidak dapat dipisahkan dari sokongan budaya korporat yang kuat. Seperti yang dikatakan Peter Drucker, operasi perniagaan bergantung kepada orang, dan begitu juga kejayaan kecerdasan buatan. Bagi organisasi yang secara aktif merangkul kecerdasan buatan, membina budaya korporat yang menyesuaikan diri dengan AI adalah penting, dan ia juga menentukan kejayaan atau kegagalan strategi AI. West Monroe baru-baru ini mengeluarkan panduan praktikal untuk membina budaya korporat AI yang mesra AI, dan berikut adalah beberapa perkara utama: 1. Jelaskan model kejayaan AI: Pertama sekali, kita mesti mempunyai visi yang jelas tentang bagaimana AI dapat memberi kuasa kepada perniagaan. Budaya operasi AI yang ideal dapat mencapai integrasi semula jadi proses kerja antara manusia dan sistem AI. Ai baik pada tugas -tugas tertentu, sementara manusia pandai kreativiti dan penghakiman
 Netflix New Scroll, Meta AI ' s Game Changers, Neuralink bernilai $ 8.5 bilionMay 09, 2025 am 11:22 AM
Netflix New Scroll, Meta AI ' s Game Changers, Neuralink bernilai $ 8.5 bilionMay 09, 2025 am 11:22 AMMeta menaik taraf permohonan pembantu AI, dan era AI yang boleh dipakai akan datang! Aplikasi ini, yang direka untuk bersaing dengan CHATGPT, menawarkan ciri -ciri AI standard seperti teks, interaksi suara, penjanaan imej dan carian web, tetapi kini telah menambah keupayaan geolokasi untuk kali pertama. Ini bermakna Meta Ai tahu di mana anda berada dan apa yang anda lihat semasa menjawab soalan anda. Ia menggunakan minat, lokasi, profil dan maklumat aktiviti anda untuk memberikan maklumat situasional terkini yang tidak mungkin sebelum ini. Aplikasi ini juga menyokong terjemahan masa nyata, yang benar-benar mengubah pengalaman AI pada gelas Ray-Ban dan meningkatkan kegunaannya. Pengenaan tarif pada filem asing adalah latihan kuasa telanjang ke atas media dan budaya. Sekiranya dilaksanakan, ini akan mempercepatkan ke arah AI dan pengeluaran maya
 Ambil langkah ini hari ini untuk melindungi diri anda daripada jenayah siber AIMay 09, 2025 am 11:19 AM
Ambil langkah ini hari ini untuk melindungi diri anda daripada jenayah siber AIMay 09, 2025 am 11:19 AMKecerdasan buatan merevolusi bidang jenayah siber, yang memaksa kita untuk mempelajari kemahiran pertahanan baru. Penjenayah siber semakin menggunakan teknologi kecerdasan buatan yang kuat seperti pemalsuan yang mendalam dan cyberattacks pintar untuk penipuan dan kemusnahan pada skala yang belum pernah terjadi sebelumnya. Dilaporkan bahawa 87% perniagaan global telah disasarkan untuk jenayah siber AI sepanjang tahun lalu. Jadi, bagaimana kita boleh mengelakkan menjadi mangsa gelombang jenayah pintar ini? Mari kita meneroka cara mengenal pasti risiko dan mengambil langkah -langkah perlindungan di peringkat individu dan organisasi. Bagaimana penjenayah siber menggunakan kecerdasan buatan Sebagai kemajuan teknologi, penjenayah sentiasa mencari cara baru untuk menyerang individu, perniagaan dan kerajaan. Penggunaan kecerdasan buatan yang meluas mungkin menjadi aspek terkini, tetapi bahaya potensinya tidak pernah berlaku sebelum ini. Khususnya, kecerdasan buatan
 Tarian simbiotik: Menavigasi gelung persepsi buatan dan semula jadiMay 09, 2025 am 11:13 AM
Tarian simbiotik: Menavigasi gelung persepsi buatan dan semula jadiMay 09, 2025 am 11:13 AMHubungan rumit antara kecerdasan buatan (AI) dan kecerdasan manusia (NI) paling baik difahami sebagai gelung maklum balas. Manusia mencipta AI, melatihnya pada data yang dihasilkan oleh aktiviti manusia untuk meningkatkan atau meniru keupayaan manusia. AI ini
 Rahsia terbesar AI - pencipta tidak memahaminya, pakar berpecahMay 09, 2025 am 11:09 AM
Rahsia terbesar AI - pencipta tidak memahaminya, pakar berpecahMay 09, 2025 am 11:09 AMKenyataan baru-baru ini Anthropic, yang menonjolkan kekurangan pemahaman yang mengelilingi model AI canggih, telah mencetuskan perdebatan yang hangat di kalangan pakar. Adakah kelegapan ini merupakan krisis teknologi yang tulen, atau hanya halangan sementara di jalan menuju lebih banyak Soph
 Bulbul-V2 oleh Sarvam AI: Model TTS Terbaik India 'May 09, 2025 am 10:52 AM
Bulbul-V2 oleh Sarvam AI: Model TTS Terbaik India 'May 09, 2025 am 10:52 AMIndia adalah negara yang pelbagai dengan permaidani bahasa yang kaya, menjadikan komunikasi lancar di seluruh wilayah menjadi cabaran yang berterusan. Walau bagaimanapun, Sarvam's Bulbul-V2 membantu merapatkan jurang ini dengan teks-ke-ucapannya yang maju (TTS) t


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Dreamweaver CS6
Alat pembangunan web visual

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

