


Tutorial ini meneroka Penyebaran Stabil XL (SDXL) dan DreamBooth, menunjukkan cara memanfaatkan perpustakaan diffusers untuk penjanaan imej dan model penalaan halus. Kami akan menyempurnakan SDXL menggunakan foto peribadi dan menilai hasilnya. Pendatang baru AI digalakkan untuk memulakan dengan kursus asas AI.
Memahami Penyebaran Stabil XL
Kestabilan AI's SDXL 1.0 mewakili lompatan yang ketara dalam generasi teks-ke-imej AI. Membina SDXL 0.9 sahaja, kini merupakan model penciptaan imej yang paling kuat. Ujian luas mengesahkan kualiti imej yang unggul berbanding dengan alternatif sumber terbuka yang lain.

imej dari arxiv.org
Kualiti yang lebih baik ini berpunca daripada ensemble dua model: penjana asas parameter 3.5 bilion dan penapis parameter 6.6 bilion. Pendekatan dua ini mengoptimumkan kualiti imej sambil mengekalkan kecekapan untuk GPU pengguna. SDXL 1.0 memudahkan penjanaan imej, menghasilkan hasil yang rumit daripada arahan ringkas. Penalaan Fine Dataset Custom juga diselaraskan, menawarkan kawalan berbutir ke atas struktur imej, gaya, dan komposisi.
DreamBooth: Generasi imej yang diperibadikan
Dreambooth Google (2022) adalah satu kejayaan dalam AI generatif, terutamanya untuk model teks-ke-imej seperti penyebaran stabil. Seperti yang dikatakan penyelidik Google: "Ia seperti gerai foto tetapi menangkap subjek dengan cara yang membolehkannya disintesis di mana sahaja impian anda membawa anda."
 imej dari DreamBooth
imej dari DreamBooth
DreamBooth menyuntik subjek tersuai ke dalam model, mewujudkan penjana khusus untuk orang, objek, atau adegan tertentu. Latihan hanya memerlukan beberapa imej (3-5). Model terlatih kemudian meletakkan subjek dalam pelbagai tetapan dan pose, hanya terhad oleh imaginasi.
Aplikasi DreamBooth
Generasi Imej Dreambooth yang Disesuaikan Manfaat Pelbagai Bidang:
Industri Kreatif:
- Reka Bentuk Grafik, Pengiklanan, dan Hiburan Manfaat dari Keupayaan Penciptaan Kandungan Visual yang unik.
- Peribadi: mencipta senario sukar atau mustahil untuk ditiru dalam realiti atau tetapan fiksyen semata -mata.
- Pendidikan & Penyelidikan: Menjana Kandungan Pendidikan Peribadi dan Penyelidikan AIDS yang memerlukan perwakilan visual.
- Mengakses Penyebaran Stabil XL
SDXL boleh diakses melalui Demo Ruang Pakaian Mendging (menghasilkan empat imej dari prompt) atau perpustakaan python untuk generasi imej custom.
Persediaan dan penjanaan imej dengan diffusers
Pastikan GPU yang dibolehkan CUDA tersedia:
!nvidia-smi

: diffusers
%pip install --upgrade diffusers[torch] -qMuatkan model (menggunakan FP16 untuk kecekapan memori GPU):
from diffusers import DiffusionPipeline, AutoencoderKL
import torch
vae = AutoencoderKL.from_pretrained("madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16)
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", vae=vae, torch_dtype=torch.float16, variant="fp16", use_safetensors=True)
pipe.to("cuda"); Menjana imej:
prompt = "A man in a spacesuit is running a marathon in the jungle." image = pipe(prompt=prompt, num_inference_steps=25, num_images_per_prompt=4)memaparkan imej menggunakan fungsi penolong (disediakan dalam asal):
# ... (image_grid function from original code) ... image_grid(image.images, 2, 2)

Untuk kualiti yang dipertingkatkan, gunakan penapis SDXL:
# ... (refiner loading and processing code from original) ...
 sdxl penalaan halus dengan autotrain maju
sdxl penalaan halus dengan autotrain maju
Autotrain Advanced memudahkan SDXL Fine-penalaan. Pasangnya menggunakan:
%pip install -U autotrain-advancedDreamBooth Fine-penalaan (ringkas)
Kesimpulan
Tutorial ini memberikan gambaran menyeluruh mengenai SDXL dan DreamBooth, mempamerkan keupayaan mereka dan kemudahan penggunaan dengan perpustakaan
dan autotrain maju. Proses penalaan halus menunjukkan kuasa penjanaan imej yang diperibadikan, menonjolkan kedua-dua kejayaan dan bidang untuk penerokaan lanjut (seperti interaksi penapis dengan model yang disempurnakan). Tutorial ini disimpulkan dengan cadangan untuk pembelajaran selanjutnya dalam bidang AI.
Atas ialah kandungan terperinci Penyebaran stabil yang stabil XL dengan Dreambooth dan lora. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Kursor AI: Mengapa anda harus mencubanya sekali? - Analytics VidhyaApr 14, 2025 am 10:22 AM
Kursor AI: Mengapa anda harus mencubanya sekali? - Analytics VidhyaApr 14, 2025 am 10:22 AMPengenalan Selepas tweet virus Andrej Karpathy, "Bahasa Inggeris telah menjadi bahasa pengaturcaraan baru," Berikut adalah satu lagi tweet trend pada X berkata, "Masa depan menjadi seperti tab tab tab." Anda mungkin tertanya -tanya
 Meneroka Civitai: Model, Lora, dan Kemungkinan KreatifApr 14, 2025 am 10:21 AM
Meneroka Civitai: Model, Lora, dan Kemungkinan KreatifApr 14, 2025 am 10:21 AMCIVITAI: Melepaskan visi kreatif anda dengan generasi imej berkuasa AI Bayangkan sebuah platform di mana idea-idea artistik anda menjadi kenyataan dengan hanya beberapa klik-ruang di mana anda boleh menyempurnakan model AI canggih untuk membuat imej yang menakjubkan.
 Menguasai segmen imej dan video dengan Sam 2Apr 14, 2025 am 10:16 AM
Menguasai segmen imej dan video dengan Sam 2Apr 14, 2025 am 10:16 AMPanduan ini akan membimbing anda melalui segmen apa -apa Model 2, bagaimana ia berfungsi, dan bagaimana anda akan menggunakannya ke objek bahagian dalam gambar dan video. Ia menawarkan pelaksanaan dan kebolehsuaian yang canggih dalam pemecahan OB
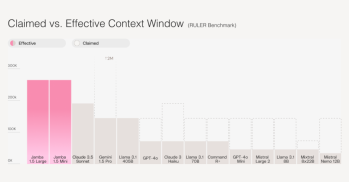 AV Bytes: Model baru, kemajuan penyelidikan, dan perdebatan pengawalseliaanApr 14, 2025 am 10:15 AM
AV Bytes: Model baru, kemajuan penyelidikan, dan perdebatan pengawalseliaanApr 14, 2025 am 10:15 AMLandskap AI minggu ini menyaksikan kemajuan yang ketara, dengan syarikat terkemuka melancarkan model dan alat canggih. Sorotan utama termasuk pelepasan AI21 Labs Jamba 1.5, peningkatan Anthropicai kepada Claude 3, dan Pengenalan Bindu Reddy
 Bagaimana Amazon Alexa berfungsi menggunakan NLPApr 14, 2025 am 10:06 AM
Bagaimana Amazon Alexa berfungsi menggunakan NLPApr 14, 2025 am 10:06 AMPengenalan Duduk di hadapan desktop, jauh dari anda, adalah pembantu peribadi anda sendiri, dia tahu nada suara anda, jawapan kepada soalan anda dan bahkan satu langkah di hadapan anda. Ini adalah keindahan Amazon Alexa, SM
 10 sumber percuma untuk belajar LLMApr 14, 2025 am 10:04 AM
10 sumber percuma untuk belajar LLMApr 14, 2025 am 10:04 AMBuka kunci kekuatan model bahasa besar (LLMS): 10 sumber percuma Memulakan perjalanan ke dunia model bahasa besar (LLMS), daya penggerak di belakang chatbots pintar dan analisis data canggih. Panduan komprehensif ini memperkenalkan sepuluh fr
 Adakah anda membuat kesilapan ini dalam pemodelan klasifikasi?Apr 14, 2025 am 10:02 AM
Adakah anda membuat kesilapan ini dalam pemodelan klasifikasi?Apr 14, 2025 am 10:02 AMPengenalan Menilai model pembelajaran mesin bukan sekadar langkah terakhir -ia adalah kunci kejayaan. Bayangkan membina model canggih yang mempesonakan dengan ketepatan yang tinggi, hanya untuk mendapati ia runtuh di bawah sebenar
 Trocr dan Zhen lateks OcrApr 14, 2025 am 09:59 AM
Trocr dan Zhen lateks OcrApr 14, 2025 am 09:59 AMMeneroka Kekuatan Model-ke-Teks Model: Trocr dan Zhen Latex Ocr Dunia AI bersemangat dengan model bahasa dan aplikasi mereka dalam bantuan maya dan penciptaan kandungan. Walau bagaimanapun, bidang penukaran imej-ke-teks, dikuasakan oleh optik


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

