



Keupayaan penalaran maju DeepSeek-R1 telah menjadikannya pemimpin baru dalam bidang LLM generasi. Ia telah menyebabkan kacau dalam industri AI, dengan laporan kerugian Nvidia $ 600 bilion selepas pelancaran. Tetapi apa yang menjadikan DeepSeek-R1 begitu terkenal semalaman? Dalam artikel ini, kami akan meneroka mengapa DeepSeek-R1 mendapat begitu banyak perhatian, menyelidiki keupayaannya yang terobosan, dan menganalisis bagaimana kuasa penalarannya membentuk semula aplikasi dunia nyata. Tinggal ketika kami memecahkan prestasi model melalui analisis terperinci dan berstruktur.
Objektif Pembelajaran
- Memahami keupayaan pemikiran maju DeepSeek-R1 dan kesannya terhadap landskap LLM.
- Ketahui bagaimana pengoptimuman dasar relatif kumpulan (GRPO) meningkatkan pembelajaran tetulang tanpa model pengkritik.
- meneroka perbezaan antara DeepSeek-R1-Zero dan DeepSeek-R1 dari segi latihan dan prestasi.
- Menganalisis metrik penilaian dan tanda aras yang mempamerkan keunggulan DeepSeek-R1 dalam tugas penalaran.
- Ketahui bagaimana DeepSeek-R1 mengoptimumkan tugas STEM dan pengekodan dengan model AI yang berskala tinggi.
Jadual Kandungan Apakah DeepSeek-R1? DeepSeek-R1 Penilaian DeepSeek-R1
Menilai keupayaan penalaran DeepSeek-R1-7b
- Apa itu DeepSeek-R1?
- Dalam kata-kata mudah, DeepSeek-R1 adalah siri model bahasa canggih yang dibangunkan oleh DeepSeek, yang ditubuhkan pada tahun 2023 oleh Liang Wenfeng. Ia mencapai keupayaan penalaran maju dalam LLM melalui pembelajaran tetulang (RL). Terdapat dua variasi:
- DeepSeek-R1-Zero
- Ia dilatih semata-mata melalui RL pada model asas tanpa diselia dengan baik (SFT), dan ia secara autonomi membangunkan tingkah laku penalaran maju seperti pengesahan diri dan refleksi pelbagai langkah, mencapai ketepatan 71% pada penanda aras AIME 2024
- DeepSeek-R1
- Ia dipertingkatkan dengan data permulaan dan latihan multi-stage (RL SFT), ia menangani isu-isu kebolehbacaan dan mengatasi OpenAI mengenai tugas-tugas seperti Math-500 (97.3% ketepatan) dan cabaran pengekodan (Rating CodeForcese 2029) DeepSeek menggunakan pengoptimuman dasar relatif kumpulan (GRPO), teknik RL yang tidak menggunakan model pengkritik dan menjimatkan kos latihan RL. GRPO mengoptimumkan dasar dengan mengumpulkan output dan menormalkan ganjaran, menghapuskan keperluan model pengkritik.
-
Projek ini juga menyuling corak penalarannya ke dalam model yang lebih kecil (1.5B-70B), membolehkan penggunaan yang cekap. Menurut penanda aras itu model 7B melepasi GPT-4O.
Kertas DeepSeek-R1 di sini.
Carta Perbandingan
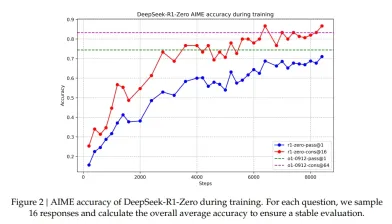
Model GPQA LiveCode Diamond Bench CodeForces pass@1 cons@64 CodeForces pass@1 Rating OpenAI-01-mini 63.6 80.0 90.0 60.0 53.8 1820 OpenAI-01-0912 74.4 83.3 94.8 77.3 63.4 1843 DeepSeek-R1-Zero 71.0 86.7 95.9 73.3 50.0 1444 Plot ketepatan DeepSeek-R1-Zero pada dataset AIME
DeepSeek Open Open-soorced Models, Latihan Pipelines, dan Benchmarks bertujuan untuk mendemokrasikan penyelidikan penalaran yang didorong oleh RL, yang menawarkan penyelesaian berskala untuk tugas STEM, pengekodan, dan intensif pengetahuan. DeepSeek-R1 mengarahkan jalan ke era baru SLMS dan LLM yang tinggi, tinggi.
Apakah pengoptimuman dasar relatif kumpulan (GRPO)?
Sebelum masuk ke GRPO canggih, mari kita melayari beberapa asas pembelajaran tetulang (RL).
Pembelajaran tetulang adalah interaksi antara ejen dan persekitaran. Semasa latihan, ejen mengambil tindakan supaya ia memaksimumkan ganjaran kumulatif. Fikirkan tentang bot yang bermain catur atau robot di lantai kilang yang cuba melakukan tugas dengan barang -barang sebenar.
Ejen belajar dengan melakukan. Ia mendapat ganjaran apabila ia melakukan perkara yang betul; Jika tidak, ia menjadi negatif. Dengan melakukan ujian berulang -ulang ini, ia akan dalam perjalanan untuk mencari strategi yang optimum untuk menyesuaikan diri dengan persekitaran yang tidak diketahui.
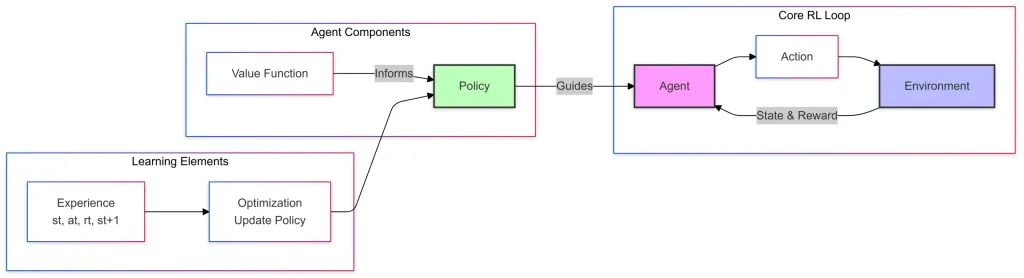
Berikut adalah gambarajah mudah pembelajaran tetulang, ia mempunyai 3 komponen:
teras RL Loop- ejen yang mengambil tindakan berdasarkan dasar yang dipelajari.
- Tindakan adalah keputusan yang dibuat oleh ejen pada keadaan tertentu.
- Persekitaran adalah sistem luaran (permainan, lantai bengkel, drone terbang, dll) di mana ejen beroperasi dan belajar dengan berinteraksi.
- Persekitaran memberikan maklum balas kepada ejen dalam bentuk negeri baru dan ganjaran.
Komponen ejen
Fungsi nilai menganggarkan seberapa baik keadaan atau tindakan tertentu dari segi ganjaran jangka panjang- Dasar adalah strategi yang mentakrifkan pemilihan tindakan ejen.
- Fungsi nilai memberitahu dasar dengan membantu meningkatkan keputusan
- Panduan Dasar (Hubungan Panduan) Ejen dalam memilih tindakan dalam gelung RL
- Elemen Pembelajaran
Pengalaman, di sini ejen mengumpul urus niaga semasa berinteraksi dengan alam sekitar.- Pengoptimuman atau kemas kini dasar menggunakan pengalaman untuk memperbaiki dasar dan membuat keputusan yang penting.
- Proses Latihan dan Pengoptimuman dalam DeepSeek-R1-Zero
Pengalaman yang dikumpulkan digunakan untuk mengemas kini dasar melalui pengoptimuman. Fungsi nilai memberikan pandangan untuk memperbaiki dasar. Dasar ini membimbing ejen, yang berinteraksi dengan alam sekitar untuk mengumpul pengalaman baru dan kitaran berlangsung sehingga ejen mempelajari strategi optimum atau bertambah baik untuk menyesuaikan diri dengan alam sekitar.
Dalam latihan DeepSeek-R1-Zero, mereka menggunakan pengoptimuman dasar relatif kumpulan atau GRPO, ia menghapuskan model pengkritik dan menurunkan kos latihan.
Bagi pemahaman saya tentang kertas penyelidikan DeepSeek-R1, inilah proses latihan skematik model DeepSeek-R1-Zero dan DeepSeek-R1.
DeepSeek-R1-Zero dan R1 Rajah Latihan Tentatif
bagaimana GRPO berfungsi?
Untuk setiap soalan Q, sampel GRPO sekumpulan output {O1, O2, O2 ..} dari dasar lama dan mengoptimumkan model dasar dengan memaksimumkan objektif di bawah: di sini Epsilon dan beta adalah parameter hyper, dan A_I adalah kelebihan yang dikira menggunakan sekumpulan ganjaran {R1, R2, R3 ... Rg} sepadan dengan output dalam setiap kumpulan. pengiraan kelebihan
dalam pengiraan kelebihan, menormalkan ganjaran dalam output kumpulan,
r_iadalah ganjaran untuk output i dan r_group adalah ganjaran semua output dalam kumpulan.
untuk memaksimumkan kemas kini dasar yang dipotong dengan penalti KL,
Kullback-Leibler Divergence
perbezaan KL yang juga dikenali sebagai entropi relatif adalah fungsi jarak statistik, yang mengukur perbezaan antara taburan kebarangkalian model (q) dan taburan kebarangkalian benar (p).
untuk lebih banyak KL-Divergence
Persamaan di bawah adalah bentuk matematik KL-Divergence:
entropi relatif atau jarak KL sentiasa nombor sebenar yang tidak negatif. Ia mempunyai nilai terendah 0 jika dan hanya jika Q dan P adalah sama. Ini bermakna kedua -dua pengagihan kebarangkalian model (q) dan taburan kebarangkalian sebenar (p) bertindih atau sistem yang sempurna. Contoh KL Divergence Berikut adalah contoh mudah untuk mempamerkan perbezaan KL,
Kami akan menggunakan fungsi entropi dari pakej statistik Scipy, ia akan mengira entropi relatif antara dua pengagihan.
p dan q kami sebagai pengedaran Gaussian dan beralih Gaussian masing-masing.
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
# Define two probability distributions P and Q x = np.linspace(-3, 3, 100) P = np.exp(-(x**2)) # Gaussian-like distribution Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian # Normalize to ensure they sum to 1 P /= P.sum() Q /= Q.sum() # Compute KL divergence kl_div = entropy(P, Q)
bahagian kuning adalah perbezaan KL antara p dan Q.plt.style.use("ggplot") plt.figure(figsize=(12, 8)) plt.plot(x, P, label="P (Original)", line, color="blue") plt.plot(x, Q, label="Q (Shifted)", line, color="red") plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference") plt.title(f"KL Divergence: {kl_div:.4f}") plt.xlabel("x") plt.ylabel("Probability Density") plt.legend() plt.show()Dalam persamaan GRPO, sampel GRPO sekumpulan output untuk setiap pertanyaan dan mengira kelebihan berbanding dengan min dan sisihan piawai kumpulan. Ini mengelakkan latihan model pengkritik yang berasingan. Objektifnya termasuk nisbah yang dipotong dan penalti KL untuk tetap dekat dengan dasar rujukan.
Bahagian nisbah adalah nisbah kebarangkalian polisi baru dan lama (nisbah) terikat antara 1-epsilon dan 1 epsilon.
proses perbualan antara pengguna dan pembantuPengguna bertanya soalan, dan model atau pembantu menyelesaikannya dengan memikirkan terlebih dahulu mengenai proses penalaran dan kemudian bertindak balas kepada pengguna.
Penalaran dan jawapan disertakan dalam rajah di bawah.
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
Proses evolusi diri DeepSeek-R1-Zero menunjukkan bagaimana pembelajaran tetulang dapat meningkatkan keupayaan penalaran model secara autonomi. Carta menunjukkan bagaimana keupayaan penalaran model untuk mengendalikan tugas penalaran yang kompleks berkembang. Meningkatkan keupayaan dan keupayaan umum dalam DeepSeek-R1 DeepSeek-R1, menjawab dua soalan penting yang timbul selepas menjanjikan hasil model sifar.
bolehkah prestasi penalaran diperbaiki lagi?- Bagaimana kita boleh melatih model mesra pengguna yang bukan sahaja menghasilkan rantaian pemikiran yang jelas dan koheren (COT) tetapi juga menunjukkan keupayaan umum yang kuat?
- DeepSeek-R1 menggunakan data permulaan sejuk dalam format di mana pemaju mengumpul beribu-ribu data permulaan sejuk untuk menyempurnakan deepseek-v3-base sebagai titik permulaan RL.
Data ini mempunyai dua kelebihan penting berbanding dengan DeepSeek-R1-Zero.
bacaan
: Batasan utama model sifar ialah kandungannya tidak sesuai untuk dibaca. Respons bercampur dengan banyak bahasa, dan tidak diformat dengan baik untuk menyerlahkan jawapan untuk pengguna.- Potensi : Pakar Pakar Merancang corak data permulaan sejuk untuk membantu prestasi yang lebih baik terhadap DeepSeek-R1-Zero.
- Penilaian DeepSeek-R1 Menurut kertas DeepSeek-R1, mereka (pemaju) menetapkan panjang penjanaan maksimum kepada token 32768 untuk model. Mereka mendapati model penalaran output yang panjang menghasilkan kadar pengulangan yang lebih tinggi dengan penyahkodan tamak dan kebolehubahan yang ketara. Oleh itu, mereka menggunakan penilaian lulus@k, ia menggunakan suhu pensampelan 0.6 dan nilai TOP-P sebanyak 0.95 untuk menghasilkan tindak balas nombor K untuk setiap soalan.
lulus@1 kemudian dikira sebagai:
di sini, P_I menandakan ketepatan tindak balas I-th, menurut kertas penyelidikan kaedah ini memastikan anggaran prestasi yang lebih dipercayai.
kita dapat melihat bahawa tanda aras pengetahuan berorientasikan pendidikan seperti MMLU, MMLU-PRO, GPQA Diamond, dan DeepSeek-R1 melakukan lebih baik berbanding dengan DeepSeek-V3. Ia telah meningkatkan ketepatan dalam soalan yang berkaitan dengan STEM. DeepSeek-R1 juga menyampaikan hasil yang hebat pada IF-Eval, data penanda aras yang direka untuk menilai keupayaan model untuk mengikuti arahan format.
matematik yang cukup dan pemahaman teoritis telah dilakukan, yang saya ingin meningkatkan pengetahuan keseluruhan anda tentang pembelajaran tetulang dan aplikasi canggihnya pada pembangunan model DeepSeek-R1. Sekarang kita akan mendapatkan tangan kita di DeepSeek-R1 menggunakan Ollama dan merasai llm yang baru dicetak.
Menilai keupayaan penalaran DeepSeek-R1-7b
Penilaian DeepSeek-R1-7b memberi tumpuan kepada keupayaan penalarannya yang dipertingkatkan, terutamanya prestasinya dalam senario penyelesaian masalah yang kompleks. Dengan menganalisis tanda aras utama, penilaian ini memberikan gambaran tentang bagaimana model mengendalikan tugas -tugas penalaran yang rumit berbanding dengan pendahulunya.
apa yang ingin kita capai
- Menilai keupayaan penalaran DeepSeek-R1 di seluruh domain kognitif yang berbeza
- Kenal pasti kekuatan dan batasan dalam tugas penalaran tertentu
- Memahami potensi aplikasi dunia sebenar
Persediaan Alam Sekitar
- Pasang Ollama FromHere
- Setelah memasangnya ke sistem anda buka terminal anda dan taipkan arahan di bawah, ia akan memuat turun dan memulakan model DeepSeek-R1 7B.
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
sekarang saya mengemukakan soalan ketidaksamaan linear dari ncert
q.solve 4x 3 & lt; 6x 7
dan responsnya adalah:
yang tepat mengikut buku. AMAZING !! kini akan menyediakan persekitaran ujian menggunakan llamaindex yang akan menjadi cara yang lebih menonjol untuk melakukan ini.
Persekitaran ujian persediaan
sekarang kita memasang pakej yang diperlukan# Define two probability distributions P and Q x = np.linspace(-3, 3, 100) P = np.exp(-(x**2)) # Gaussian-like distribution Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian # Normalize to ensure they sum to 1 P /= P.sum() Q /= Q.sum() # Compute KL divergence kl_div = entropy(P, Q)
Pasang pakej
kini buka vscode dan buat nama notebook Jupyter prompt_analysis.ipynb akar folder projek.plt.style.use("ggplot") plt.figure(figsize=(12, 8)) plt.plot(x, P, label="P (Original)", line, color="blue") plt.plot(x, Q, label="Q (Shifted)", line, color="red") plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference") plt.title(f"KL Divergence: {kl_div:.4f}") plt.xlabel("x") plt.ylabel("Probability Density") plt.legend() plt.show()perpustakaan import
anda mesti terus menjalankan ollama deepseek-r1: 7b di terminal anda.<think> reasoning process</think> <answer> answer here </answer> USER: Prompt Assistant: Answer
Sekarang, mulakan dengan masalah matematik
Output:output akan menjadi sangat panjang sehingga output dalam blog ini akan dikurangkan, untuk output penuh anda mesti melihat repositori kod blog di sini.
senario penalaran dan penyelesaian masalah lanjutan
Bahagian ini meneroka tugas penyelesaian masalah yang kompleks yang memerlukan pemahaman yang mendalam tentang pelbagai teknik penalaran, dari pengiraan matematik ke dilema etika. Dengan melibatkan diri dengan senario ini, anda akan meningkatkan keupayaan anda untuk berfikir secara kritikal, menganalisis data, dan membuat kesimpulan logik merentasi pelbagai konteks.
Masalah matematik: Pengiraan kad diskaun dan kesetiaan
Sebuah kedai menawarkan diskaun 20% pada semua item. Selepas memohon diskaun, terdapat tambahan 10% untuk ahli kad kesetiaan. Jika item pada asalnya berharga $ 150, apakah harga akhir untuk ahli kad kesetiaan? Tunjukkan pengiraan langkah demi langkah anda dan terangkan penalaran anda.
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
output:
Aspek utama prompt ini ialah: - Keupayaan pengiraan berurutan
- pemahaman konsep peratusan
- Penalaran langkah demi langkah
- kejelasan penjelasan.
Pertimbangkan pernyataan ini: Semua burung boleh flypenguins adalah burung -burung yang tidak dapat terbang dengan sebarang percanggahan dalam pernyataan ini. Sekiranya terdapat percanggahan, terangkan bagaimana menyelesaikannya menggunakan penalaran logik.# Define two probability distributions P and Q x = np.linspace(-3, 3, 100) P = np.exp(-(x**2)) # Gaussian-like distribution Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian # Normalize to ensure they sum to 1 P /= P.sum() Q /= Q.sum() # Compute KL divergence kl_div = entropy(P, Q)
output:
Ini akan menunjukkan konsistensi logik, mencadangkan penyelesaian logik, memahami hubungan kelas, dan penalaran silogistik. Analisis rantai kausal: kesan ekosistem penyakit pada serigala
Dalam ekosistem hutan, penyakit membunuh 80% daripada populasi serigala. Huraikan potensi rantaian kesan yang mungkin ada pada ekosistem dalam tempoh 5 tahun akan datang. Sertakan sekurang -kurangnya tiga tahap sebab dan akibat, dan terangkan alasan anda untuk setiap langkah.
plt.style.use("ggplot") plt.figure(figsize=(12, 8)) plt.plot(x, P, label="P (Original)", line, color="blue") plt.plot(x, Q, label="Q (Shifted)", line, color="red") plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference") plt.title(f"KL Divergence: {kl_div:.4f}") plt.xlabel("x") plt.ylabel("Probability Density") plt.legend() plt.show()output:Model cepat ini menunjukkan pemahaman sistem kompleks, menjejaki pelbagai rantai kasual, menganggap kesan tidak langsung, dan menggunakan pengetahuan domain.
Pengiktirafan corak: Mengenalpasti dan menerangkan urutan nombor
Pertimbangkan urutan ini: 2, 6, 12, 20, 30, __What nombor seterusnya?Jelaskan corak
- Buat formula untuk istilah n.
- Sahkan formula anda berfungsi untuk semua nombor yang diberikan
<think> reasoning process</think> <answer> answer here </answer> USER: Prompt Assistant: Answer
Model cemerlang dalam mengenal pasti corak berangka, menghasilkan formula matematik, menjelaskan proses penalaran, dan mengesahkan penyelesaian.Masalah kebarangkalian: Mengira kebarangkalian dengan kelereng
Beg mengandungi 3 guli merah, 4 guli biru, dan 5 guli hijau. Sekiranya anda melukis dua guli tanpa pengganti:
- Apakah kebarangkalian menggambar dua kelereng biru?
- Apakah kebarangkalian melukis kelereng warna yang berbeza?
Tunjukkan semua pengiraan dan terangkan pendekatan anda.
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
output:
Model ini dapat mengira kebarangkalian, mengendalikan masalah bersyarat, dan menerangkan penalaran probabilistik.
Debugging: Kesalahan logik dalam kod dan penyelesaian mereka
Kod ini mempunyai kesilapan logik yang menghalangnya daripada berjalan dengan betul.# Define two probability distributions P and Q x = np.linspace(-3, 3, 100) P = np.exp(-(x**2)) # Gaussian-like distribution Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian # Normalize to ensure they sum to 1 P /= P.sum() Q /= Q.sum() # Compute KL divergence kl_div = entropy(P, Q)
- Kenal pasti semua masalah yang berpotensi
- Jelaskan mengapa masing -masing adalah masalah
- menyediakan versi yang diperbetulkan
- Jelaskan mengapa penyelesaian anda lebih baik
plt.style.use("ggplot") plt.figure(figsize=(12, 8)) plt.plot(x, P, label="P (Original)", line, color="blue") plt.plot(x, Q, label="Q (Shifted)", line, color="red") plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference") plt.title(f"KL Divergence: {kl_div:.4f}") plt.xlabel("x") plt.ylabel("Probability Density") plt.legend() plt.show()output:
DeepSeek-R1 mendapati kes kelebihan, memahami keadaan ralat, menggunakan pembetulan, dan menerangkan penyelesaian teknikal.
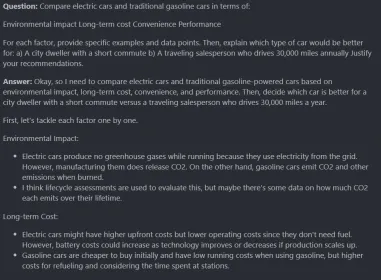
Analisis Perbandingan: Elektrik vs Gasoline Cars
Bandingkan kereta elektrik dan kereta petrol tradisional dari segi:Kesan Alam Sekitar
- kos jangka panjang
- kemudahan
- Prestasi
- Untuk setiap faktor, berikan contoh khusus dan titik data. Kemudian, terangkan jenis kereta mana yang lebih baik untuk:
penghuni bandar dengan perjalanan singkat
- jurujual perjalanan yang memandu sejauh 30,000 batu setiap tahun
- membenarkan cadangan anda.
output:<think> reasoning process</think> <answer> answer here </answer> USER: Prompt Assistant: Answer
Ini adalah tindak balas yang besar, saya suka proses penalaran. Ia menganalisis pelbagai faktor, menganggap konteks, membuat cadangan yang baik, dan mengimbangi keutamaan bersaing. dilema etika: membuat keputusan dalam kereta memandu sendiri Kereta memandu sendiri mesti membuat keputusan yang berpecah-belah:
swerve kiri: tekan dua pejalan kaki
Swerve right: memukul dinding, serius mencederakan penumpang- Swerve right: memukul dinding, serius mencederakan penumpang
- Apa yang perlu dilakukan oleh kereta? Berikan alasan anda, memandangkan:
Asumsi dibuat- hierarki keutamaan
- Implikasi jangka panjang
- output:
$ollama run deepseek-r1:7b
Jenis masalah ini paling bermasalah untuk model AI generatif. Ia menguji penalaran etika, pelbagai perspektif, dilema moral, dan penghakiman nilai. Secara keseluruhan, ia adalah satu baik. Saya fikir lebih banyak penalaan domain khusus domain akan menghasilkan tindak balas yang lebih mendalam.
Analisis Statistik: Menilai Tuntutan Kajian mengenai Penggunaan Kopi
Kajian mendakwa bahawa peminum kopi hidup lebih lama daripada peminum bukan kopi. Kajian ini mengamati 1000 orang berumur 40-50 selama 5 tahun.
Kenal pasti:
- Pembolehubah berpotensi membingungkan
- Sampling Biases
- Penjelasan alternatif
- Apakah data tambahan akan menguatkan atau melemahkan kesimpulan?
import numpy as np import matplotlib.pyplot as plt from scipy.stats import entropy
output:
Ia memahami konsep statistik dengan cukup baik, mengenal pasti batasan penyelidikan, dan pemikiran kritikal terhadap data, dan mencadangkan penambahbaikan metodologi.
Analisis siri masa# Define two probability distributions P and Q x = np.linspace(-3, 3, 100) P = np.exp(-(x**2)) # Gaussian-like distribution Q = np.exp(-((x - 1) ** 2)) # Shifted Gaussian # Normalize to ensure they sum to 1 P /= P.sum() Q /= Q.sum() # Compute KL divergence kl_div = entropy(P, Q)
output:
DeepSeek suka masalah matematik, mengendalikan kerosakan eksponen, menyediakan model matematik yang baik, dan menyediakan pengiraan. Tugas penjadualan
plt.style.use("ggplot") plt.figure(figsize=(12, 8)) plt.plot(x, P, label="P (Original)", line, color="blue") plt.plot(x, Q, label="Q (Shifted)", line, color="red") plt.fill_between(x, P, Q, color="yellow", alpha=0.3, label="Difference") plt.title(f"KL Divergence: {kl_div:.4f}") plt.xlabel("x") plt.ylabel("Probability Density") plt.legend() plt.show()output:Ia boleh mengendalikan pelbagai kekangan, menghasilkan jadual yang dioptimumkan, dan menyediakan proses penyelesaian masalah.
Analisis Cross-Domain
output:<think> reasoning process</think> <answer> answer here </answer> USER: Prompt Assistant: Answer
Ia melakukan tugas dengan baik untuk membandingkan pelbagai jenis domain bersama -sama yang sangat mengagumkan. Jenis penalaran ini membantu pelbagai jenis domain bersama -sama supaya masalah satu domain dapat diselesaikan oleh penyelesaian dari domain lain. Ia membantu penyelidikan mengenai pemahaman silang domain. Walaupun, terdapat banyak contoh yang mendorong anda boleh bereksperimen dengan model pada sistem tempatan anda tanpa membelanjakan sebarang sen. Saya akan menggunakan DeepSeek-R1 untuk lebih banyak penyelidikan, dan belajar tentang bidang yang berbeza. Yang anda perlukan adalah komputer riba, masa anda, dan tempat yang bagus. semua kod yang digunakan dalam artikel ini di sini.
Kesimpulan
DeepSeek-R1 menunjukkan keupayaan yang menjanjikan dalam pelbagai tugas penalaran, mempamerkan keupayaan penalaran lanjutannya dalam analisis logik berstruktur, penyelesaian masalah langkah demi langkah, pemahaman multi-konteks, dan pengumpulan pengetahuan dari subjek yang berbeza. Walau bagaimanapun, terdapat bidang penambahbaikan, seperti penalaran temporal yang kompleks, mengendalikan kekaburan yang mendalam, dan menjana penyelesaian kreatif. Paling penting, ia menunjukkan bagaimana model seperti DeepSeek-R1 boleh dibangunkan tanpa beban kos latihan besar GPU.
Model sumber terbuka mendorong AI ke arah alam yang lebih demokratik. Penyelidikan baru tidak lama lagi akan dijalankan pada kaedah latihan ini, yang membawa kepada model AI yang lebih kuat dan berkuasa dengan keupayaan penalaran yang lebih baik. Walaupun AGI masih berada di masa depan yang jauh, kemajuan DeepSeek-R1 menunjukkan masa depan di mana AGI akan muncul dengan tangan dengan orang ramai. DeepSeek-R1 sudah pasti satu langkah utama ke hadapan dalam merealisasikan sistem penalaran AI yang lebih maju.
Takeaways Key
- Keupayaan penalaran maju DeepSeek R1 bersinar melalui keupayaannya untuk melakukan analisis logik berstruktur, menyelesaikan masalah langkah demi langkah, dan memahami konteks kompleks di seluruh domain yang berbeza.
- Model ini menolak sempadan penalaran dengan mengumpulkan pengetahuan dari pelbagai subjek, menunjukkan pemahaman multi-kontekstual yang mengagumkan yang membezakannya daripada LLM generatif yang lain. Walaupun kekuatannya, keupayaan pemikiran maju Deepseek R1 masih menghadapi cabaran di kawasan -kawasan seperti penalaran temporal yang kompleks dan pengendalian kekaburan, yang membuka pintu untuk penambahbaikan masa depan.
- Dengan membuat model sumber terbuka, DeepSeek R1 bukan sahaja memajukan pemikiran tetapi juga menjadikan AI canggih lebih mudah diakses, menawarkan pendekatan yang lebih demokratik untuk pembangunan AI.
- Keupayaan penalaran maju DeepSeek R1 membuka jalan bagi kejayaan masa depan dalam model AI, dengan potensi AGI muncul melalui penyelidikan dan inovasi yang berterusan.
- Soalan Lazim
1. Bagaimanakah DeepSeek-R1-7b membandingkan dengan model besar dalam tugas penalaran?
a. Walaupun ia tidak sepadan dengan kuasa model 32B atau 70B yang lebih besar, ia menunjukkan prestasi yang setanding dalam tugas penalaran struktur, terutamanya dalam analisis matematik dan logik. Apakah amalan terbaik untuk reka bentuk segera semasa menguji penalaran?a. Tulis keperluan langkah demi langkah, fokus pada arahan yang jelas, dan kriteria penilaian eksplisit. Soalan multipart sering memberikan wawasan yang lebih baik daripada soalan tunggal.q 3. Betapa boleh dipercayai kaedah penilaian ini?
a. Kita adalah manusia, kita mesti menggunakan otak kita untuk menilai tindak balas. Ia harus digunakan sebagai sebahagian daripada strategi penilaian yang lebih luas yang merangkumi metrik kuantitatif dan ujian dunia nyata. Mengikuti prinsip ini akan membantu penilaian yang lebih baik.
Media yang ditunjukkan dalam artikel ini tidak dimiliki oleh Analytics Vidhya dan digunakan pada budi bicara penulis.
 Komponen ejen
Komponen ejen 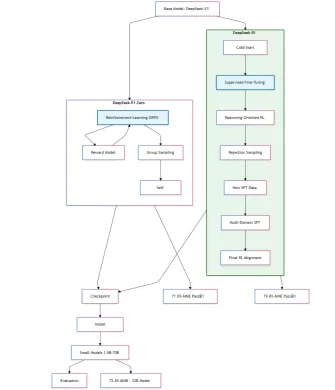
 di sini Epsilon dan beta adalah parameter hyper, dan A_I adalah kelebihan yang dikira menggunakan sekumpulan ganjaran {R1, R2, R3 ... Rg} sepadan dengan output dalam setiap kumpulan.
di sini Epsilon dan beta adalah parameter hyper, dan A_I adalah kelebihan yang dikira menggunakan sekumpulan ganjaran {R1, R2, R3 ... Rg} sepadan dengan output dalam setiap kumpulan. 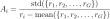
 Contoh KL Divergence
Contoh KL Divergence 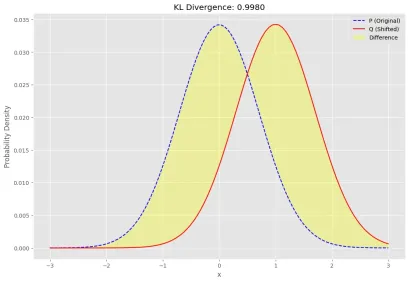

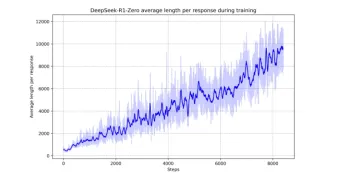 Meningkatkan keupayaan dan keupayaan umum dalam DeepSeek-R1
Meningkatkan keupayaan dan keupayaan umum dalam DeepSeek-R1 


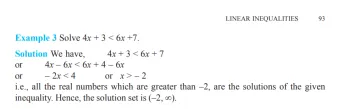 AMAZING !!
AMAZING !! 
 Ini akan menunjukkan konsistensi logik, mencadangkan penyelesaian logik, memahami hubungan kelas, dan penalaran silogistik.
Ini akan menunjukkan konsistensi logik, mencadangkan penyelesaian logik, memahami hubungan kelas, dan penalaran silogistik. 



 dilema etika: membuat keputusan dalam kereta memandu sendiri
dilema etika: membuat keputusan dalam kereta memandu sendiri 
 DeepSeek suka masalah matematik, mengendalikan kerosakan eksponen, menyediakan model matematik yang baik, dan menyediakan pengiraan.
DeepSeek suka masalah matematik, mengendalikan kerosakan eksponen, menyediakan model matematik yang baik, dan menyediakan pengiraan. 
 Walaupun, terdapat banyak contoh yang mendorong anda boleh bereksperimen dengan model pada sistem tempatan anda tanpa membelanjakan sebarang sen. Saya akan menggunakan DeepSeek-R1 untuk lebih banyak penyelidikan, dan belajar tentang bidang yang berbeza. Yang anda perlukan adalah komputer riba, masa anda, dan tempat yang bagus.
Walaupun, terdapat banyak contoh yang mendorong anda boleh bereksperimen dengan model pada sistem tempatan anda tanpa membelanjakan sebarang sen. Saya akan menggunakan DeepSeek-R1 untuk lebih banyak penyelidikan, dan belajar tentang bidang yang berbeza. Yang anda perlukan adalah komputer riba, masa anda, dan tempat yang bagus. Atas ialah kandungan terperinci DECODING DEEPSEEK R1 ' s Keupayaan Penaakulan Lanjutan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bahaya Tersembunyi Penggunaan Dalaman AI: Jurang Tadbir Urus dan Risiko BencanaApr 28, 2025 am 11:12 AM
Bahaya Tersembunyi Penggunaan Dalaman AI: Jurang Tadbir Urus dan Risiko BencanaApr 28, 2025 am 11:12 AMPenyebaran dalaman yang tidak terkawal sistem AI yang canggih menimbulkan risiko yang signifikan, menurut laporan baru dari Apollo Research. Kekurangan pengawasan ini, lazim di kalangan firma AI utama, membolehkan hasil yang berpotensi bencana, mulai dari UNCON
 Membina polygraph AIApr 28, 2025 am 11:11 AM
Membina polygraph AIApr 28, 2025 am 11:11 AMPengesan kebohongan tradisional sudah lapuk. Bergantung pada penunjuk yang disambungkan oleh gelang tangan, pengesan kebohongan yang mencetak tanda -tanda penting subjek dan tindak balas fizikal tidak tepat dalam mengenal pasti kebohongan. Inilah sebabnya mengapa keputusan pengesanan kebohongan biasanya tidak diterima pakai oleh mahkamah, walaupun ia telah membawa kepada banyak orang yang tidak bersalah yang dipenjara. Sebaliknya, kecerdasan buatan adalah enjin data yang kuat, dan prinsip kerja adalah untuk memerhatikan semua aspek. Ini bermakna saintis boleh menggunakan kecerdasan buatan kepada aplikasi yang mencari kebenaran melalui pelbagai cara. Satu pendekatan adalah untuk menganalisis tindak balas penting orang yang diinterogasi seperti pengesan dusta, tetapi dengan analisis perbandingan yang lebih terperinci dan tepat. Pendekatan lain adalah menggunakan markup linguistik untuk menganalisis apa yang orang katakan dan menggunakan logik dan penalaran. Seperti kata pepatah, satu pembohongan membiak kebohongan yang lain, dan akhirnya
 Adakah AI dibersihkan untuk berlepas dalam industri aeroangkasa?Apr 28, 2025 am 11:10 AM
Adakah AI dibersihkan untuk berlepas dalam industri aeroangkasa?Apr 28, 2025 am 11:10 AMIndustri aeroangkasa, perintis inovasi, memanfaatkan AI untuk menangani cabaran yang paling rumit. Kerumitan Peningkatan Penerbangan Moden memerlukan automasi dan keupayaan perisikan masa nyata AI untuk keselamatan yang dipertingkatkan, dikurangkan oper
 Menonton Perlumbaan Robot Spring BeijingApr 28, 2025 am 11:09 AM
Menonton Perlumbaan Robot Spring BeijingApr 28, 2025 am 11:09 AMPerkembangan pesat robotik telah membawa kita kajian kes yang menarik. Robot N2 dari Noetix beratnya lebih dari 40 paun dan tinggi 3 kaki dan dikatakan dapat backflip. Robot G1 Unitree berat kira -kira dua kali saiz N2 dan kira -kira 4 kaki tinggi. Terdapat juga banyak robot humanoid yang lebih kecil yang menyertai pertandingan ini, dan terdapat juga robot yang didorong ke hadapan oleh peminat. Tafsiran data Setengah maraton menarik lebih daripada 12,000 penonton, tetapi hanya 21 robot humanoid yang mengambil bahagian. Walaupun kerajaan menegaskan bahawa robot yang mengambil bahagian menjalankan "latihan intensif" sebelum pertandingan, tidak semua robot menyelesaikan keseluruhan persaingan. Champion - Tiangong Ult Dibangunkan oleh Pusat Inovasi Robot Humanoid Beijing
 Perangkap Cermin: Etika AI dan keruntuhan imaginasi manusiaApr 28, 2025 am 11:08 AM
Perangkap Cermin: Etika AI dan keruntuhan imaginasi manusiaApr 28, 2025 am 11:08 AMKecerdasan buatan, dalam bentuknya sekarang, tidak benar -benar pintar; Ia mahir meniru dan menyempurnakan data sedia ada. Kami tidak mewujudkan kecerdasan buatan, tetapi sebaliknya kesimpulan buatan -merapikan yang memproses maklumat, sementara manusia su
 New Google Leak mendedahkan kemas kini ciri Google Photos yang bergunaApr 28, 2025 am 11:07 AM
New Google Leak mendedahkan kemas kini ciri Google Photos yang bergunaApr 28, 2025 am 11:07 AMLaporan mendapati bahawa antara muka yang dikemas kini disembunyikan dalam kod untuk Google Photos Android versi 7.26, dan setiap kali anda melihat foto, satu baris lakaran muka yang baru dikesan dipaparkan di bahagian bawah skrin. Thumbnail wajah baru adalah tag nama yang hilang, jadi saya mengesyaki anda perlu mengkliknya secara individu untuk melihat lebih banyak maklumat mengenai setiap orang yang dikesan. Buat masa ini, ciri ini tidak memberikan maklumat selain daripada orang -orang yang ditemui oleh Google Foto dalam imej anda. Ciri ini belum tersedia, jadi kami tidak tahu bagaimana Google akan menggunakannya dengan tepat. Google boleh menggunakan gambar kecil untuk mempercepatkan mencari lebih banyak gambar orang terpilih, atau boleh digunakan untuk tujuan lain, seperti memilih individu untuk mengedit. Mari tunggu dan lihat. Buat masa ini
 Panduan untuk Finetuning Pengukuhan - Analytics VidhyaApr 28, 2025 am 09:30 AM
Panduan untuk Finetuning Pengukuhan - Analytics VidhyaApr 28, 2025 am 09:30 AMPenguatkuasaan penguatkuasaan telah mengguncang pembangunan AI dengan mengajar model untuk menyesuaikan berdasarkan maklum balas manusia. Ia menggabungkan asas pembelajaran yang diawasi dengan kemas kini berasaskan ganjaran untuk menjadikannya lebih selamat, lebih tepat, dan benar-benar membantu
 Let's Dance: Gerakan berstruktur untuk menyempurnakan jaring saraf manusia kitaApr 27, 2025 am 11:09 AM
Let's Dance: Gerakan berstruktur untuk menyempurnakan jaring saraf manusia kitaApr 27, 2025 am 11:09 AMPara saintis telah mengkaji secara meluas rangkaian saraf manusia dan mudah (seperti yang ada di C. elegans) untuk memahami fungsi mereka. Walau bagaimanapun, soalan penting timbul: Bagaimana kita menyesuaikan rangkaian saraf kita sendiri untuk berfungsi dengan berkesan bersama -sama dengan novel AI s


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

Dreamweaver Mac版
Alat pembangunan web visual

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

