
Rumah >Peranti teknologi >AI >LLM RAG: Membuat pembantu pembaca fail berkuasa AI
LLM RAG: Membuat pembantu pembaca fail berkuasa AI

- Linda Hamiltonasal
- 2025-03-04 10:40:11510semak imbas
Pengenalan
ai ada di mana -mana.sukar untuk tidak berinteraksi sekurang -kurangnya sekali sehari dengan model bahasa yang besar (LLM). Chatbots ada di sini untuk tinggal. Mereka berada dalam aplikasi anda, mereka membantu anda menulis lebih baik, mereka menyusun e -mel, mereka membaca e -mel ... baik, mereka banyak.
Dan saya tidak fikir itu buruk. Malah, pendapat saya adalah cara lain - sekurang -kurangnya setakat ini. Saya mempertahankan dan menganjurkan penggunaan AI dalam kehidupan seharian kita kerana, mari kita setuju, ia menjadikan semuanya lebih mudah.
Saya tidak perlu menghabiskan masa membaca dua kali untuk mencari masalah tanda baca atau jenis. AI melakukan itu untuk saya. Saya tidak membuang masa menulis e-mel susulan setiap hari Isnin. AI melakukan itu untuk saya. Saya tidak perlu membaca kontrak yang besar dan membosankan apabila saya mempunyai AI untuk meringkaskan titik utama dan titik tindakan kepada saya!
Ini hanya beberapa kegunaan hebat AI. Jika anda ingin mengetahui lebih banyak kes penggunaan LLM untuk menjadikan kehidupan kita lebih mudah, saya menulis keseluruhan buku tentang mereka.
sekarang, berfikir sebagai saintis data dan melihat sisi teknikal, tidak semuanya adalah cerah dan berkilat.
LLMS sangat bagus untuk beberapa kes penggunaan umum yang dikenakan kepada sesiapa atau mana -mana syarikat. Sebagai contoh, pengekodan, meringkaskan, atau menjawab soalan mengenai kandungan umum yang dibuat sehingga tarikh pemotongan latihan. Walau bagaimanapun, apabila ia berkaitan dengan aplikasi perniagaan tertentu, untuk satu tujuan, atau sesuatu yang baru yang tidak membuat tarikh cutoff, iaitu apabila model tidak berguna jika digunakan
out-of-the-box -makna, mereka tidak akan tahu jawapannya. Oleh itu, ia memerlukan pelarasan.
Latihan model LLM boleh mengambil bulan dan berjuta -juta dolar. Apa yang lebih teruk ialah jika kita tidak menyesuaikan dan menyesuaikan model untuk tujuan kita, akan ada hasil yang tidak memuaskan atau halusinasi (apabila tindak balas model tidak masuk akal diberikan pertanyaan kami).Jadi apakah penyelesaiannya? Membelanjakan banyak wang melatih semula model untuk memasukkan data kami?
tidak betul -betul. Itulah ketika generasi pengambilan semula (RAG) menjadi berguna.
RAG adalah rangka kerja yang menggabungkan mendapatkan maklumat dari pangkalan pengetahuan luaran dengan model bahasa yang besar (LLMS). Ia membantu model AI menghasilkan respons yang lebih tepat dan relevan.
mari kita ketahui lebih lanjut mengenai RAG Seterusnya.Apa itu Rag?
izinkan saya menceritakan kisah untuk menggambarkan konsep.
Saya suka filem. Untuk beberapa waktu dahulu, saya tahu filem mana yang bersaing untuk kategori filem terbaik di Oscars atau pelakon dan pelakon terbaik. Dan saya pasti tahu mana yang mendapat patung untuk tahun itu. Tetapi sekarang saya semua berkarat pada subjek itu. Jika anda bertanya kepada saya yang bersaing, saya tidak akan tahu. Dan walaupun saya cuba menjawab anda, saya akan memberi anda tindak balas yang lemah.
Jadi, untuk memberi anda respons yang berkualiti, saya akan melakukan apa yang dilakukan oleh orang lain: cari maklumat dalam talian, dapatkannya, dan kemudian berikan kepada anda. Apa yang saya buat adalah idea yang sama seperti kain: Saya memperoleh data dari pangkalan data luaran untuk memberi anda jawapan.
Apabila kita meningkatkan LLM dengan kedai kandungan di mana ia boleh pergi dan mengambil data ke Augment (meningkatkan) asas pengetahuannya, iaitu rangka kerja RAG dalam tindakan.
RAG adalah seperti membuat kedai kandungan di mana model dapat meningkatkan pengetahuannya dan bertindak balas dengan lebih tepat.
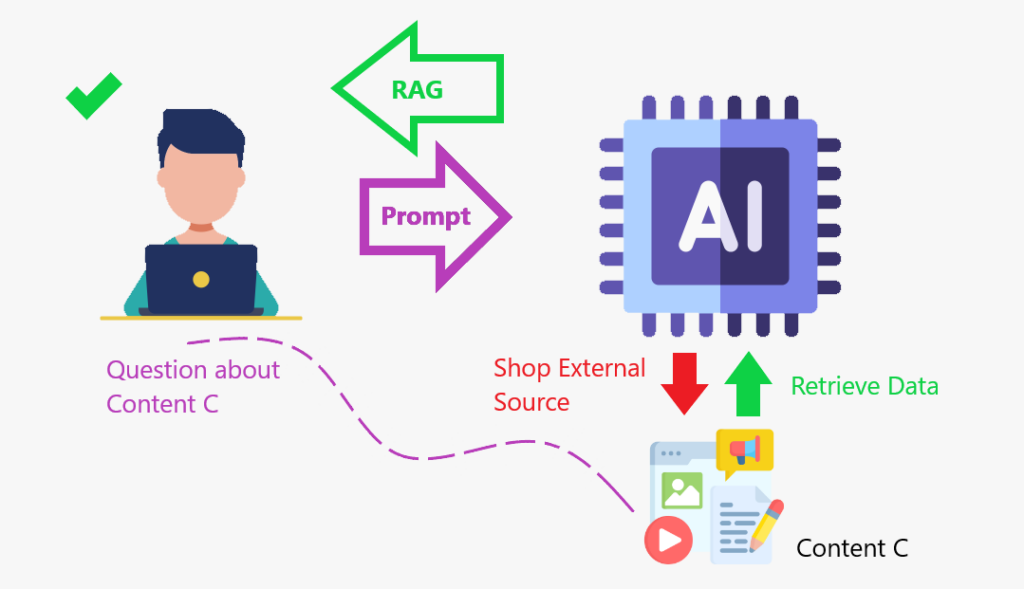 meringkaskan:
meringkaskan:
- Menggunakan algoritma carian untuk menanyakan sumber data luaran, seperti pangkalan data, pangkalan pengetahuan, dan laman web.
- pra-proses maklumat yang diambil.
- menggabungkan maklumat pra-diproses ke dalam LLM.
Sekarang kita tahu apa kerangka RAG adalah mari kita faham mengapa kita harus menggunakannya.
Berikut adalah beberapa manfaat:
- Meningkatkan ketepatan faktual dengan merujuk data sebenar.
- RAG dapat membantu LLMS memproses dan menyatukan pengetahuan untuk membuat jawapan yang lebih relevan
- RAG dapat membantu LLM mengakses pangkalan pengetahuan tambahan, seperti data organisasi dalaman
- RAG boleh membantu LLMS membuat kandungan khusus domain yang lebih tepat
- RAG dapat membantu mengurangkan jurang pengetahuan dan halusinasi AI
baik. Semua itu sangat menarik. Tetapi mari kita lihat permohonan RAG. Kami akan belajar bagaimana untuk membuat pembantu pembaca PDF berkuasa AI.
Projek
Ini adalah aplikasi yang membolehkan pengguna memuat naik dokumen PDF dan bertanya soalan mengenai kandungannya menggunakan alat pemprosesan bahasa semulajadi AI.
Aplikasi menggunakan streamlit sebagai hujung depan.
- Langchain, model GPT-4 OpenAI, dan Faiss (carian persamaan Facebook AI) untuk mendapatkan semula dokumen dan soalan menjawab di backend.
- mari kita memecahkan langkah -langkah untuk pemahaman yang lebih baik:
- Memuatkan fail PDF dan memisahkannya ke dalam potongan teks.
- ini menjadikan data dioptimumkan untuk mendapatkan semula
- Tunjukkan ketulan ke alat penyembuhan.
- Embeddings adalah perwakilan vektor berangka data yang digunakan untuk menangkap hubungan, persamaan, dan makna dengan cara yang dapat difahami oleh mesin. Mereka digunakan secara meluas dalam pemprosesan bahasa semulajadi (NLP), sistem pendahuluan, dan enjin carian.
- Seterusnya, kami meletakkan potongan teks dan embeddings dalam db yang sama untuk mendapatkan semula.
- Akhirnya, kami menjadikannya tersedia untuk llm.
Penyediaan data
Menyediakan kedai kandungan untuk LLM akan mengambil beberapa langkah, seperti yang kita lihat. Oleh itu, mari kita mulakan dengan membuat fungsi yang boleh memuatkan fail dan memecahnya ke dalam ketulan teks untuk mendapatkan semula yang cekap.
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunks
Seterusnya, kami akan mula membina aplikasi Streamlit kami, dan kami akan menggunakan fungsi itu dalam skrip seterusnya.
Aplikasi Web
Kami akan mula mengimport modul yang diperlukan dalam Python. Kebanyakan mereka akan datang dari pakej Langchain.
Faiss digunakan untuk mendapatkan semula dokumen; Openaiembeddings mengubah ketulan teks menjadi skor berangka untuk pengiraan kesamaan yang lebih baik oleh LLM; Chatopenai adalah apa yang membolehkan kita berinteraksi dengan API Openai; create_retrieval_chain adalah apa yang sebenarnya kain itu, mengambil dan menambah LLM dengan data tersebut; create_stuff_documents_chain melekatkan model dan chatprompttemplate.
NOTA: Anda perlu menghasilkan kunci terbuka untuk dapat menjalankan skrip ini. Jika ini kali pertama anda membuat akaun anda, anda mendapat beberapa kredit percuma. Tetapi jika anda memilikinya untuk beberapa waktu, mungkin anda perlu menambah 5 dolar dalam kredit untuk dapat mengakses API Openai. Pilihan menggunakan penyembuhan Face Hugging.
# Imports from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain.chains import create_retrieval_chain from langchain_openai import ChatOpenAI from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from scripts.secret import OPENAI_KEY from scripts.document_loader import load_document import streamlit as st
Coretan kod pertama ini akan membuat tajuk aplikasi, membuat kotak untuk memuat naik fail, dan sediakan fail untuk ditambah ke fungsi LOAD_DOCUMEN ().
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")
Mesin memahami nombor yang lebih baik daripada teks, jadi pada akhirnya, kita perlu menyediakan model dengan pangkalan data nombor yang dapat dibandingkan dan memeriksa persamaan ketika melakukan pertanyaan. Di sinilah embeddings berguna untuk membuat vector_db, dalam sekeping kod seterusnya ini.
# Generate embeddings # Embeddings are numerical vector representations of data, typically used to capture relationships, similarities, # and meanings in a way that machines can understand. They are widely used in Natural Language Processing (NLP), # recommender systems, and search engines. embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_KEY, model="text-embedding-ada-002") # Can also use HuggingFaceEmbeddings # from langchain_huggingface.embeddings import HuggingFaceEmbeddings # embeddings = HuggingFaceEmbeddings(model_name="sentence-transformers/all-MiniLM-L6-v2") # Create vector database containing chunks and embeddings vector_db = FAISS.from_documents(chunks, embeddings)
Seterusnya, kami membuat objek retriever untuk menavigasi dalam vector_db.
# Create a document retriever retriever = vector_db.as_retriever() llm = ChatOpenAI(model_name="gpt-4o-mini", openai_api_key=OPENAI_KEY)
Kemudian, kami akan membuat System_Prompt, yang merupakan satu set arahan kepada LLM tentang cara menjawab, dan kami akan membuat template segera, menyediakannya untuk ditambah kepada model sebaik sahaja kami mendapat input dari pengguna.
# Imports
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
def load_document(pdf):
# Load a PDF
"""
Load a PDF and split it into chunks for efficient retrieval.
:param pdf: PDF file to load
:return: List of chunks of text
"""
loader = PyPDFLoader(pdf)
docs = loader.load()
# Instantiate Text Splitter with Chunk Size of 500 words and Overlap of 100 words so that context is not lost
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
# Split into chunks for efficient retrieval
chunks = text_splitter.split_documents(docs)
# Return
return chunks
bergerak, kami membuat teras kerangka RAG, menyatukan objek retriever dan prompt. Objek ini menambah dokumen yang relevan dari sumber data (mis., Pangkalan data vektor) dan menjadikannya siap untuk diproses menggunakan LLM untuk menghasilkan respons.
# Imports from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain.chains import create_retrieval_chain from langchain_openai import ChatOpenAI from langchain.chains.combine_documents import create_stuff_documents_chain from langchain_core.prompts import ChatPromptTemplate from scripts.secret import OPENAI_KEY from scripts.document_loader import load_document import streamlit as st
Akhirnya, kami membuat soalan pembolehubah untuk input pengguna. Jika kotak soalan ini dipenuhi dengan pertanyaan, kami lulus ke rantai, yang memanggil LLM untuk memproses dan mengembalikan respons, yang akan dicetak pada skrin aplikasi.
# Create a Streamlit app
st.title("AI-Powered Document Q&A")
# Load document to streamlit
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
# If a file is uploaded, create the TextSplitter and vector database
if uploaded_file :
# Code to work around document loader from Streamlit and make it readable by langchain
temp_file = "./temp.pdf"
with open(temp_file, "wb") as file:
file.write(uploaded_file.getvalue())
file_name = uploaded_file.name
# Load document and split it into chunks for efficient retrieval.
chunks = load_document(temp_file)
# Message user that document is being processed with time emoji
st.write("Processing document... :watch:")
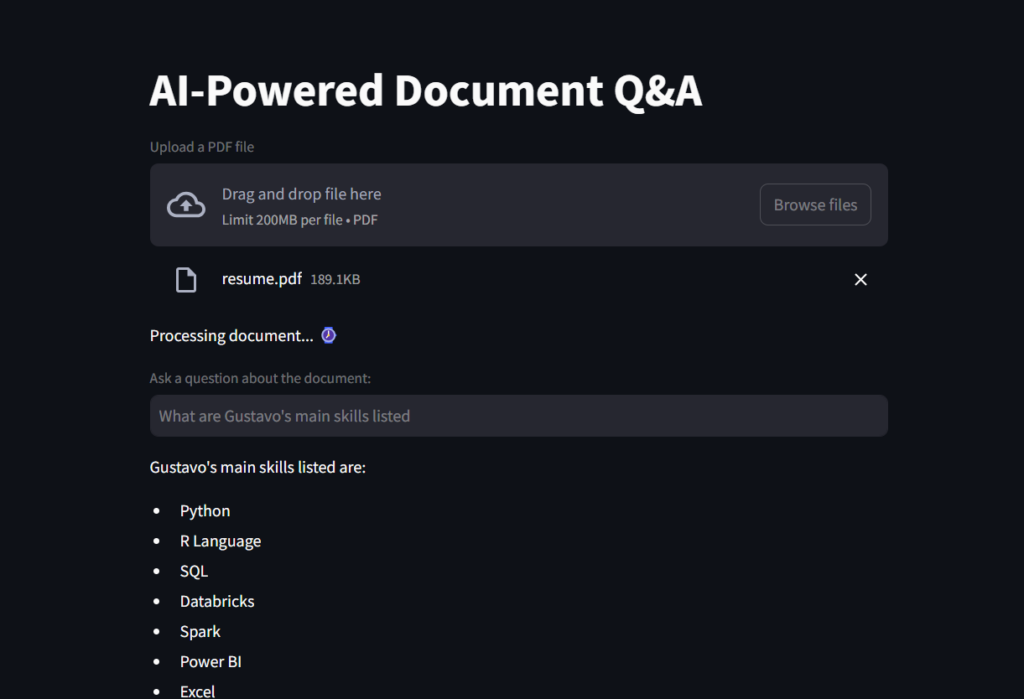
Berikut adalah tangkapan skrin hasilnya.
dan ini adalah gif bagi anda untuk melihat pembaca fail pembaca AI dalam tindakan!

sebelum anda pergi
Dalam projek ini, kami belajar apa kerangka RAG dan bagaimana ia membantu LLM untuk melakukan yang lebih baik dan juga berfungsi dengan baik dengan pengetahuan tertentu.
AI boleh dikuasakan dengan pengetahuan dari manual arahan, pangkalan data dari syarikat, beberapa fail kewangan, atau kontrak, dan kemudian menjadi halus untuk bertindak balas dengan tepat kepada pertanyaan kandungan khusus domain. Pangkalan pengetahuan adalah ditambah dengan kedai kandungan.
untuk merakam, ini adalah bagaimana kerangka kerja:
1 2 3
Konteks Augment→ Dokumen yang diambil ditambah ke input. 4 ⃣ 🎜> menghasilkan respons
→ LLM memproses input gabungan dan menghasilkan jawapan.GitHub Repository
https://github.com/gurezende/basic-ragtentang saya
Jika anda menyukai kandungan ini dan ingin mengetahui lebih lanjut mengenai kerja saya, inilah laman web saya, di mana anda juga boleh mencari semua kenalan saya.https://gustavorsantos.me
Rujukan
https://cloud.google.com/use-cases/retrieval-augmented-generation
https://www.ibm.com/think/topics/retrieval-augmented-generation
https://youtu.be/t-d1ofcdw1m?si=g0uwfh5-wznmu0nw
https://python.langchain.com/docs/introduction
https://www.geeksforgeeks.org/how-to-get-your-own-openai-napi-key
Atas ialah kandungan terperinci LLM RAG: Membuat pembantu pembaca fail berkuasa AI. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI