
Rumah >Peranti teknologi >AI >DeepSeek melancarkan Flashmla
DeepSeek melancarkan Flashmla

- Joseph Gordon-Levittasal
- 2025-03-03 18:10:10305semak imbas
Pelepasan sumber terbuka DeepSeek: FlashMla, kernel CUDA mempercepatkan LLMS. Ini kernel penyahkodan pelbagai latar (MLA) yang dioptimumkan, yang direka khusus untuk GPU hopper, dengan ketara meningkatkan kelajuan dan kecekapan hosting model AI. Penambahbaikan utama termasuk sokongan BF16 dan cache KV paged (saiz 64-blok), menghasilkan tanda aras prestasi yang mengagumkan.
? Hari 1 dari #OpensourceWeek: FlashMla
DeepSeek dengan bangga melancarkan FlashMla, kernel penyahkodan MLA kecekapan tinggi untuk GPU Hopper. Dioptimumkan untuk urutan panjang berubah-ubah dan kini dalam pengeluaran.
✅ BF16 Sokongan
✅ cache kv paged (saiz blok 64)
⚡ 3000 GB/s Memory-bound & 580 tflops ...- DeepSeek (@deepseek_ai) 24 Februari 2025
Ciri -ciri Utama:
- BF16 Precision: Membolehkan pengiraan yang cekap sambil mengekalkan kestabilan berangka.
- cache kV paged (saiz 64-blok): Meningkatkan kecekapan memori dan mengurangkan latensi, terutama penting untuk model besar.
Pengoptimuman ini mencapai lebar lebar memori 3000 GB/s dan 580 TFLOPS dalam senario terikat pengiraan pada GPU H800 SXM5 menggunakan CUDA 12.6. Ini secara dramatik meningkatkan prestasi kesimpulan AI. Sebelum ini digunakan dalam model DeepSeek, FlashMla kini mempercepatkan DeepSeek AI's R1 V3.
Jadual Kandungan:
- Apa itu flashmla?
- Memahami Perhatian Laten Multi-Head (MLA)
- Batasan Perhatian Multi-Ketua Standard
- Strategi Pengoptimuman Memori MLA
- caching nilai kunci dan penyahkodan autoregressive
- KV Caching Mechanics
- Menangani cabaran memori
- Peranan FlashMla dalam Model DeepSeek
- Nvidia Hopper Architecture
- analisis prestasi dan implikasi
- Kesimpulan
Apakah flashmla?
FlashMla adalah kernel penyahkodan MLA yang sangat dioptimumkan yang dibina untuk NVIDIA Hopper GPU. Reka bentuknya memprioritaskan kelajuan dan kecekapan, mencerminkan komitmen DeepSeek terhadap pecutan model AI yang berskala.
Keperluan perkakasan dan perisian:
- GPU Senibina Hopper (mis., H800 SXM5)
- CUDA 12.3
- Pytorch 2.0
Penanda aras prestasi:
FlashMla menunjukkan prestasi luar biasa:
- jalur lebar memori: sehingga 3000 gb/s (menghampiri puncak teoritis H800 SXM5).
- Output pengiraan: hingga 580 TFLOPS untuk pendaraban matriks BF16 (dengan ketara melebihi puncak teoritis H800).
Memahami Perhatian Laten Multi-Head (MLA)
MLA, yang diperkenalkan dengan DeepSeek-V2, menangani batasan memori Perhatian Multi-Head Standard (MHA) dengan menggunakan matriks unjuran berpangkat rendah. Tidak seperti kaedah seperti perhatian kumpulan, MLA meningkatkan prestasi sambil mengurangkan overhead memori.
Batasan Perhatian Multi-Ketua Standard:
Skala cache KV MHA secara linear dengan panjang urutan, mewujudkan kesesakan memori untuk urutan panjang. Saiz cache dikira sebagai: seq_len * n_h * d_h (di mana n_h adalah bilangan kepala perhatian dan d_h adalah dimensi kepala).
Pengoptimuman Memori MLA:
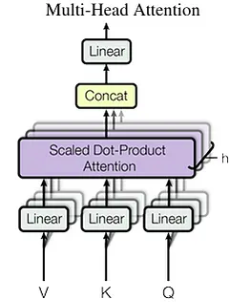
), mengurangkan saiz cache KV ke c_t (di mana seq_len * d_c adalah dimensi vektor laten). Ini mengurangkan penggunaan memori dengan ketara (sehingga 93.3% pengurangan dalam DeepSeek-V2). d_c
caching nilai kunci dan penyahkodan autoregressive
KV caching mempercepatkan penyahkodan autoregressive dengan menggunakan semula pasangan nilai kunci yang dikira sebelum ini. Walau bagaimanapun, ini meningkatkan penggunaan memori.
Menangani cabaran memori:
Teknik seperti perhatian pelbagai pertanyaan (MQA) dan perhatian-pertanyaan-pertanyaan (GQA) mengurangkan masalah memori yang berkaitan dengan caching KV.
Peranan FlashMla dalam Model DeepSeek:
Model FlashMla Powers DeepSeek R1 dan V3, membolehkan aplikasi AI berskala besar yang cekap.
Nvidia Hopper Architecture
 Nvidia Hopper adalah seni bina GPU berprestasi tinggi yang direka untuk beban kerja AI dan HPC. Inovasinya, seperti enjin transformer dan MIG generasi kedua, membolehkan kelajuan dan skalabiliti yang luar biasa.
Nvidia Hopper adalah seni bina GPU berprestasi tinggi yang direka untuk beban kerja AI dan HPC. Inovasinya, seperti enjin transformer dan MIG generasi kedua, membolehkan kelajuan dan skalabiliti yang luar biasa.
Analisis prestasi dan implikasi
FlashMla mencapai 580 TFLOPS untuk pendaraban matriks BF16, lebih daripada dua kali ganda puncak teoretikal GPU H800. Ini menunjukkan penggunaan sumber GPU yang sangat cekap.
Kesimpulan
FlashMla mewakili kemajuan besar dalam kecekapan kesimpulan AI, terutamanya untuk GPU Hopper. Pengoptimuman MLAnya, digabungkan dengan sokongan BF16 dan caching KV paged, memberikan peningkatan prestasi yang luar biasa. Ini menjadikan model AI berskala besar lebih mudah diakses dan kos efektif, menetapkan penanda aras baru untuk kecekapan model.
Atas ialah kandungan terperinci DeepSeek melancarkan Flashmla. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI