
Rumah >Peranti teknologi >AI >Membangunkan panduan pintar berkuasa AI untuk perancangan & keusahawanan perniagaan
Membangunkan panduan pintar berkuasa AI untuk perancangan & keusahawanan perniagaan

- 王林asal
- 2025-02-25 18:36:11152semak imbas
Jika anda bukan ahli sederhana, anda boleh membaca cerita penuh di pautan ini.
selepas pelancaran CHATGPT dan lonjakan model bahasa besar (LLMS) yang berikut, batasan halusinasi mereka, tarikh pemotongan pengetahuan, dan ketidakupayaan untuk memberikan maklumat organisasi atau orang tertentu tidak lama lagi menjadi jelas dan dilihat sebagai major kelemahan. Untuk menangani isu -isu ini, kaedah Pengambilan Pengambilan Generasi (RAG) tidak lama lagi mendapat daya tarikan yang mengintegrasikan data luaran ke LLM dan membimbing tingkah laku mereka untuk menjawab soalan dari asas pengetahuan yang diberikan.
Menariknya, kertas pertama di RAG diterbitkan pada tahun 2020 oleh penyelidik dari Facebook AI Research (sekarang meta ai), tetapi tidak sampai kedatangan chatgpt yang potensinya telah direalisasikan sepenuhnya. Sejak itu, tidak ada berhenti. Rangka RAG yang lebih maju dan kompleks diperkenalkan yang bukan sahaja meningkatkan ketepatan teknologi ini tetapi juga membolehkannya menangani data multimodal, memperluaskan potensi untuk pelbagai aplikasi. Saya menulis mengenai topik ini secara terperinci dalam artikel -artikel berikut, secara khusus membincangkan RAG multimodal konteks, AI multimodal mencari aplikasi perniagaan, dan pengekstrakan maklumat dan platform pembuatan jodoh.
Mengintegrasikan data multimodal ke dalam model bahasa yang besar
Multimodal AI Mencari Aplikasi Perniagaancarian web masa nyata untuk mengakses maklumat terkiniPengekstrakan dan Matchmaking Maklumat AI yang berkuasa
Dengan landskap teknologi RAG yang berkembang dan keperluan akses data yang baru muncul, ia direalisasikan bahawa fungsi kain retriever sahaja, yang menjawab soalan dari asas pengetahuan statik, dapat dilanjutkan dengan mengintegrasikan sumber pengetahuan dan alat lain yang pelbagai seperti:
pelbagai pangkalan data (mis., Pangkalan pengetahuan yang terdiri daripada pangkalan data vektor dan graf pengetahuan)
API luaran untuk mengumpul data tertentu seperti trend pasaran saham atau data dari alat khusus syarikat seperti saluran kendur atau akaun e-mel
- alat untuk tugas seperti analisis data, penulisan laporan, kajian literatur, dan carian orang, dan lain -lain
- Membandingkan dan menyatukan maklumat dari pelbagai sumber.
- Untuk mencapai matlamat ini, kain harus dapat memilih sumber pengetahuan dan/atau alat yang terbaik berdasarkan pertanyaan. Kemunculan ejen AI memperkenalkan idea " rag agentik
- " yang boleh memilih tindakan terbaik berdasarkan pertanyaan.
- Panduan Perniagaan dan Keusahawanan sebagai asas pengetahuan yang mengandungi maklumat mengenai perancangan perniagaan, keusahawanan, pendaftaran syarikat, cukai, idea perniagaan, peraturan dan peraturan, peluang perniagaan, lesen dan permit, garis panduan perniagaan, dan lain -lain. carian web untuk mengambil maklumat terkini dengan sumber.
- Alat Pengekstrakan Pengetahuan untuk mengambil maklumat dari sumber yang dipercayai. Maklumat ini merangkumi kenalan pihak berkuasa yang berkaitan, peraturan cukai baru -baru ini, peraturan pendaftaran perniagaan baru -baru ini, dan peraturan pelesenan baru -baru ini.
- , Sederhana,
- atau Penjelasan
- . Khususnya, artikel ini disusun di sekitar topik berikut:
Dalam artikel ini, kami akan membangunkan aplikasi Rag Agentic tertentu, yang dipanggil Panduan Perniagaan Pintar (SBG) - versi pertama alat yang merupakan sebahagian daripada projek berterusan kami yang dipanggil Upbeat, dibiayai oleh Interreg Central Baltic. Projek ini memberi tumpuan kepada pendatang yang semakin meningkat di Finland dan Estonia untuk keusahawanan dan perancangan perniagaan menggunakan AI. SBG adalah salah satu alat yang dimaksudkan untuk digunakan dalam proses peningkatan projek ini. Alat ini memberi tumpuan kepada menyediakan maklumat yang tepat dan cepat dari sumber yang sahih kepada orang yang berniat untuk memulakan perniagaan, atau yang sudah menjalankan perniagaan.
RAG Agentic SBG terdiri daripada:
Apa yang istimewa mengenai kain ini? pilihan untuk memilih model sumber terbuka yang berbeza
(- llama, mistral, gemma
Membangunkan aliran kerja aggraf menggunakan Langgraph.
Membangunkan RAG Agentic Advanced (selepas ini dipanggil Panduan Perniagaan Pintar atau SBG) menggunakan model sumber terbuka percuma-
keseluruhan kod aplikasi ini boleh didapati di GitHub.
streamlit antara muka pengguna grafik. mari kita menyelam ke dalamnya.
Membina asas pengetahuan dengan llamaparsing dan langchain
Pangkalan pengetahuan SBG terdiri daripada panduan perniagaan dan keusahawanan yang diterbitkan oleh agensi Finland. Oleh kerana panduan ini adalah besar dan mencari maklumat yang diperlukan dari mereka tidak remeh, tujuannya adalah untuk membangunkan kain ragut yang tidak hanya dapat memberikan maklumat yang tepat dari panduan ini tetapi juga dapat menambah mereka dengan carian web dan sumber -sumber lain yang dipercayai Finland untuk maklumat yang dikemas kini.
Llamaparse adalah platform parsing dokumen genai-asli yang dibina dengan LLM dan untuk kes penggunaan LLM. Saya telah menjelaskan penggunaan llamaparse dalam artikel yang saya sebutkan di atas. Kali ini, saya menghuraikan dokumen secara langsung di Llamicloud. Llamaparse menawarkan 1000 kredit percuma setiap hari. Penggunaan kredit ini bergantung pada mod parsing. Untuk pdf teks sahaja, ' fast ' mod (1 kredit / 3 halaman) berfungsi dengan baik yang melangkau OCR, pengekstrakan imej, dan pengenalan jadual / tajuk. Terdapat mod lain yang lebih maju yang tersedia dengan jumlah kredit yang lebih tinggi setiap halaman. Saya memilih mod ' premium ' yang melakukan OCR, pengekstrakan imej, dan pengenalpastian jadual/tajuk dan sesuai untuk dokumen yang kompleks dengan imej.
Saya menentukan arahan parsing berikut.
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.
Dokumen parsed telah dimuat turun dalam format markdown dari Llamicloud. Parsing yang sama boleh dilakukan melalui API Llamacloud seperti berikut.
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content)
Berikut adalah halaman contoh dari kreativiti dan perniagaan panduan oleh Pikkala, A. et al., (2015) (" percuma untuk menyalin untuk kegunaan peribadi atau awam bukan komersial dengan atribusi ").

Berikut adalah output dihuraikan halaman ini. Llamaparse dengan cekap diekstrak maklumat dari semua struktur di halaman. Buku nota yang ditunjukkan dalam halaman dalam format imej.
[Creativity and Business, page 8] # How to use this book 1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support. 2. Each section opens with a creative entrepreneur's thought on the topic. 3. The introduction gives a brief description of the topic. 4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further. ## What is your business idea "I would like to launch a touring theatre company." Do you have an idea about a product or service you would like to sell? Or do you have a bunch of ideas you have been mull- ing over for some time? This section will help you get a better understanding about your business idea and what competen- cies you already have that could help you implement it, and what types of competencies you still need to gain. ### EXTRA Business idea development in a nutshell I found a great definition of what business idea development is from the My Coach online service (Youtube 27 May 2014). It divides the idea development process into three stages: the thinking - stage, the (subconscious) talking - stage, and the customer feedback stage. It is important that you talk about your business idea, as it is very easy to become stuck on a particular path and ignore everything else. You can bounce your idea around with all sorts of people: with a local business advisor; an experienced entrepreneur; or a friend. As you talk about your business idea with others, your subconscious will start working on the idea, and the feedback from others will help steer the idea in the right direction. ### Recommended reading Taivas + helvetti (Terho Puustinen & Mika Mäkeläinen: One on One Publishing Oy 2013) ### Keywords treasure map; business idea; business idea development ## EXERCISE: Identifying your personal competencies Write down the various things you have done in your life and think what kind of competencies each of these things has given you. The idea is not just to write down your education, training and work experience like in a CV; you should also include hobbies, encounters with different types of people, and any life experiences that may have contributed to you being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending on what types of experiences you have had time to accumulate. The final circle can be you at this moment. PERSONAL CAREER PATH SUPPLEMENTARY PERSONAL DEVELOPMENT (e.g. training courses; literature; seminars) Fill in the "My Competencies" section of the Creative Business Model Canvas: 5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand. 6. For each topic, tips on further reading are given in the grey box. 7. The second grey box contains recommended keywords for searching more information about the topic online. 8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74), by the end of the book you will have a complete business plan. 9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section, by the time you get to the Finance and Administration section you will already know your start-up costs and you can enter them in the receipt provided in the Finance and Administration section (page 57). This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc. Factual information about Finnish practices should also be checked in case of differing interpretations by authorities. [Creativity and Business, page 8]
Dokumen markdown yang dihuraikan kemudian dibahagikan kepada ketulan menggunakan Langchain RecursiveCharacterTextSplitter dengan chunk_size = 3000 dan chunk_overlap = 200.
def staticChunker(folder_path):
docs = []
print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}")
# Loop through all .md files in the folder
for file_name in os.listdir(folder_path):
if file_name.endswith(".md"):
file_path = os.path.join(folder_path, file_name)
print(f"Processing file: {file_path}")
# Load documents from the Markdown file
loader = UnstructuredMarkdownLoader(file_path)
documents = loader.load()
# Add file-specific metadata (optional)
for doc in documents:
doc.metadata["source_file"] = file_name
# Split loaded documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
chunked_docs = text_splitter.split_documents(documents)
docs.extend(chunked_docs)
return docs
Selanjutnya, sebuah vektor yang dibuat dalam pangkalan data Chroma menggunakan model embedding seperti Open-Source Model All-Minilm-L6-V2 atau Openai's Text-embedding-3-Large .
def load_or_create_vs(persist_directory):
# Check if the vector store directory exists
if os.path.exists(persist_directory):
print("Loading existing vector store...")
# Load the existing vector store
vectorstore = Chroma(
persist_directory=persist_directory,
embedding_function=st.session_state.embed_model,
collection_name=collection_name
)
else:
print("Vector store not found. Creating a new one...n")
docs = staticChunker(DATA_FOLDER)
print("Computing embeddings...")
# Create and persist a new Chroma vector store
vectorstore = Chroma.from_documents(
documents=docs,
embedding=st.session_state.embed_model,
persist_directory=persist_directory,
collection_name=collection_name
)
print('Vector store created and persisted successfully!')
return vectorstore
Membuat aliran kerja agentik
Ejen AI adalah gabungan alur kerja dan logik membuat keputusan untuk menjawab soalan-soalan yang bijak atau melakukan tugas-tugas kompleks lain yang perlu dipecah menjadi sub-tugas yang lebih mudah.
Saya menggunakan Langgraph untuk merancang aliran kerja untuk ejen AI kami untuk urutan tindakan atau keputusan dalam bentuk graf. Ejen kami perlu memutuskan sama ada untuk menjawab soalan dari pangkalan data vektor (asas pengetahuan), carian web, carian hibrid, atau dengan menggunakan alat.
Dalam artikel berikut saya, saya menjelaskan proses membuat aliran kerja agregat menggunakan Langgraph.
bagaimana untuk membangunkan ejen AI percuma dengan carian internet automatik
kita perlu membuat graf nod yang mewakili alur kerja untuk membuat keputusan (mis., Carian web atau carian pangkalan data vektor). Nod disambungkan oleh tepi yang menentukan aliran keputusan dan tindakan (mis., Apakah keadaan seterusnya selepas pengambilan semula). Grafik State menjejaki maklumat kerana ia bergerak melalui graf supaya ejen menggunakan data yang betul untuk setiap langkah.
Titik masuk dalam alur kerja adalah fungsi penghala yang menentukan nod awal untuk dilaksanakan dalam alur kerja dengan menganalisis pertanyaan pengguna. Seluruh aliran kerja mengandungi nod berikut.
- mengambil : mengambil bahagian -bahagian maklumat yang sama secara semantik dari vektor.
- _ gred_documents _: gred Relevan ketulan yang diambil berdasarkan pertanyaan pengguna.
- _ route_after_grading _: Berdasarkan penggredan, menentukan sama ada untuk memberi respons dengan dokumen yang diambil atau teruskan ke carian web.
- WebSearch : mengambil maklumat dari sumber web menggunakan API enjin carian tavily.
-
menghasilkan : menghasilkan respons kepada pertanyaan pengguna menggunakan konteks yang disediakan (maklumat yang diambil dari kedai vektor dan/atau carian web). _ - get_contact_tool _: mengambil maklumat hubungan dari URL yang dipercayai yang dipercayai yang berkaitan dengan perkhidmatan imigresen Finland. _
- get_tax_info _: mengambil maklumat yang berkaitan dengan cukai dari URL yang dipercayai yang telah ditetapkan. _
- get_registration_info _: mengambil butiran mengenai proses pendaftaran syarikat di Finland dari URL yang dipercayai yang telah ditetapkan. _
- get_licensing_info _: mengambil maklumat mengenai lesen dan permit yang diperlukan untuk memulakan perniagaan di Finland. _ hybrid_search
- _: Menggabungkan hasil pengambilan semula dokumen dan internet untuk memberikan konteks yang lebih luas untuk menjawab pertanyaan.
- tidak berkaitan : Mengendalikan soalan yang tidak berkaitan dengan fokus alur kerja Berikut adalah tepi dalam aliran kerja.
- _ mengambil → gred_documents _: dokumen yang diambil dihantar untuk penggredan.
- _ gred_documents → WebSearch _: carian web dipanggil jika dokumen yang diambil dianggap tidak relevan.
- _ gred_documents → menjana _: hasil kepada penjanaan tindak balas jika dokumen yang diambil adalah relevan.
- WebSearch → Generate : Lulus hasil carian web untuk penjanaan respons.
-
info , _get_registration info , _get_licensing info → menjana menjana nod lulus maklumat yang diambil dari sumber yang dipercayai untuk respons tertentu Generasi. _hybrid carian - → menghasilkan : Lulus hasil gabungan (Vectorstore WebSearch) untuk penjanaan respons. tidak berkaitan
- → Generate : memberikan respons penolakan untuk soalan yang tidak berkaitan. Struktur keadaan graf bertindak sebagai bekas untuk mengekalkan keadaan alur kerja dan termasuk unsur -unsur berikut:
- Soalan
- : pertanyaan atau input pengguna yang memacu alur kerja. Generasi
- : Sambutan akhir yang dihasilkan kepada pertanyaan pengguna, yang dihuni selepas pemprosesan. _ web_search_needed _: bendera yang menunjukkan sama ada carian web diperlukan berdasarkan kaitan dokumen yang diambil.
-
Dokumen - : Senarai dokumen yang diambil atau diproses yang berkaitan dengan pertanyaan. _ Jawapan_Style _: Menentukan gaya jawapan yang dikehendaki, seperti "ringkas," "sederhana," atau "penjelasan".
- Struktur keadaan graf ditakrifkan seperti berikut: Mengikuti fungsi penghala menganalisis pertanyaan dan mengarahkannya ke nod yang relevan untuk pemprosesan. Rantaian dibuat terdiri daripada prompt untuk memilih alat/nod dari kamus pemilihan alat dan pertanyaan. Rantaian itu memanggil router llm untuk memilih alat yang berkaitan.
Soalan -soalan yang tidak berkaitan dengan alur kerja diarahkan ke _handle
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format. If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text. Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7]. Include the document name and page number at the start and end of each extracted page.nod yang tidak berkaitan
yang memberikan tindak balas sandaran melalui
menghasilkanimport os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content) node.
keseluruhan alur kerja digambarkan dalam angka berikut. mengambil nod menyerahkan retriever dengan soalan untuk mengambil potongan maklumat yang relevan dari kedai vektor. Dokumen ini (" " (dipilih oleh butang radio di antara muka pengguna), atau fungsi penghala memutuskan untuk mengarahkan pertanyaan ke _web cari untuk mengambil maklumat baru -baru ini dan lebih relevan.
API percuma enjin carian tavily boleh didapati dengan membuat akaun di laman web mereka. Pelan percuma menawarkan 1000 mata kredit setiap bulan. Hasil carian yang tavily dilampirkan kepada pembolehubah negeri " Dokumen " yang kemudiannya diserahkan kepada menghasilkan nod dengan pembolehubah keadaan " soalan ".
Carian Hibrid menggabungkan hasil kedua -dua retriever dan carian tavily dan populates " Dokumen soalan " pembolehubah negara.
Penjanaan Alat
Alat yang digunakan dalam aliran kerja agentik ini adalah fungsi pemotongan untuk mengambil maklumat daripada URL yang dipercayai yang telah ditetapkan. Perbezaan antara tavily dan alat -alat ini adalah bahawa Tavily melakukan carian internet yang lebih luas untuk membawa hasil dari pelbagai sumber. Manakala, alat ini menggunakan perpustakaan pemotongan web sup yang indah untuk mengekstrak maklumat dari sumber yang dipercayai (URL yang telah ditetapkan). Dengan cara ini, kami memastikan bahawa maklumat mengenai pertanyaan tertentu diekstrak daripada sumber yang dipercayai dan dipercayai. Di samping itu, pengambilan maklumat ini sepenuhnya percuma. Berikut adalah bagaimana _get_tax info nod berfungsi dengan beberapa fungsi penolong. Alat lain (nod) jenis ini juga berfungsi dengan cara yang sama. Node, menghasilkan , mewujudkan tindak balas akhir dengan menggunakan rantai dengan prompt yang telah ditetapkan (Langkhain's prompttemplate kelas) yang diterangkan di bawah. _Rag ", "
Terdapat fungsi bantuan lain dalam _agentic rag.py semasa inisialisasi aplikasi dan __ dicetuskan setiap kali model atau pemboleh ubah keadaan diubah melalui aplikasinya Ia menghidupkan semula komponen dan menjimatkan keadaan yang dikemas kini. Fungsi ini juga menjejaki pelbagai pembolehubah sesi dan menghalang permulaan yang berlebihan.
Fungsi penolong berikut memulakan LLM menjawab, Model Embedding, Router LLM, dan penggredan LLM. Senarai nama model, _model senarai , digunakan untuk menjejaki model semasa penukaran dinamik model oleh menghasilkan nod. Mewujudkan alur kerja
Sekarang keadaan graf, nod, titik kemasukan bersyarat menggunakan _route soalan , dan tepi ditakrifkan untuk menubuhkan aliran antara nod. Akhirnya, alur kerja disusun ke dalam aplikasi fungsi untuk memilih nod pertama dalam alur kerja berdasarkan pertanyaan. Kelebihan bersyarat (_workflow.add_conditional tepi ) menerangkan sama ada untuk peralihan ke websearch atau untuk menghasilkan nod berdasarkan perkaitan bahagian yang ditentukan oleh _grade Dokumen nod. Aplikasi Streamlit dalam App.Py menyediakan antara muka interaktif untuk bertanya soalan dan tanggapan paparan menggunakan tetapan dinamik untuk pemilihan model, gaya jawapan, dan alat khusus pertanyaan. Fungsi _initialize App , yang diimport dari _agentic rag.py, memulakan semua pembolehubah sesi termasuk semua LLM, model embedding, dan pilihan lain yang dipilih dari bar sisi kiri.
sys.stdout ke io.stringio buffer. Kandungan penampan ini kemudian dipaparkan dalam pemegang tempat debug menggunakan komponen _text dalam streamlit.
llama-3.3-70b-versatile dengan ' ringkas' gaya jawapan yang dipilih. Router query (_ROUTE Soalan ) menyerahkan retriever (carian vektor) dan fungsi grader mendapati semua ketulan yang diambil relevan. Oleh itu, keputusan untuk menghasilkan jawapan melalui menghasilkan nod diambil oleh _route_after node .
'. Seperti yang diarahkan dalam _rag prompt , LLM menghuraikan jawapan dengan lebih banyak penjelasan.
Imej berikut menunjukkan carian web yang dipanggil oleh _ROUTE_AFTER
Imej berikut menunjukkan tindak balas yang dihasilkan dengan pilihan carian hibrid yang dipilih dalam aplikasi qustion node mendapati _internet_search diaktifkan bendera negara ' true ' dan mengarahkan soalan ke _hybrid carian node.
arahan untuk lanjutan
Itu semua orang! Jika anda menyukai artikel itu, sila tampuk artikel (berbilang kali ? ), tulis komen, dan ikuti saya di Medium dan LinkedIn. 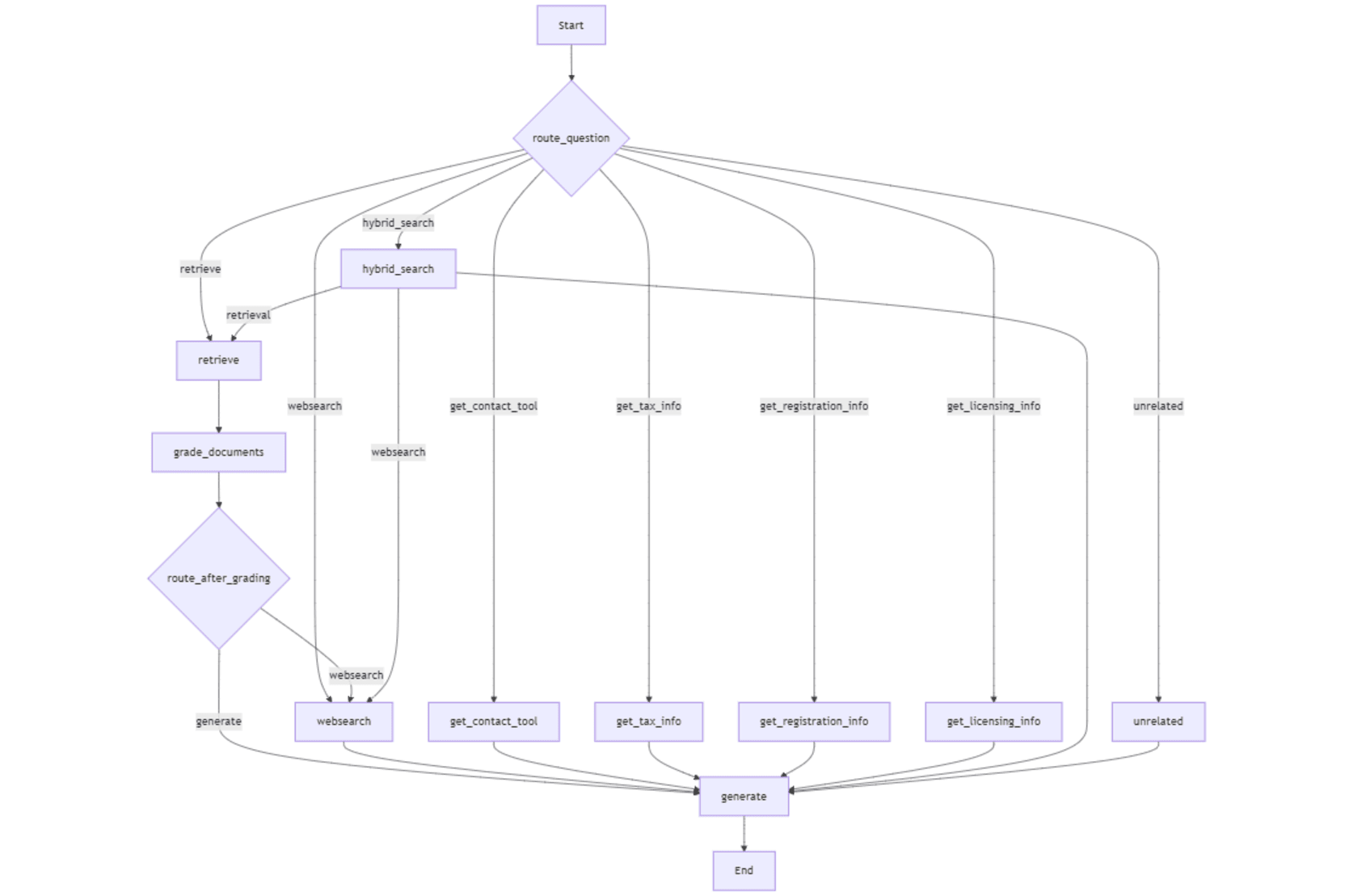
pengambilan dan penggredan
You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
dicapai sama ada oleh node _route_after You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
Menjana tindak balas
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content) soalan [Creativity and Business, page 8]
# How to use this book
1. The book is divided into six chapters and sub-sections dealing with different topics. You can read the book through one chapter and topic at a time, or you can use the checklist of the table of contents to select sections on topics in which you need more information and support.
2. Each section opens with a creative entrepreneur's thought on the topic.
3. The introduction gives a brief description of the topic.
4. Each section contains exercises that help you reflect on your own skills and business idea and develop your business idea further.
## What is your business idea
"I would like to launch
a touring theatre company."
Do you have an idea about a product or service you would like
to sell? Or do you have a bunch of ideas you have been mull-
ing over for some time? This section will help you get a better
understanding about your business idea and what competen-
cies you already have that could help you implement it, and
what types of competencies you still need to gain.
### EXTRA
Business idea development
in a nutshell
I found a great definition of what business idea development
is from the My Coach online service (Youtube 27 May 2014).
It divides the idea development process into three stages:
the thinking - stage, the (subconscious) talking - stage, and the
customer feedback stage. It is important that you talk about
your business idea, as it is very easy to become stuck on a
particular path and ignore everything else. You can bounce
your idea around with all sorts of people: with a local business
advisor; an experienced entrepreneur; or a friend. As you talk
about your business idea with others, your subconscious will
start working on the idea, and the feedback from others will
help steer the idea in the right direction.
### Recommended reading
Taivas + helvetti
(Terho Puustinen & Mika Mäkeläinen:
One on One Publishing Oy 2013)
### Keywords
treasure map; business idea; business idea development
## EXERCISE: Identifying your personal competencies
Write down the various things you have done in your life and think what kind of competencies each of these things has
given you. The idea is not just to write down your education,
training and work experience like in a CV; you should also
include hobbies, encounters with different types of people, and any life experiences that may have contributed to you
being here now with your business idea. The starting circle can be you at any age, from birth to adulthood, depending
on what types of experiences you have had time to accumulate. The final circle can be you at this moment.
PERSONAL CAREER PATH
SUPPLEMENTARY
PERSONAL DEVELOPMENT
(e.g. training courses;
literature; seminars)
Fill in the
"My Competencies"
section of the
Creative Business
Model Canvas:
5. Each section also includes an EXTRA box with interesting tidbits about the topic at hand.
6. For each topic, tips on further reading are given in the grey box.
7. The second grey box contains recommended keywords for searching more information about the topic online.
8. By completing each section of the one-page business plan or "Creative Business Model Canvas" (page 74),
by the end of the book you will have a complete business plan.
9. By writing down your business start-up costs (e.g. marketing or logistics) in the price tag box of each section,
by the time you get to the Finance and Administration section you will already know your start-up costs
and you can enter them in the receipt provided in the Finance and Administration section (page 57).
This book is based on Finnish practices. The authors and the publisher are not responsible for the applicability of factual information to other
countries. Readers are advised to check country-specific information on business structures, support organisations, taxation, legislation, etc.
Factual information about Finnish practices should also be checked in case of differing interpretations by authorities.
[Creativity and Business, page 8]
App dipanggil dari
app.py def staticChunker(folder_path):
docs = []
print(f"Creating chunks. CHUNK_SIZE: {CHUNK_SIZE}, CHUNK_OVERLAP: {CHUNK_OVERLAP}")
# Loop through all .md files in the folder
for file_name in os.listdir(folder_path):
if file_name.endswith(".md"):
file_path = os.path.join(folder_path, file_name)
print(f"Processing file: {file_path}")
# Load documents from the Markdown file
loader = UnstructuredMarkdownLoader(file_path)
documents = loader.load()
# Add file-specific metadata (optional)
for doc in documents:
doc.metadata["source_file"] = file_name
# Split loaded documents into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
chunked_docs = text_splitter.split_documents(documents)
docs.extend(chunked_docs)
return docs
def load_or_create_vs(persist_directory):
# Check if the vector store directory exists
if os.path.exists(persist_directory):
print("Loading existing vector store...")
# Load the existing vector store
vectorstore = Chroma(
persist_directory=persist_directory,
embedding_function=st.session_state.embed_model,
collection_name=collection_name
)
else:
print("Vector store not found. Creating a new one...n")
docs = staticChunker(DATA_FOLDER)
print("Computing embeddings...")
# Create and persist a new Chroma vector store
vectorstore = Chroma.from_documents(
documents=docs,
embedding=st.session_state.embed_model,
persist_directory=persist_directory,
collection_name=collection_name
)
print('Vector store created and persisted successfully!')
return vectorstore untuk kegunaan dalam antara muka You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
Interface Streamlit
import os
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
# Define parsing instructions
parsing_instructions = """
Extract the text from the document using proper structure.
"""
def save_to_markdown(output_path, content):
"""
Save extracted content to a markdown file.
Parameters:
output_path (str): The path where the markdown file will be saved.
content (list): The extracted content to be saved.
"""
with open(output_path, "w", encoding="utf-8") as md_file:
for document in content:
# Extract the text content from the Document object
md_file.write(document.text + "nn") # Access the 'text' attribute
def extract_document(input_path):
# Initialize the LlamaParse parser
parsing_instructions = """You are given a document containing text, tables, and images. Extract all the contents in their correct format. Extract each table in a correct format and include a detailed explanation of each table before its extracted format.
If an image contains text, extract all the text in the correct format and include a detailed explanation of each image before its extracted text.
Produce the output in markdown text. Extract each page separately in the form of an individual node. Assign the document name and page number to each extracted node in the format: [Creativity and Business, page 7].
Include the document name and page number at the start and end of each extracted page.
"""
parser = LlamaParse(
result_type="markdown",
parsing_instructions=parsing_instructions,
premium_mode=True,
api_key=LLAMA_CLOUD_API_KEY,
verbose=True
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
input_path, file_extractor=file_extractor
).load_data()
return documents
input_path = r"C:Usersh02317Downloadsdocs" # Replace with your document path
output_file = r"C:Usersh02317Downloadsextracted_document.md" # Output markdown file name
# Extract the document
extracted_content = extract_document(input_path)
save_to_markdown(output_file, extracted_content) Berikut adalah gambar antara muka Streamlit:  Imej berikut menunjukkan jawapan yang dihasilkan oleh
Imej berikut menunjukkan jawapan yang dihasilkan oleh  Penjelasan
Penjelasan 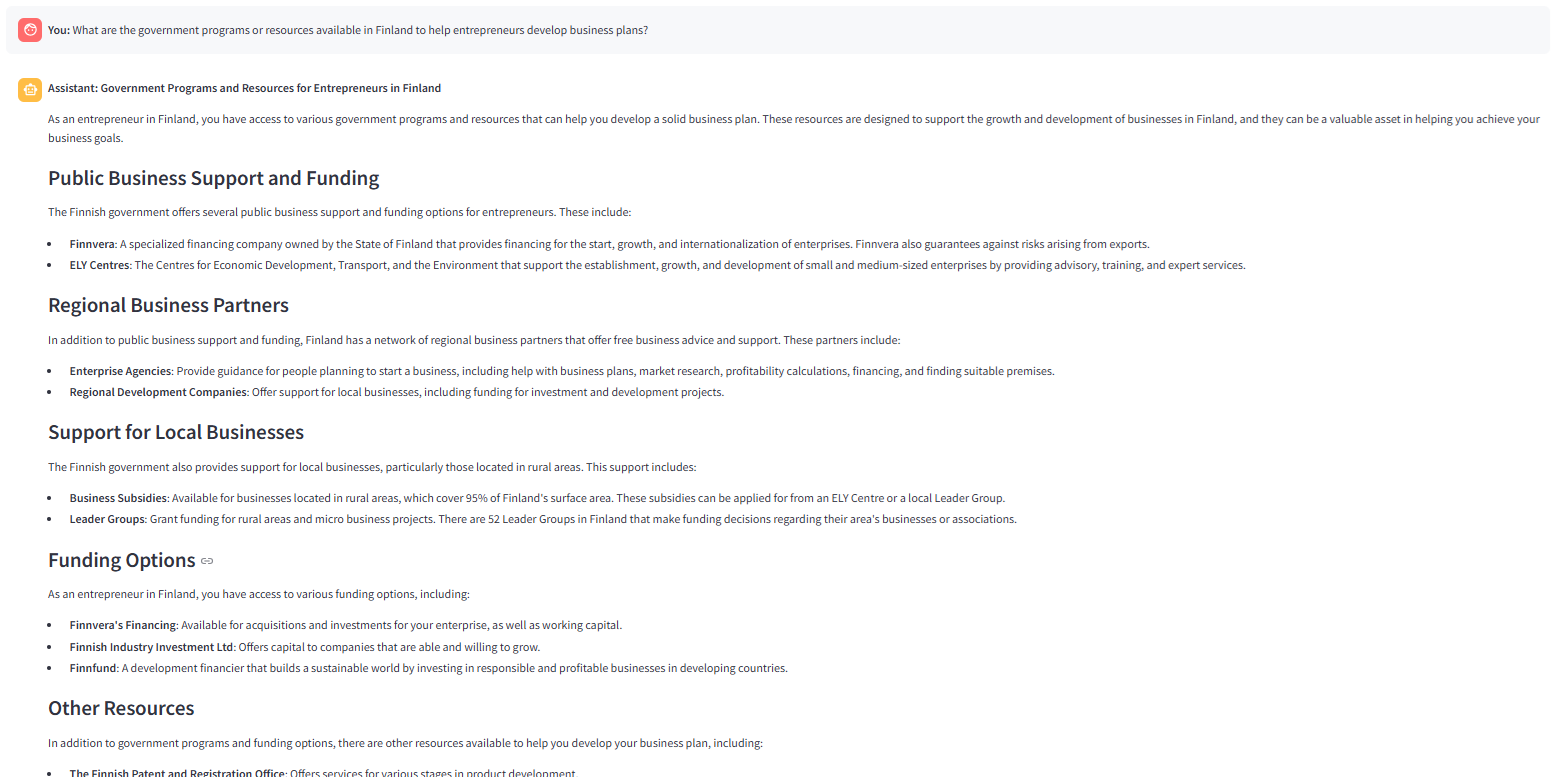 Info
Info 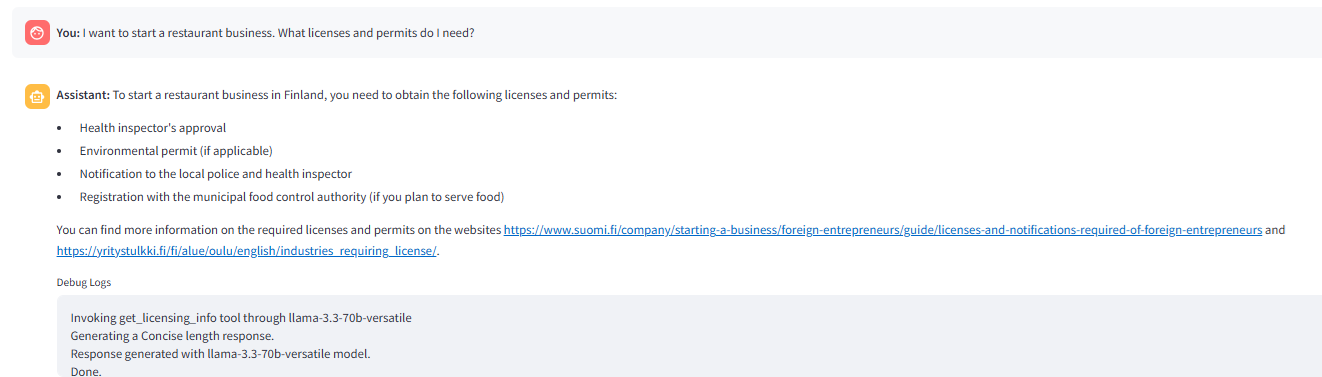 nod apabila tiada bahagian yang relevan ditemui dalam carian vektor.
nod apabila tiada bahagian yang relevan ditemui dalam carian vektor. 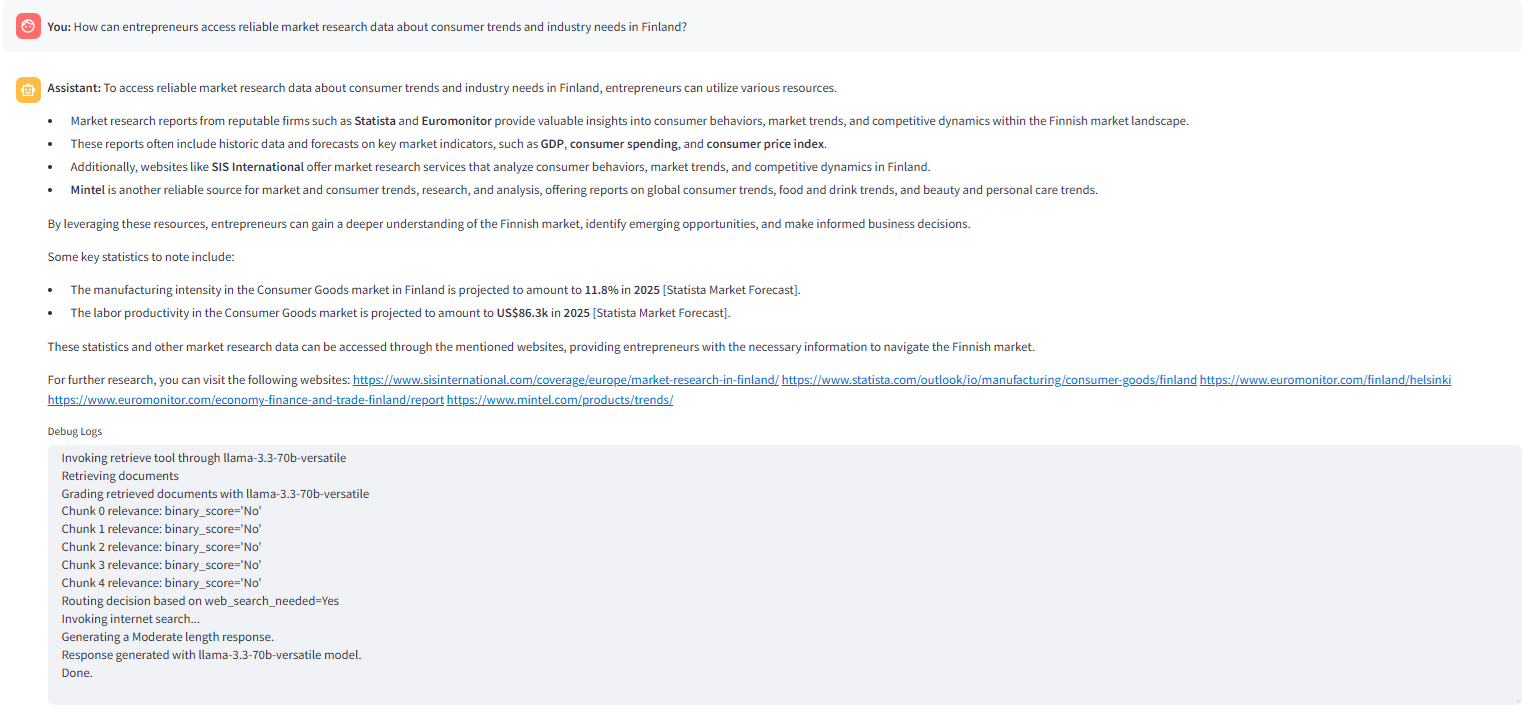 . The _route
. The _route 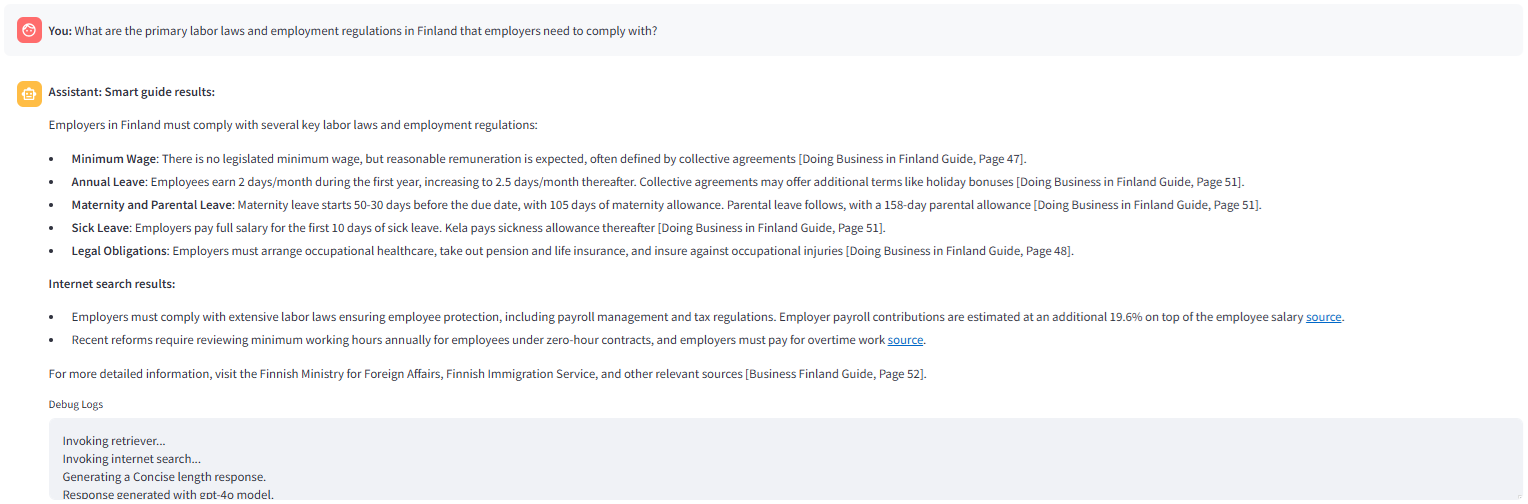
Atas ialah kandungan terperinci Membangunkan panduan pintar berkuasa AI untuk perancangan & keusahawanan perniagaan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI