
Rumah >Peranti teknologi >AI >6 strategi penyesuaian LLM biasa dijelaskan secara ringkas
6 strategi penyesuaian LLM biasa dijelaskan secara ringkas

- 王林asal
- 2025-02-25 16:01:08619semak imbas
Artikel ini meneroka enam strategi utama untuk menyesuaikan model bahasa besar (LLMS), dari teknik mudah hingga kaedah yang lebih intensif sumber. Memilih pendekatan yang betul bergantung kepada keperluan khusus, sumber, dan kepakaran teknikal anda.
Kenapa menyesuaikan llms?
LLM pra-terlatih, sementara yang kuat, sering tidak mencukupi keperluan perniagaan atau domain tertentu. Menyesuaikan LLM membolehkan anda menyesuaikan keupayaannya dengan keperluan tepat anda tanpa kos melatih model dari awal. Ini amat penting untuk pasukan yang lebih kecil yang tidak mempunyai sumber yang luas.
memilih llm yang betul:
Sebelum penyesuaian, memilih model asas yang sesuai adalah kritikal. Faktor yang perlu dipertimbangkan termasuk:
- Model Open-Source vs. Proprietary: model sumber terbuka menawarkan fleksibiliti dan kawalan tetapi menuntut kemahiran teknikal, sementara model proprietari menyediakan kemudahan akses dan prestasi yang sering unggul pada kos.
- Tugas dan Metrik: Model yang berbeza Excel pada pelbagai tugas (menjawab soalan, ringkasan, penjanaan kod). Metrik penanda aras dan ujian khusus domain adalah penting.
- Senibina: model decoder sahaja (seperti GPT) adalah kuat pada penjanaan teks, manakala model pengekod-decoder (seperti T5) lebih sesuai untuk terjemahan. Senibina yang muncul seperti Campuran Pakar (MOE) menunjukkan janji.
- Saiz model: model yang lebih besar biasanya melakukan lebih baik tetapi memerlukan lebih banyak sumber pengiraan.
Strategi Penyesuaian Enam LLM (disenaraikan oleh Intensiti Sumber):
Strategi berikut dibentangkan dalam urutan penggunaan sumber:
1. Kejuruteraan Prompt
2. Strategi penyahkodan dan pensampelan
 Mengawal strategi penyahkodan (carian tamak, carian rasuk, persampelan) dan parameter pensampelan (suhu, top-k, top-p) pada masa kesimpulan membolehkan anda menyesuaikan rawak dan kepelbagaian output LLM. Ini adalah kaedah kos rendah untuk mempengaruhi tingkah laku model.
Mengawal strategi penyahkodan (carian tamak, carian rasuk, persampelan) dan parameter pensampelan (suhu, top-k, top-p) pada masa kesimpulan membolehkan anda menyesuaikan rawak dan kepelbagaian output LLM. Ini adalah kaedah kos rendah untuk mempengaruhi tingkah laku model.
3. Pengambilan Generasi Tambahan (RAG)

4. Sistem berasaskan ejen
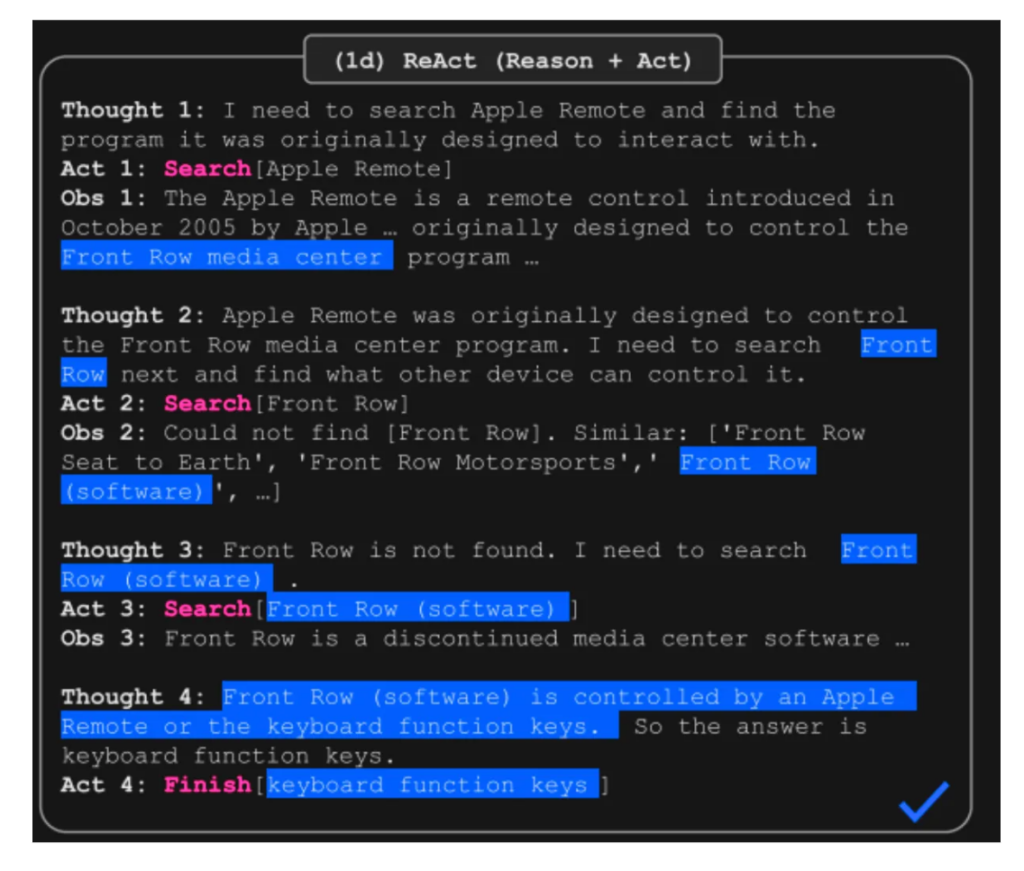
 Sistem berasaskan ejen membolehkan LLMS berinteraksi dengan persekitaran, menggunakan alat, dan mengekalkan memori. Rangka kerja seperti React (sinergizing penalaran dan bertindak) menggabungkan penalaran dengan tindakan dan pemerhatian, meningkatkan prestasi pada tugas -tugas yang kompleks. Ejen menawarkan kelebihan yang signifikan dalam menguruskan aliran kerja kompleks dan penggunaan alat.
Sistem berasaskan ejen membolehkan LLMS berinteraksi dengan persekitaran, menggunakan alat, dan mengekalkan memori. Rangka kerja seperti React (sinergizing penalaran dan bertindak) menggabungkan penalaran dengan tindakan dan pemerhatian, meningkatkan prestasi pada tugas -tugas yang kompleks. Ejen menawarkan kelebihan yang signifikan dalam menguruskan aliran kerja kompleks dan penggunaan alat.
 5. Fine-penalaan
5. Fine-penalaan
Penalaan halus melibatkan mengemas kini parameter LLM menggunakan dataset tersuai. Kaedah penalaan halus (PEFT) parameter seperti LORA dengan ketara mengurangkan kos pengiraan berbanding dengan penalaan halus penuh. Pendekatan ini memerlukan lebih banyak sumber daripada kaedah sebelumnya tetapi memberikan keuntungan prestasi yang lebih besar. 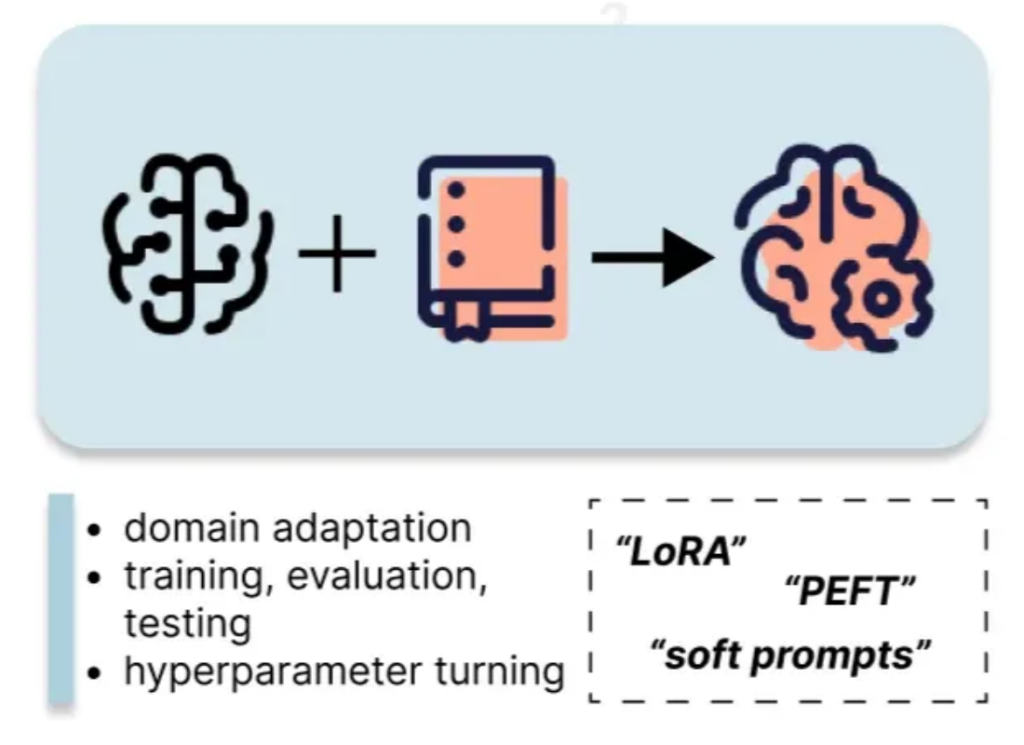
Gambaran keseluruhan ini memberikan pemahaman yang komprehensif mengenai pelbagai teknik penyesuaian LLM, membolehkan anda memilih strategi yang paling sesuai berdasarkan keperluan dan sumber khusus anda. Ingatlah untuk mempertimbangkan perdagangan antara penggunaan sumber dan keuntungan prestasi semasa membuat pilihan anda. 
Atas ialah kandungan terperinci 6 strategi penyesuaian LLM biasa dijelaskan secara ringkas. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI