
Rumah >pembangunan bahagian belakang >Tutorial Python >Membina Saluran Paip Statistik NBA dengan AWS, Python dan DynamoDB
Membina Saluran Paip Statistik NBA dengan AWS, Python dan DynamoDB

- Mary-Kate Olsenasal
- 2025-01-21 22:14:20484semak imbas
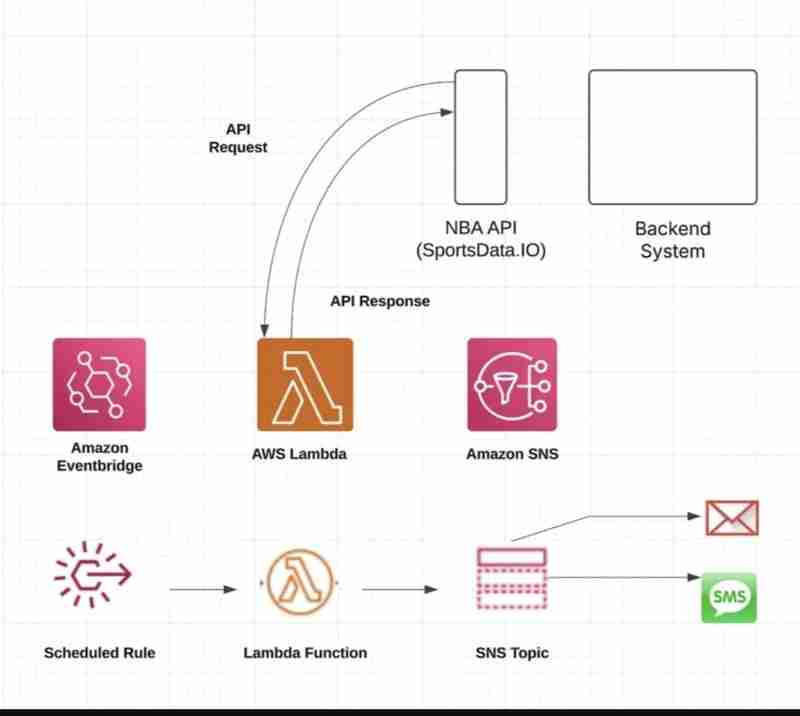
Tutorial ini memperincikan penciptaan saluran paip data statistik NBA automatik menggunakan perkhidmatan AWS, Python dan DynamoDB. Sama ada anda seorang peminat data sukan atau pelajar AWS, projek praktikal ini memberikan pengalaman berharga dalam pemprosesan data dunia sebenar.
Gambaran Keseluruhan Projek
Saluran paip ini secara automatik mendapatkan semula statistik NBA daripada SportsData API, memproses data dan menyimpannya dalam DynamoDB. Perkhidmatan AWS yang digunakan termasuk:
- DynamoDB: Storan data
- Lambda: Pelaksanaan tanpa pelayan
- CloudWatch: Pemantauan dan pengelogan
Prasyarat
Sebelum bermula, pastikan anda mempunyai:
- Kemahiran asas Python
- Akaun AWS
- AWS CLI dipasang dan dikonfigurasikan
- Kunci API SportsData
Persediaan Projek
Klon repositori dan pasang kebergantungan:
<code class="language-bash">git clone https://github.com/nolunchbreaks/nba-stats-pipeline.git cd nba-stats-pipeline pip install -r requirements.txt</code>
Konfigurasi Persekitaran
Buat fail .env dalam akar projek dengan pembolehubah ini:
<code>SPORTDATA_API_KEY=your_api_key_here AWS_REGION=us-east-1 DYNAMODB_TABLE_NAME=nba-player-stats</code>
Struktur Projek
Struktur direktori projek adalah seperti berikut:
<code>nba-stats-pipeline/ ├── src/ │ ├── __init__.py │ ├── nba_stats.py │ └── lambda_function.py ├── tests/ ├── requirements.txt ├── README.md └── .env</code>
Storan dan Struktur Data
Skema DynamoDB
Jalur paip menyimpan statistik pasukan NBA dalam DynamoDB menggunakan skema ini:
- Kunci Pembahagian: ID Pasukan
- Kunci Isih: Cap masa
- Atribut: Statistik pasukan (menang/kalah, mata setiap perlawanan, kedudukan persidangan, kedudukan bahagian, metrik sejarah)
Infrastruktur AWS

Tatarajah Jadual DynamoDB
Konfigurasikan jadual DynamoDB seperti berikut:
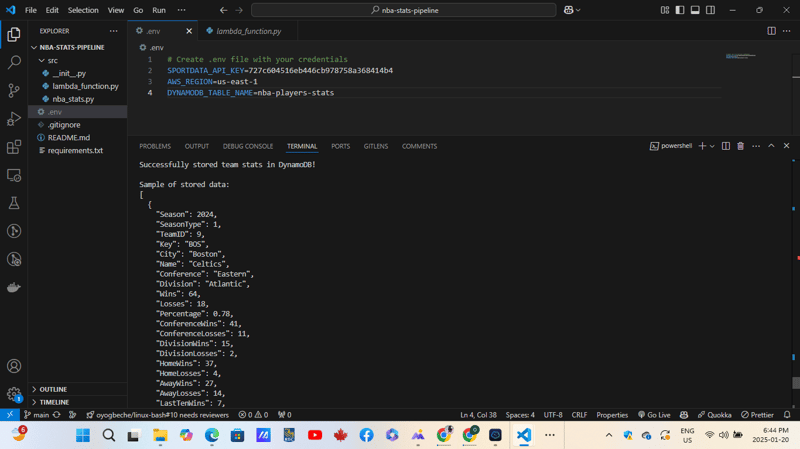
- Nama Jadual:
nba-player-stats - Kunci Utama:
TeamID(String) - Kunci Isih:
Timestamp(Nombor) - Kapasiti yang Diperuntukkan: Laraskan mengikut keperluan
Konfigurasi Fungsi Lambda (jika menggunakan Lambda)
- Masa Jalanan: Python 3.9
- Memori: 256MB
- Tamat masa: 30 saat
- Pengendali:
lambda_function.lambda_handler
Ralat Pengendalian dan Pemantauan
Saluran paip termasuk pengendalian ralat yang mantap untuk kegagalan API, pendikitan DynamoDB, isu transformasi data dan respons API tidak sah. CloudWatch merekodkan semua acara dalam JSON berstruktur untuk pemantauan prestasi, penyahpepijatan dan memastikan pemprosesan data berjaya.
Pembersihan Sumber
Selepas menyelesaikan projek, bersihkan sumber AWS:
<code class="language-bash">git clone https://github.com/nolunchbreaks/nba-stats-pipeline.git cd nba-stats-pipeline pip install -r requirements.txt</code>
Pengambilan Utama
Projek ini diserlahkan:
- Penyatuan Perkhidmatan AWS: Penggunaan berkesan berbilang perkhidmatan AWS untuk saluran paip data yang padu.
- Pengendalian Ralat: Kepentingan pengendalian ralat yang menyeluruh dalam persekitaran pengeluaran.
- Pemantauan: Peranan penting pengelogan dan pemantauan dalam menyelenggara saluran paip data.
- Pengurusan Kos: Kesedaran tentang penggunaan dan pembersihan sumber AWS.
Peningkatan Masa Depan
Pelanjutan projek yang mungkin termasuk:
- Penyepaduan perangkaan permainan masa nyata
- Pelaksanaan visualisasi data
- Titik akhir API untuk akses data
- Keupayaan analisis data lanjutan
Kesimpulan
Saluran paip statistik NBA ini menunjukkan kuasa menggabungkan perkhidmatan AWS dan Python untuk membina saluran paip data berfungsi. Ia merupakan sumber yang berharga untuk mereka yang berminat dalam analisis sukan atau pemprosesan data AWS. Kongsi pengalaman dan cadangan anda untuk penambahbaikan!
Ikuti untuk lebih banyak tutorial AWS dan Python! Menghargai ❤️ dan ? jika anda mendapati ini membantu!
Atas ialah kandungan terperinci Membina Saluran Paip Statistik NBA dengan AWS, Python dan DynamoDB. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!