

 pembangunan bahagian belakangTutorial PythonAnalisis Perbandingan Teknik Pengelasan: Teluk Naif, Pokok Keputusan, dan Hutan Rawak
pembangunan bahagian belakangTutorial PythonAnalisis Perbandingan Teknik Pengelasan: Teluk Naif, Pokok Keputusan, dan Hutan RawakAnalisis Perbandingan Teknik Pengelasan: Teluk Naif, Pokok Keputusan, dan Hutan Rawak

Membuka Rahsia Dinosaur dengan Pembelajaran Mesin: Perbandingan Model
Pembelajaran mesin memperkasakan kami untuk mencungkil corak tersembunyi dalam data, yang membawa kepada ramalan dan penyelesaian yang bernas untuk masalah dunia sebenar. Mari kita terokai kuasa ini dengan menerapkannya pada dunia dinosaur yang menarik! Artikel ini membandingkan tiga model pembelajaran mesin yang popular—Naive Bayes, Decision Trees dan Random Forests—semasa mereka menangani set data dinosaur yang unik. Kami akan melalui penerokaan data, penyediaan dan penilaian model, menyerlahkan prestasi setiap model dan cerapan yang diperoleh.
-
Set Data Dinosaur: Harta Karun Prasejarah
Data data kami ialah koleksi maklumat dinosaur yang kaya, termasuk diet, tempoh geologi, lokasi dan saiz. Setiap entri mewakili dinosaur yang unik, menyediakan gabungan data kategori dan berangka yang matang untuk dianalisis.

Atribut Utama:
- nama: Spesies dinosaur (kategori).
- pemakanan: Tabiat pemakanan (cth., herbivor, karnivor).
- tempoh: Tempoh kewujudan geologi.
- tinggal_di: Wilayah geografi yang didiami.
- panjang: Anggaran saiz (berangka).
- taksonomi: Pengelasan taksonomi.
Sumber Set Data: Taman Jurassic - Set Data Dinosaur yang Lengkap
-
Penyediaan dan Penerokaan Data: Membongkar Trend Prasejarah
2.1 Gambaran Keseluruhan Set Data:
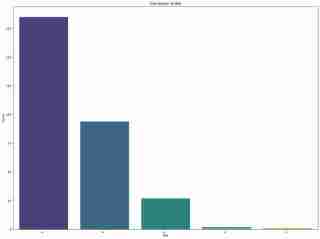
Analisis awal kami mendedahkan ketidakseimbangan kelas, dengan herbivora dengan ketara mengatasi jenis diet lain. Ketidakseimbangan ini menimbulkan cabaran, terutamanya untuk model Naive Bayes, yang menganggap perwakilan kelas yang sama.
2.2 Pembersihan Data:
Untuk memastikan kualiti data, kami melakukan perkara berikut:
- Imputasi nilai yang hilang menggunakan kaedah statistik yang sesuai.
- Pengenalpastian dan pengurusan outlier dalam atribut berangka seperti 'panjang'.
2.3 Analisis Data Penerokaan (EDA):
EDA mendedahkan corak dan korelasi yang menarik:
- Dinosaur herbivor adalah lebih biasa semasa tempoh Jurassic.
- Variasi saiz yang ketara wujud merentas spesies yang berbeza, seperti yang ditunjukkan dalam atribut 'panjang'.
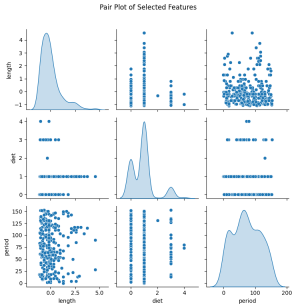
-
Kejuruteraan Ciri: Menapis Data untuk Prestasi Optimum
Untuk meningkatkan ketepatan model, kami menggunakan teknik kejuruteraan ciri:
- Penskalaan dan Normalisasi: Ciri berangka piawai (seperti 'panjang') untuk input model yang konsisten.
- Pemilihan Ciri: Atribut berpengaruh yang diutamakan seperti 'diet', 'taksonomi' dan 'tempoh' untuk memfokuskan pada data yang paling berkaitan.
-
Latihan Model dan Perbandingan Prestasi: Perlawanan Prasejarah
Objektif utama kami adalah untuk membandingkan prestasi tiga model pada set data dinosaur.
4.1 Naif Bayes:
Model kebarangkalian ini menganggap kebebasan ciri. Kesederhanaannya menjadikannya cekap dari segi pengiraan, tetapi prestasinya terjejas disebabkan ketidakseimbangan kelas set data, menyebabkan ramalan yang kurang tepat untuk kelas yang kurang diwakili.
4.2 Pokok Keputusan:
Pokok Keputusan cemerlang dalam menangkap perhubungan bukan linear melalui percabangan hierarki. Ia berprestasi lebih baik daripada Naive Bayes, mengenal pasti corak kompleks dengan berkesan. Walau bagaimanapun, ia menunjukkan kecenderungan kepada pemasangan berlebihan jika kedalaman pokok tidak dikawal dengan teliti.
4.3 Hutan Rawak:
Kaedah ensemble ini, menggabungkan berbilang Pokok Keputusan, terbukti paling teguh. Dengan mengagregatkan ramalan, ia meminimumkan pemasangan berlebihan dan mengendalikan kerumitan set data dengan berkesan, mencapai ketepatan tertinggi.
-
Keputusan dan Analisis: Mentafsir Penemuan
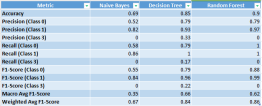
Penemuan Utama:
- Random Forest mencapai ketepatan unggul dan prestasi seimbang merentas semua metrik, menunjukkan kekuatannya dalam mengendalikan interaksi data yang kompleks.
- Pokok Keputusan menunjukkan prestasi yang munasabah tetapi ketinggalan sedikit di belakang Random Forest dalam ketepatan ramalan.
- Naive Bayes bergelut dengan data yang tidak seimbang, yang membawa kepada ketepatan dan ingatan yang lebih rendah.
Cabaran dan Penambahbaikan Masa Depan:
- Mengatasi ketidakseimbangan kelas menggunakan teknik seperti SMOTE atau pensampelan semula boleh meningkatkan prestasi model untuk jenis dinosaur yang kurang diwakili.
- Penalaan hiperparameter untuk Pokok Keputusan dan Hutan Rawak boleh memperhalusi ketepatan lagi.
- Meneroka kaedah ensemble alternatif, seperti meningkatkan, mungkin memberikan cerapan tambahan.

Kesimpulan: Perjalanan Melalui Masa dan Sains Data
Analisis perbandingan ini menunjukkan prestasi model pembelajaran mesin yang berbeza-beza pada set data dinosaur yang unik. Proses itu, daripada penyediaan data hingga penilaian model, mendedahkan kekuatan dan batasan setiap satu:
- Naive Bayes: Mudah dan pantas, tetapi sensitif kepada ketidakseimbangan kelas.
- Pokok Keputusan: Boleh ditafsir dan intuitif, tetapi terdedah kepada pemasangan berlebihan.
- Hutan Rawak: Yang paling tepat dan teguh, menonjolkan kuasa pembelajaran ensembel.
Random Forest muncul sebagai model yang paling boleh dipercayai untuk set data ini. Penyelidikan masa depan akan meneroka teknik lanjutan seperti meningkatkan dan memperhalusi ciri kejuruteraan untuk meningkatkan lagi ketepatan ramalan.
Selamat pengekodan! ?
Untuk butiran lanjut, lawati repositori GitHub saya.
Atas ialah kandungan terperinci Analisis Perbandingan Teknik Pengelasan: Teluk Naif, Pokok Keputusan, dan Hutan Rawak. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Apakah beberapa operasi biasa yang boleh dilakukan pada tatasusunan python?Apr 26, 2025 am 12:22 AM
Apakah beberapa operasi biasa yang boleh dilakukan pada tatasusunan python?Apr 26, 2025 am 12:22 AMPythonArraysSupportVariousoperations: 1) SlicingExtractsSubsets, 2) Menambah/ExtendingAddSelements, 3) InsertingPlaceSelementSatSatSatSpecifics, 4) RemovingDeleteselements, 5) Sorting/ReversingChangesOrder,
 Dalam jenis aplikasi yang biasa digunakan oleh numpy?Apr 26, 2025 am 12:13 AM
Dalam jenis aplikasi yang biasa digunakan oleh numpy?Apr 26, 2025 am 12:13 AMNumpyarraysareessentialforapplicationRequiringeficientnumericalcomputationsanddatamanipulation.theyarecrucialindaSascience, machinelearning, fizik, kejuruteraan, danfinanceduetotheirabilitytOHandlelarge-Scaledataefisien.Forexample, infinancialanal
 Bilakah anda memilih untuk menggunakan array di atas senarai di Python?Apr 26, 2025 am 12:12 AM
Bilakah anda memilih untuk menggunakan array di atas senarai di Python?Apr 26, 2025 am 12:12 AMUseanArray.arrayoveralistinpythonwhendealingwithhomogeneousdata, criticalcode prestasi, orinterfacingwithccode.1) homogeneousdata: arrayssavemememorywithtypedelements.2)
 Adakah semua operasi senarai disokong oleh tatasusunan, dan sebaliknya? Mengapa atau mengapa tidak?Apr 26, 2025 am 12:05 AM
Adakah semua operasi senarai disokong oleh tatasusunan, dan sebaliknya? Mengapa atau mengapa tidak?Apr 26, 2025 am 12:05 AMTidak, notalllistoperationsaresuportedByArrays, andviceversa.1) arraysdonotsupportdynamicoperationslikeappendorinsertwithoutresizing, whyimpactsperformance.2) listsdonotguaranteeconstantTimeComplexityFordirectacesscesscesscesscesscesscesscesscesscesessd.
 Bagaimana anda mengakses elemen dalam senarai python?Apr 26, 2025 am 12:03 AM
Bagaimana anda mengakses elemen dalam senarai python?Apr 26, 2025 am 12:03 AMToaccesselementsinaPythonlist,useindexing,negativeindexing,slicing,oriteration.1)Indexingstartsat0.2)Negativeindexingaccessesfromtheend.3)Slicingextractsportions.4)Iterationusesforloopsorenumerate.AlwayschecklistlengthtoavoidIndexError.
 Bagaimana tatasusunan digunakan dalam pengkomputeran saintifik dengan python?Apr 25, 2025 am 12:28 AM
Bagaimana tatasusunan digunakan dalam pengkomputeran saintifik dengan python?Apr 25, 2025 am 12:28 AMArraysinpython, terutamanya yang, arecrucialinscientificificputingputingfortheirefficiencyandversatility.1) mereka yang digunakan untuk
 Bagaimana anda mengendalikan versi python yang berbeza pada sistem yang sama?Apr 25, 2025 am 12:24 AM
Bagaimana anda mengendalikan versi python yang berbeza pada sistem yang sama?Apr 25, 2025 am 12:24 AMAnda boleh menguruskan versi python yang berbeza dengan menggunakan Pyenv, Venv dan Anaconda. 1) Gunakan pyenv untuk menguruskan pelbagai versi python: Pasang pyenv, tetapkan versi global dan tempatan. 2) Gunakan VENV untuk mewujudkan persekitaran maya untuk mengasingkan kebergantungan projek. 3) Gunakan Anaconda untuk menguruskan versi python dalam projek sains data anda. 4) Simpan sistem python untuk tugas peringkat sistem. Melalui alat dan strategi ini, anda dapat menguruskan versi Python yang berbeza untuk memastikan projek yang lancar.
 Apakah beberapa kelebihan menggunakan array numpy melalui array python standard?Apr 25, 2025 am 12:21 AM
Apakah beberapa kelebihan menggunakan array numpy melalui array python standard?Apr 25, 2025 am 12:21 AMNumpyarrayshaveseveraladvantagesoverstanderardpythonarrays: 1) thearemuchfasterduetoc-assedimplementation, 2) thearemorememory-efficient, antyedlargedataSets, and3) theyofferoptimized, vectorizedfuncionsformathhematicalicalicalicialisation


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Dreamweaver Mac版
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

