


Saya baru-baru ini cuba melaksanakan Agen Catur berasaskan DQN.
Sekarang, sesiapa yang mengetahui cara DQN dan Catur berfungsi akan memberitahu anda bahawa idea yang bodoh.
Dan...itu, tetapi sebagai seorang pemula saya menikmatinya. Dalam artikel ini saya akan berkongsi pandangan yang saya pelajari semasa mengerjakan perkara ini.
Memahami Alam Sekitar.
Sebelum saya mula melaksanakan Ejen itu sendiri, saya perlu membiasakan diri dengan persekitaran yang akan saya gunakan dan membuat pembungkus tersuai di atasnya supaya ia boleh berinteraksi dengan Ejen semasa latihan.
-
Saya menggunakan persekitaran catur daripada perpustakaan kaggle_environments.
from kaggle_environments import make env = make("chess", debug=True)
-
Saya juga menggunakan Chessnut, iaitu perpustakaan ular sawa ringan yang membantu menghurai dan mengesahkan permainan catur.
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
Dalam persekitaran ini, keadaan papan disimpan dalam format FEN.

Ia menyediakan cara yang padat untuk mewakili semua bahagian pada papan dan pemain yang sedang aktif. Walau bagaimanapun, memandangkan saya merancang untuk menyalurkan input kepada rangkaian saraf, saya terpaksa mengubah suai perwakilan keadaan.
Menukar format FEN kepada Matriks
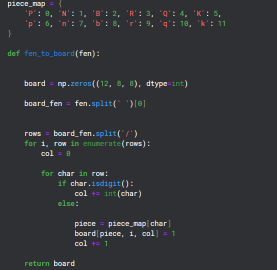
Memandangkan terdapat 12 jenis kepingan yang berbeza pada papan, saya mencipta 12 saluran grid 8x8 untuk mewakili keadaan setiap jenis tersebut pada papan.
Mencipta Pembungkus untuk Alam Sekitar
class EnvCust:
def __init__(self):
self.env = make("chess", debug=True)
self.game=Game(env.state[0]['observation']['board'])
print(self.env.state[0]['observation']['board'])
self.action_space=game.get_moves();
self.obs_space=(self.env.state[0]['observation']['board'])
def get_action(self):
return Game(self.env.state[0]['observation']['board']).get_moves();
def get_obs_space(self):
return fen_to_board(self.env.state[0]['observation']['board'])
def step(self,action):
reward=0
g=Game(self.env.state[0]['observation']['board']);
if(g.board.get_piece(Game.xy2i(action[2:4]))=='q'):
reward=7
elif g.board.get_piece(Game.xy2i(action[2:4]))=='n' or g.board.get_piece(Game.xy2i(action[2:4]))=='b' or g.board.get_piece(Game.xy2i(action[2:4]))=='r':
reward=4
elif g.board.get_piece(Game.xy2i(action[2:4]))=='P':
reward=2
g=Game(self.env.state[0]['observation']['board']);
g.apply_move(action)
done=False
if(g.status==2):
done=True
reward=10
elif g.status == 1:
done = True
reward = -5
self.env.step([action,'None'])
self.action_space=list(self.get_action())
if(self.action_space==[]):
done=True
else:
self.env.step(['None',random.choice(self.action_space)])
g=Game(self.env.state[0]['observation']['board']);
if g.status==2:
reward=-10
done=True
self.action_space=list(self.get_action())
return self.env.state[0]['observation']['board'],reward,done
Tujuan pembungkus ini adalah untuk menyediakan polisi ganjaran untuk ejen dan fungsi langkah yang digunakan untuk berinteraksi dengan persekitaran semasa latihan.
Chessnut berguna dalam mendapatkan maklumat seperti langkah undang-undang yang mungkin berlaku pada keadaan semasa lembaga dan juga untuk mengenali Checkmate semasa permainan.
Saya cuba mencipta dasar ganjaran untuk memberikan mata positif kepada rakan semakan dan mengeluarkan kepingan musuh manakala mata negatif kerana kalah dalam permainan.
Mencipta Penampan Replay
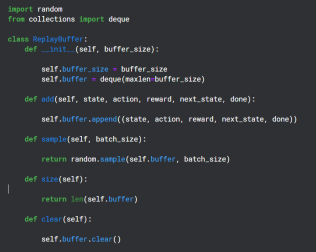
Penimbal Replay digunakan semasa tempoh latihan untuk menyimpan output (keadaan, tindakan, ganjaran, keadaan seterusnya) oleh Rangkaian Q dan kemudiannya digunakan secara rawak untuk penyebaran balik Rangkaian Sasaran
Fungsi Bantu
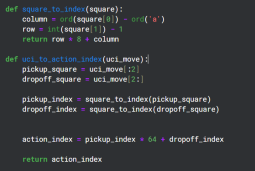

Chessnut mengembalikan tindakan undang-undang dalam format UCI yang kelihatan seperti 'a2a3', namun untuk berinteraksi dengan Rangkaian Neural saya menukar setiap tindakan kepada indeks yang berbeza menggunakan corak asas. Terdapat sejumlah 64 Petak, jadi saya memutuskan untuk mempunyai 64*64 indeks unik untuk setiap pergerakan.
Saya tahu bahawa tidak semua langkah 64*64 adalah sah, tetapi saya boleh mengendalikan kesahihan menggunakan Chessnut dan coraknya cukup mudah.
Struktur Rangkaian Neural
from kaggle_environments import make
env = make("chess", debug=True)
Rangkaian Neural ini menggunakan Lapisan Konvolusi untuk mengambil masukan 12 saluran dan juga menggunakan indeks tindakan yang sah untuk menapis ramalan output ganjaran.
Melaksanakan Ejen
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
Ini jelas merupakan model yang sangat asas yang tidak mempunyai peluang untuk benar-benar berprestasi baik (Dan ia tidak), tetapi ia membantu saya memahami cara DQN berfungsi dengan lebih baik sedikit.

Atas ialah kandungan terperinci Membina Agen Catur menggunakan DQN. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Menyenaraikan senarai di Python: Memilih kaedah yang betulMay 14, 2025 am 12:11 AM
Menyenaraikan senarai di Python: Memilih kaedah yang betulMay 14, 2025 am 12:11 AMTomergelistsinpython, operator youCanusethe, extendmethod, listcomprehension, oritertools.chain, eachwithspecificadvantages: 1) operatorSimpleButlessefficientficorlargelists;
 Bagaimana untuk menggabungkan dua senarai dalam Python 3?May 14, 2025 am 12:09 AM
Bagaimana untuk menggabungkan dua senarai dalam Python 3?May 14, 2025 am 12:09 AMDalam Python 3, dua senarai boleh disambungkan melalui pelbagai kaedah: 1) Pengendali penggunaan, yang sesuai untuk senarai kecil, tetapi tidak cekap untuk senarai besar; 2) Gunakan kaedah Extend, yang sesuai untuk senarai besar, dengan kecekapan memori yang tinggi, tetapi akan mengubah suai senarai asal; 3) menggunakan * pengendali, yang sesuai untuk menggabungkan pelbagai senarai, tanpa mengubah suai senarai asal; 4) Gunakan itertools.chain, yang sesuai untuk set data yang besar, dengan kecekapan memori yang tinggi.
 Rentetan senarai concatenate pythonMay 14, 2025 am 12:08 AM
Rentetan senarai concatenate pythonMay 14, 2025 am 12:08 AMMenggunakan kaedah Join () adalah cara yang paling berkesan untuk menyambungkan rentetan dari senarai di Python. 1) Gunakan kaedah Join () untuk menjadi cekap dan mudah dibaca. 2) Kitaran menggunakan pengendali tidak cekap untuk senarai besar. 3) Gabungan pemahaman senarai dan menyertai () sesuai untuk senario yang memerlukan penukaran. 4) Kaedah mengurangkan () sesuai untuk jenis pengurangan lain, tetapi tidak cekap untuk penyambungan rentetan. Kalimat lengkap berakhir.
 Pelaksanaan Python, apa itu?May 14, 2025 am 12:06 AM
Pelaksanaan Python, apa itu?May 14, 2025 am 12:06 AMPythonexecutionistheprocessoftransformingpythoncodeIntoExecutableInstructions.1) TheinterpreterreadsTheCode, convertingIntoByteCode, yang mana -mana
 Python: Apakah ciri -ciri utamaMay 14, 2025 am 12:02 AM
Python: Apakah ciri -ciri utamaMay 14, 2025 am 12:02 AMCiri -ciri utama Python termasuk: 1. Sintaks adalah ringkas dan mudah difahami, sesuai untuk pemula; 2. Sistem jenis dinamik, meningkatkan kelajuan pembangunan; 3. Perpustakaan standard yang kaya, menyokong pelbagai tugas; 4. Komuniti dan ekosistem yang kuat, memberikan sokongan yang luas; 5. Tafsiran, sesuai untuk skrip dan prototaip cepat; 6. Sokongan multi-paradigma, sesuai untuk pelbagai gaya pengaturcaraan.
 Python: pengkompil atau penterjemah?May 13, 2025 am 12:10 AM
Python: pengkompil atau penterjemah?May 13, 2025 am 12:10 AMPython adalah bahasa yang ditafsirkan, tetapi ia juga termasuk proses penyusunan. 1) Kod python pertama kali disusun ke dalam bytecode. 2) Bytecode ditafsirkan dan dilaksanakan oleh mesin maya Python. 3) Mekanisme hibrid ini menjadikan python fleksibel dan cekap, tetapi tidak secepat bahasa yang disusun sepenuhnya.
 Python untuk gelung vs semasa gelung: Bila menggunakan yang mana?May 13, 2025 am 12:07 AM
Python untuk gelung vs semasa gelung: Bila menggunakan yang mana?May 13, 2025 am 12:07 AMUseAforLoopWheniteratingOvereForforpecificNumbimes; Useaphileloopwhencontinuinguntilaconditionismet.forloopsareidealforknownownsequences, sementara yang tidak digunakan.
 Gelung Python: Kesalahan yang paling biasaMay 13, 2025 am 12:07 AM
Gelung Python: Kesalahan yang paling biasaMay 13, 2025 am 12:07 AMPythonloopscanleadtoerrorslikeinfiniteloops, pengubahsuaianListsduringiteration, off-by-oneerrors, sifar-indexingissues, andnestedloopinefficies.toavoidthese: 1) use'i


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

Dreamweaver Mac版
Alat pembangunan web visual

