


Beli Saya Kopi☕
*Siaran saya menerangkan Caltech 101.
Caltech101() boleh menggunakan dataset Caltech 101 seperti yang ditunjukkan di bawah:
*Memo:
- Argumen pertama ialah root(Required-Type:str or pathlib.Path). *Laluan mutlak atau relatif boleh dilakukan.
- Argumen ke-2 ialah target_type(Optional-Default:"category"-Type:str or tuple or list of str). *"kategori" dan/atau "anotasi" boleh ditetapkan padanya.
- Argumen ke-3 ialah transform(Optional-Default:None-Type:callable).
- Argumen ke-4 ialah target_transform(Optional-Default:None-Type:callable).
- Argumen ke-5 ialah muat turun(Optional-Default:False-Type:bool):
*Memo:
- Jika Benar, set data dimuat turun dari internet dan diekstrak (dibuka zip) ke akar.
- Jika ia Benar dan set data sudah dimuat turun, ia akan diekstrak.
- Jika ia Benar dan set data sudah dimuat turun dan diekstrak, tiada apa yang berlaku.
- Ia sepatutnya Palsu jika set data sudah dimuat turun dan diekstrak kerana ia lebih pantas.
- Anda boleh memuat turun dan mengekstrak set data secara manual (101_ObjectCategories.tar.gz dan Anotasi.tar) dari sini ke data/caltech101/.
- Mengenai kategori indeks imej, Muka(0) ialah 0~434, Mudah_Muka(1) ialah 435~869, Leopards(2 ) ialah 870~1069, Motosikal(3) ialah 1070~1867, akordion(4) ialah 1868~1922, kapal terbang(5) ialah 1923~2722, 🎜>(6) ialah 2723~2764, semut(7) ialah 2765~2806, tong(8) ialah 2807~2853, bass(9) ialah 2854~2907, dll .
from torchvision.datasets import Caltech101
category_data = Caltech101(
root="data"
)
category_data = Caltech101(
root="data",
target_type="category",
transform=None,
target_transform=None,
download=False
)
annotation_data = Caltech101(
root="data",
target_type="annotation"
)
all_data = Caltech101(
root="data",
target_type=["category", "annotation"]
)
len(category_data), len(annotation_data), len(all_data)
# (8677, 8677, 8677)
category_data
# Dataset Caltech101
# Number of datapoints: 8677
# Root location: data\caltech101
# Target type: ['category']
category_data.root
# 'data/caltech101'
category_data.target_type
# ['category']
print(category_data.transform)
# None
print(category_data.target_transform)
# None
category_data.download
# <bound method caltech101.download of dataset caltech101 number datapoints: root location: data target type:>
len(category_data.categories)
# 101
category_data.categories
# ['Faces', 'Faces_easy', 'Leopards', 'Motorbikes', 'accordion',
# 'airplanes', 'anchor', 'ant', 'barrel', 'bass', 'beaver',
# 'binocular', 'bonsai', 'brain', 'brontosaurus', 'buddha',
# 'butterfly', 'camera', 'cannon', 'car_side', 'ceiling_fan',
# 'cellphone', 'chair', 'chandelier', 'cougar_body', 'cougar_face', ...]
len(category_data.annotation_categories)
# 101
category_data.annotation_categories
# ['Faces_2', 'Faces_3', 'Leopards', 'Motorbikes_16', 'accordion',
# 'Airplanes_Side_2', 'anchor', 'ant', 'barrel', 'bass',
# 'beaver', 'binocular', 'bonsai', 'brain', 'brontosaurus',
# 'buddha', 'butterfly', 'camera', 'cannon', 'car_side',
# 'ceiling_fan', 'cellphone', 'chair', 'chandelier', 'cougar_body', ...]
category_data[0]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="510x337">, 0)
category_data[1]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="519x343">, 0)
category_data[2]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="492x325">, 0)
category_data[435]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="290x334">, 1)
category_data[870]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="192x128">, 2)
annotation_data[0]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="510x337">,
# array([[10.00958466, 8.18210863, 8.18210863, 10.92332268, ...],
# [132.30670927, 120.42811502, 103.52396166, 90.73162939, ...]]))
annotation_data[1]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="519x343">,
# array([[15.19298246, 13.71929825, 15.19298246, 19.61403509, ...],
# [121.5877193, 103.90350877, 80.81578947, 64.11403509, ...]]))
annotation_data[2]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="492x325">,
# array([[10.40789474, 7.17807018, 5.79385965, 9.02368421, ...],
# [131.30789474, 120.69561404, 102.23947368, 86.09035088, ...]]))
annotation_data[435]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="290x334">,
# array([[64.52631579, 95.31578947, 123.26315789, 149.31578947, ...],
# [15.42105263, 8.31578947, 10.21052632, 28.21052632, ...]]))
annotation_data[870]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="192x128">,
# array([[2.96536524, 7.55604534, 19.45780856, 33.73992443, ...],
# [23.63413098, 32.13539043, 33.83564232, 8.84193955, ...]]))
all_data[0]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="510x337">,
# (0, array([[10.00958466, 8.18210863, 8.18210863, 10.92332268, ...],
# [132.30670927, 120.42811502, 103.52396166, 90.73162939, ...]]))
all_data[1]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="519x343">,
# (0, array([[15.19298246, 13.71929825, 15.19298246, 19.61403509, ...],
# [121.5877193, 103.90350877, 80.81578947, 64.11403509, ...]]))
all_data[2]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="492x325">,
# (0, array([[10.40789474, 7.17807018, 5.79385965, 9.02368421, ...],
# [131.30789474, 120.69561404, 102.23947368, 86.09035088, ...]]))
all_data[3]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="538x355">,
# (0, array([[19.54035088, 18.57894737, 26.27017544, 38.2877193, ...],
# [131.49122807, 100.24561404, 74.2877193, 49.29122807, ...]]))
all_data[4]
# (<pil.jpegimageplugin.jpegimagefile image mode="RGB" size="528x349">,
# (0, array([[11.87982456, 11.87982456, 13.86578947, 15.35526316, ...],
# [128.34649123, 105.50789474, 91.60614035, 76.71140351, ...]]))
import matplotlib.pyplot as plt
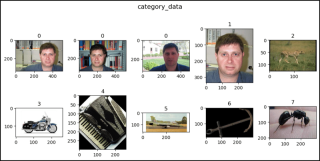
def show_images(data, main_title=None):
plt.figure(figsize=(10, 5))
plt.suptitle(t=main_title, y=1.0, fontsize=14)
ims = (0, 1, 2, 435, 870, 1070, 1868, 1923, 2723, 2765, 2807, 2854)
for i, j in enumerate(ims, start=1):
plt.subplot(2, 5, i)
if len(data.target_type) == 1:
if data.target_type[0] == "category":
im, lab = data[j]
plt.title(label=lab)
elif data.target_type[0] == "annotation":
im, (px, py) = data[j]
plt.scatter(x=px, y=py)
plt.imshow(X=im)
elif len(data.target_type) == 2:
if data.target_type[0] == "category":
im, (lab, (px, py)) = data[j]
elif data.target_type[0] == "annotation":
im, ((px, py), lab) = data[j]
plt.title(label=lab)
plt.imshow(X=im)
plt.scatter(x=px, y=py)
if i == 10:
break
plt.tight_layout()
plt.show()
show_images(data=category_data, main_title="category_data")
show_images(data=annotation_data, main_title="annotation_data")
show_images(data=all_data, main_title="all_data")
</pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></pil.jpegimageplugin.jpegimagefile></bound>


Atas ialah kandungan terperinci Caltech dalam PyTorch. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bagaimanakah pilihan antara senarai dan tatasusunan memberi kesan kepada prestasi keseluruhan aplikasi Python yang berurusan dengan dataset yang besar?May 03, 2025 am 12:11 AM
Bagaimanakah pilihan antara senarai dan tatasusunan memberi kesan kepada prestasi keseluruhan aplikasi Python yang berurusan dengan dataset yang besar?May 03, 2025 am 12:11 AMForhandlinglargedatasetsinpython, usenumpyarraysforbetterperformance.1) numpyarraysarememory-efisien danfasterfornumumerical.2) mengelakkan yang tidak dapat dipertahankan.3)
 Jelaskan bagaimana memori diperuntukkan untuk senarai berbanding tatasusunan dalam Python.May 03, 2025 am 12:10 AM
Jelaskan bagaimana memori diperuntukkan untuk senarai berbanding tatasusunan dalam Python.May 03, 2025 am 12:10 AMInpython, listsusedynamicMemoryAllocationwithover-peruntukan, pemecahan yang tidak dapat dilaksanakan.1) listsallocatemoremoremorythanneedinitial, resizingwhennessary.2) numpyarraysallocateExactMemoreForelements, menawarkanpredictableSabeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeBeat.
 Bagaimana anda menentukan jenis data elemen dalam array python?May 03, 2025 am 12:06 AM
Bagaimana anda menentukan jenis data elemen dalam array python?May 03, 2025 am 12:06 AMInpython, YouCansspectHedatypeyFeleMeremodelerernspant.1) Usenpynernrump.1) usenpynerp.dloatp.ploatm64, formor preciscontrolatatypes.
 Apa itu Numpy, dan mengapa penting untuk pengkomputeran berangka dalam Python?May 03, 2025 am 12:03 AM
Apa itu Numpy, dan mengapa penting untuk pengkomputeran berangka dalam Python?May 03, 2025 am 12:03 AMNumpyisessentialfornumericalcomputinginpythonduetoitsspeed, ingatanefisiensi, dancomprehensivemathematicalfunctions.1) it'sfastbeCauseitperformsoperatiation
 Bincangkan konsep 'peruntukan memori bersebelahan' dan kepentingannya untuk tatasusunan.May 03, 2025 am 12:01 AM
Bincangkan konsep 'peruntukan memori bersebelahan' dan kepentingannya untuk tatasusunan.May 03, 2025 am 12:01 AMContiguousmemoryallocationiscialforarraysbecauseitallowsficientandfastelementaccess.1) itenablesconstantTimeAccess, O (1), duetodirectaddresscalculation.2) itimproveScheFiCiencyBymultmulteLemiSphetfespercacheline.3)
 Bagaimana anda memotong senarai python?May 02, 2025 am 12:14 AM
Bagaimana anda memotong senarai python?May 02, 2025 am 12:14 AMSlicingapythonlistisdoneusingthesyntaxlist [Mula: berhenti: langkah] .here'showitworks: 1) startistheindexofthefirstelementtoinclude.2) stopistheindexofthefirstelementToexclude.3)
 Apakah beberapa operasi biasa yang boleh dilakukan pada array numpy?May 02, 2025 am 12:09 AM
Apakah beberapa operasi biasa yang boleh dilakukan pada array numpy?May 02, 2025 am 12:09 AMNumpyallowsforvariousoperationsonArrays: 1) BasicarithmeticLikeaddition, penolakan, pendaraban, danDivision; 2) Pengerjaan AdvancedSuchasmatrixmultiplication; 3) Element-WiseOperationswithoutExplicitLoops;
 Bagaimana tatasusunan digunakan dalam analisis data dengan python?May 02, 2025 am 12:09 AM
Bagaimana tatasusunan digunakan dalam analisis data dengan python?May 02, 2025 am 12:09 AMArraysinpython, terutamanya yang ada, adalah, penawaran yang ditawarkan.1) numpyarraysenableFandlingoflargedataSetsandClexPleperationsLikemovingAverages.2)


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

