


Gambaran keseluruhan
Saya menulis skrip Python yang menterjemah logik perniagaan pengekstrakan data PDF ke dalam kod yang berfungsi.
Skrip telah diuji pada 71 halaman PDF Penyata Kustodian meliputi tempoh 10 bulan (Jan hingga Okt 2024). Memproses PDF mengambil masa kira-kira 4 saat untuk disiapkan - jauh lebih cepat daripada melakukannya secara manual.

Daripada apa yang saya lihat, output kelihatan betul dan kod itu tidak mengalami sebarang ralat.
Tangkapan gambar bagi tiga output CSV ditunjukkan di bawah. Harap maklum bahawa data sensitif telah dikelabukan.
Snapshot 1: Pegangan Saham
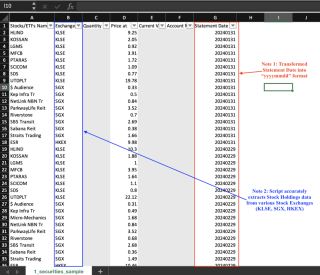
Gambar 2: Pegangan Dana

Gambar 3: Pegangan Tunai

Aliran kerja ini menunjukkan langkah luas yang saya ambil untuk menjana fail CSV.
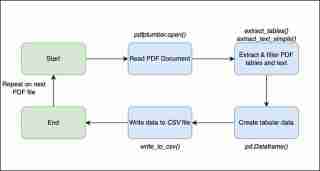
Sekarang, saya akan menghuraikan dengan lebih terperinci cara saya menterjemah logik perniagaan kepada kod dalam Python.
Langkah 1: Baca dokumen PDF
Saya menggunakan fungsi open() pdfplumber.
# Open the PDF file with pdfplumber.open(file_path) as pdf:
file_path ialah pembolehubah yang diisytiharkan yang memberitahu pdfplumber fail yang hendak dibuka.
Langkah 2.0: Ekstrak & tapis jadual daripada setiap halaman
Fungsi extract_tables() melakukan kerja keras mengekstrak semua jadual daripada setiap halaman.
Walaupun saya tidak begitu mahir dengan logik asas, saya rasa fungsi itu melakukan kerja yang cukup baik. Sebagai contoh, dua syot kilat di bawah menunjukkan jadual yang diekstrak berbanding yang asal (daripada PDF)
Snapshot A: Output daripada Terminal Kod VS

Snapshot B: Jadual dalam PDF

Saya kemudiannya perlu melabel secara unik setiap jadual, supaya saya boleh "memilih dan memilih" data daripada jadual tertentu kemudian hari.
Pilihan yang ideal ialah menggunakan tajuk setiap jadual. Walau bagaimanapun, menentukan koordinat tajuk adalah di luar kemampuan saya.
Sebagai penyelesaian, saya mengenal pasti setiap jadual dengan menggabungkan pengepala tiga lajur pertama. Contohnya, jadual Pegangan Saham dalam Snapshot B dilabelkan Saham/ETFsnNameExchangeQuantity.
⚠️Pendekatan ini mempunyai kelemahan yang serius - tiga nama pengepala pertama tidak menjadikan semua jadual cukup unik. Nasib baik, ini hanya memberi kesan kepada jadual yang tidak berkaitan.
Langkah 2.1: Ekstrak, tapis & ubah teks bukan jadual
Nilai khusus yang saya perlukan - Nombor Akaun dan Tarikh Penyata - adalah sub-rentetan dalam Halaman 1 setiap PDF.
Sebagai contoh, "Nombor Akaun M1234567" mengandungi nombor akaun "M1234567".

Saya menggunakan pustaka semula Python dan mendapat ChatGPT untuk mencadangkan ungkapan biasa yang sesuai ("regex"). Regex membahagikan setiap rentetan kepada dua kumpulan, dengan data yang dikehendaki dalam kumpulan kedua.
Regex untuk rentetan Tarikh Penyata dan Nombor Akaun
# Open the PDF file with pdfplumber.open(file_path) as pdf:
Saya seterusnya menukar Tarikh Penyata kepada format "yyyymmdd". Ini memudahkan anda membuat pertanyaan dan mengisih data.
regex_date=r'Statement for \b([A-Za-z]{3}-\d{4})\b'
regex_acc_no=r'Account Number ([A-Za-z]\d{7})'
match_date ialah pembolehubah yang diisytiharkan apabila rentetan yang sepadan dengan regex ditemui.
Langkah 3: Buat data jadual
Ela keras - mengekstrak titik data yang berkaitan - cukup banyak dilakukan pada ketika ini.
Seterusnya, saya menggunakan fungsi DataFrame() panda untuk mencipta data jadual berdasarkan output dalam Langkah 2 dan Langkah 3. Saya juga menggunakan fungsi ini untuk menggugurkan lajur dan baris yang tidak diperlukan.
Hasil akhir kemudiannya boleh ditulis dengan mudah ke CSV atau disimpan dalam pangkalan data.
Langkah 4: Tulis data ke fail CSV
Saya menggunakan fungsi write_to_csv() Python untuk menulis setiap bingkai data ke fail CSV.
if match_date:
# Convert string to a mmm-yyyy date
date_obj=datetime.strptime(match_date.group(1),"%b-%Y")
# Get last day of the month
last_day=calendar.monthrange(date_obj.year,date_obj.month[1]
# Replace day with last day of month
last_day_of_month=date_obj.replace(day=last_day)
statement_date=last_day_of_month.strftime("%Y%m%d")
df_cash_selected ialah rangka data Cash Holdings manakala file_cash_holdings ialah nama fail Cash Holdings CSV.
➡️ Saya akan menulis data ke pangkalan data yang betul setelah saya memperoleh beberapa pengetahuan pangkalan data.
Langkah Seterusnya
Skrip berfungsi kini tersedia untuk mengekstrak data jadual dan teks daripada Penyata Penjaga PDF.
Sebelum saya meneruskan lebih jauh, saya akan menjalankan beberapa ujian untuk melihat sama ada skrip berfungsi seperti yang diharapkan.
--Tamat
Atas ialah kandungan terperinci # | Automatikkan pengekstrakan data PDF: Bina. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Python vs C: Memahami perbezaan utamaApr 21, 2025 am 12:18 AM
Python vs C: Memahami perbezaan utamaApr 21, 2025 am 12:18 AMPython dan C masing -masing mempunyai kelebihan sendiri, dan pilihannya harus berdasarkan keperluan projek. 1) Python sesuai untuk pembangunan pesat dan pemprosesan data kerana sintaks ringkas dan menaip dinamik. 2) C sesuai untuk prestasi tinggi dan pengaturcaraan sistem kerana menaip statik dan pengurusan memori manual.
 Python vs C: Bahasa mana yang harus dipilih untuk projek anda?Apr 21, 2025 am 12:17 AM
Python vs C: Bahasa mana yang harus dipilih untuk projek anda?Apr 21, 2025 am 12:17 AMMemilih Python atau C bergantung kepada keperluan projek: 1) Jika anda memerlukan pembangunan pesat, pemprosesan data dan reka bentuk prototaip, pilih Python; 2) Jika anda memerlukan prestasi tinggi, latensi rendah dan kawalan perkakasan yang rapat, pilih C.
 Mencapai matlamat python anda: kekuatan 2 jam sehariApr 20, 2025 am 12:21 AM
Mencapai matlamat python anda: kekuatan 2 jam sehariApr 20, 2025 am 12:21 AMDengan melabur 2 jam pembelajaran python setiap hari, anda dapat meningkatkan kemahiran pengaturcaraan anda dengan berkesan. 1. Ketahui Pengetahuan Baru: Baca dokumen atau tutorial menonton. 2. Amalan: Tulis kod dan latihan lengkap. 3. Kajian: Menyatukan kandungan yang telah anda pelajari. 4. Amalan Projek: Sapukan apa yang telah anda pelajari dalam projek sebenar. Pelan pembelajaran berstruktur seperti ini dapat membantu anda menguasai Python secara sistematik dan mencapai matlamat kerjaya.
 Memaksimumkan 2 Jam: Strategi Pembelajaran Python BerkesanApr 20, 2025 am 12:20 AM
Memaksimumkan 2 Jam: Strategi Pembelajaran Python BerkesanApr 20, 2025 am 12:20 AMKaedah untuk belajar python dengan cekap dalam masa dua jam termasuk: 1. Semak pengetahuan asas dan pastikan anda sudah biasa dengan pemasangan Python dan sintaks asas; 2. Memahami konsep teras python, seperti pembolehubah, senarai, fungsi, dan lain -lain; 3. Menguasai penggunaan asas dan lanjutan dengan menggunakan contoh; 4. Belajar kesilapan biasa dan teknik debugging; 5. Memohon pengoptimuman prestasi dan amalan terbaik, seperti menggunakan komprehensif senarai dan mengikuti panduan gaya PEP8.
 Memilih antara python dan c: bahasa yang sesuai untuk andaApr 20, 2025 am 12:20 AM
Memilih antara python dan c: bahasa yang sesuai untuk andaApr 20, 2025 am 12:20 AMPython sesuai untuk pemula dan sains data, dan C sesuai untuk pengaturcaraan sistem dan pembangunan permainan. 1. Python adalah mudah dan mudah digunakan, sesuai untuk sains data dan pembangunan web. 2.C menyediakan prestasi dan kawalan yang tinggi, sesuai untuk pembangunan permainan dan pengaturcaraan sistem. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Python vs C: Analisis perbandingan bahasa pengaturcaraanApr 20, 2025 am 12:14 AM
Python vs C: Analisis perbandingan bahasa pengaturcaraanApr 20, 2025 am 12:14 AMPython lebih sesuai untuk sains data dan perkembangan pesat, manakala C lebih sesuai untuk prestasi tinggi dan pengaturcaraan sistem. 1. Sintaks Python adalah ringkas dan mudah dipelajari, sesuai untuk pemprosesan data dan pengkomputeran saintifik. 2.C mempunyai sintaks kompleks tetapi prestasi yang sangat baik dan sering digunakan dalam pembangunan permainan dan pengaturcaraan sistem.
 2 jam sehari: potensi pembelajaran pythonApr 20, 2025 am 12:14 AM
2 jam sehari: potensi pembelajaran pythonApr 20, 2025 am 12:14 AMAdalah mungkin untuk melabur dua jam sehari untuk belajar Python. 1. Belajar Pengetahuan Baru: Ketahui konsep baru dalam satu jam, seperti senarai dan kamus. 2. Amalan dan Amalan: Gunakan satu jam untuk melakukan latihan pengaturcaraan, seperti menulis program kecil. Melalui perancangan dan ketekunan yang munasabah, anda boleh menguasai konsep teras Python dalam masa yang singkat.
 Python vs C: Lengkung pembelajaran dan kemudahan penggunaanApr 19, 2025 am 12:20 AM
Python vs C: Lengkung pembelajaran dan kemudahan penggunaanApr 19, 2025 am 12:20 AMPython lebih mudah dipelajari dan digunakan, manakala C lebih kuat tetapi kompleks. 1. Sintaks Python adalah ringkas dan sesuai untuk pemula. Penaipan dinamik dan pengurusan memori automatik menjadikannya mudah digunakan, tetapi boleh menyebabkan kesilapan runtime. 2.C menyediakan kawalan peringkat rendah dan ciri-ciri canggih, sesuai untuk aplikasi berprestasi tinggi, tetapi mempunyai ambang pembelajaran yang tinggi dan memerlukan memori manual dan pengurusan keselamatan jenis.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

