
 hujung hadapan webtutorial jsMeneroka Siri Kanvas: digabungkan dengan Transformers.js untuk mencapai pemprosesan imej pintar
hujung hadapan webtutorial jsMeneroka Siri Kanvas: digabungkan dengan Transformers.js untuk mencapai pemprosesan imej pintarMeneroka Siri Kanvas: digabungkan dengan Transformers.js untuk mencapai pemprosesan imej pintar

pengenalan
Saya sedang mengekalkan papan lukisan kreatif sumber terbuka yang berkuasa. Papan lukisan ini menyepadukan banyak berus menarik dan fungsi lukisan tambahan, yang membolehkan pengguna mengalami kesan lukisan baharu. Sama ada pada mudah alih atau PC, anda boleh menikmati pengalaman interaktif dan paparan kesan yang lebih baik.
Dalam artikel ini, saya akan menerangkan secara terperinci cara menggabungkan Transformers.js untuk mencapai penyingkiran latar belakang dan segmentasi penandaan imej. Hasilnya adalah seperti berikut

Pautan: https://songlh.top/paint-board/
Github: https://github.com/LHRUN/paint-board Selamat Datang ke Bintang ⭐️
Transformers.js
Transformers.js ialah perpustakaan JavaScript yang berkuasa berdasarkan Transformers Memeluk Wajah yang boleh dijalankan terus dalam penyemak imbas tanpa bergantung pada pengiraan sebelah pelayan. Ini bermakna anda boleh menjalankan model anda secara tempatan, meningkatkan kecekapan dan mengurangkan kos penggunaan dan penyelenggaraan.
Pada masa ini Transformers.js telah menyediakan 1000 model pada Wajah Memeluk, meliputi pelbagai domain, yang boleh memenuhi kebanyakan keperluan anda, seperti pemprosesan imej, penjanaan teks, terjemahan, analisis sentimen dan pemprosesan tugas lain, anda boleh capai dengan mudah melalui Transformers .js. Cari model seperti berikut.
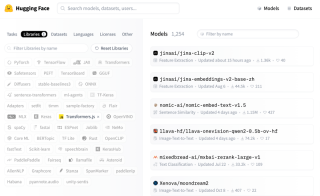
Versi utama semasa Transformers.js telah dikemas kini kepada V3, yang menambahkan banyak ciri hebat, butiran: Transformers.js v3: Sokongan WebGPU, Model & Tugasan Baharu dan Lagi….
Kedua-dua ciri yang saya tambahkan pada siaran ini menggunakan sokongan WebGpu, yang hanya tersedia dalam V3, dan telah meningkatkan kelajuan pemprosesan dengan banyak, dengan penghuraian kini dalam milisaat. Walau bagaimanapun, perlu diingatkan bahawa tidak banyak penyemak imbas yang menyokong WebGPU, jadi disyorkan untuk menggunakan versi terkini Google untuk melawati.
Fungsi 1: Alih keluar latar belakang
Untuk mengalih keluar latar belakang saya menggunakan model Xenova/modnet, yang kelihatan seperti ini
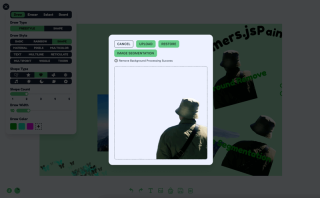
Logik pemprosesan boleh dibahagikan kepada tiga langkah
- mulakan keadaan, dan muatkan model serta pemproses.
- paparan antara muka, ini berdasarkan reka bentuk anda sendiri, bukan pada saya.
- Tunjukkan kesannya, ini berdasarkan rekaan anda sendiri, bukan rekaan saya. Pada masa kini, lebih popular untuk menggunakan garis sempadan untuk memaparkan kesan kontras secara dinamik sebelum dan selepas mengalih keluar latar belakang.
Logik kod adalah seperti berikut, React TS , lihat kod sumber projek saya untuk butiran, kod sumber terletak dalam src/components/boardOperation/uploadImage/index.tsx
import { useState, FC, useRef, useEffect, useMemo } from 'react'
import {
env,
AutoModel,
AutoProcessor,
RawImage,
PreTrainedModel,
Processor
} from '@huggingface/transformers'
const REMOVE_BACKGROUND_STATUS = {
LOADING: 0,
NO_SUPPORT_WEBGPU: 1,
LOAD_ERROR: 2,
LOAD_SUCCESS: 3,
PROCESSING: 4,
PROCESSING_SUCCESS: 5
}
type RemoveBackgroundStatusType =
(typeof REMOVE_BACKGROUND_STATUS)[keyof typeof REMOVE_BACKGROUND_STATUS]
const UploadImage: FC = ({ url }) => {
const [removeBackgroundStatus, setRemoveBackgroundStatus] =
useState<removebackgroundstatustype>()
const [processedImage, setProcessedImage] = useState('')
const modelRef = useRef<pretrainedmodel>()
const processorRef = useRef<processor>()
const removeBackgroundBtnTip = useMemo(() => {
switch (removeBackgroundStatus) {
case REMOVE_BACKGROUND_STATUS.LOADING:
return 'Remove background function loading'
case REMOVE_BACKGROUND_STATUS.NO_SUPPORT_WEBGPU:
return 'WebGPU is not supported in this browser, to use the remove background function, please use the latest version of Google Chrome'
case REMOVE_BACKGROUND_STATUS.LOAD_ERROR:
return 'Remove background function failed to load'
case REMOVE_BACKGROUND_STATUS.LOAD_SUCCESS:
return 'Remove background function loaded successfully'
case REMOVE_BACKGROUND_STATUS.PROCESSING:
return 'Remove Background Processing'
case REMOVE_BACKGROUND_STATUS.PROCESSING_SUCCESS:
return 'Remove Background Processing Success'
default:
return ''
}
}, [removeBackgroundStatus])
useEffect(() => {
;(async () => {
try {
if (removeBackgroundStatus === REMOVE_BACKGROUND_STATUS.LOADING) {
return
}
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOADING)
// Checking WebGPU Support
if (!navigator?.gpu) {
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.NO_SUPPORT_WEBGPU)
return
}
const model_id = 'Xenova/modnet'
if (env.backends.onnx.wasm) {
env.backends.onnx.wasm.proxy = false
}
// Load model and processor
modelRef.current ??= await AutoModel.from_pretrained(model_id, {
device: 'webgpu'
})
processorRef.current ??= await AutoProcessor.from_pretrained(model_id)
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOAD_SUCCESS)
} catch (err) {
console.log('err', err)
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.LOAD_ERROR)
}
})()
}, [])
const processImages = async () => {
const model = modelRef.current
const processor = processorRef.current
if (!model || !processor) {
return
}
setRemoveBackgroundStatus(REMOVE_BACKGROUND_STATUS.PROCESSING)
// load image
const img = await RawImage.fromURL(url)
// Pre-processed image
const { pixel_values } = await processor(img)
// Generate image mask
const { output } = await model({ input: pixel_values })
const maskData = (
await RawImage.fromTensor(output[0].mul(255).to('uint8')).resize(
img.width,
img.height
)
).data
// Create a new canvas
const canvas = document.createElement('canvas')
canvas.width = img.width
canvas.height = img.height
const ctx = canvas.getContext('2d') as CanvasRenderingContext2D
// Draw the original image
ctx.drawImage(img.toCanvas(), 0, 0)
// Updating the mask area
const pixelData = ctx.getImageData(0, 0, img.width, img.height)
for (let i = 0; i
<button classname="{`btn" btn-primary btn-sm remove_background_status.load_success remove_background_status.processing_success undefined : onclick="{processImages}">
Remove background
</button>
<div classname="text-xs text-base-content mt-2 flex">
{removeBackgroundBtnTip}
</div>
<div classname="relative mt-4 border border-base-content border-dashed rounded-lg overflow-hidden">
<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/173262759935552.jpg?x-oss-process=image/resize,p_40" class="lazy" classname="{`w-[50vw]" max-w- h- max-h- object-contain alt="Meneroka Siri Kanvas: digabungkan dengan Transformers.js untuk mencapai pemprosesan imej pintar" >
{processedImage && (
<img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/000/173262759935552.jpg?x-oss-process=image/resize,p_40" class="lazy" classname="{`w-full" h-full absolute top-0 left-0 z- object-contain alt="Meneroka Siri Kanvas: digabungkan dengan Transformers.js untuk mencapai pemprosesan imej pintar" >
)}
</div>
)
}
export default UploadImage
</processor></pretrainedmodel></removebackgroundstatustype>
Fungsi 2: Segmentasi Penanda Imej
Segmentasi penanda imej dilaksanakan menggunakan model seragam Xenova/slimsam-77. Kesannya adalah seperti berikut, anda boleh mengklik pada imej selepas ia dimuatkan, dan pembahagian dijana mengikut koordinat klik anda.
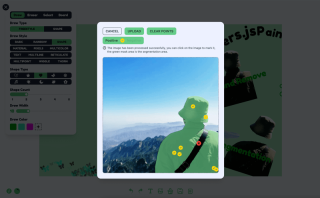
Logik pemprosesan boleh dibahagikan kepada lima langkah
- mulakan keadaan, dan muatkan model serta pemproses
- Dapatkan imej dan muatkannya, kemudian simpan data pemuatan imej dan data benam.
- dengar acara klik imej, rekod data klik, dibahagikan kepada penanda positif dan penanda negatif, selepas setiap klik mengikut data klik dinyahkod untuk menjana data topeng, dan kemudian mengikut data topeng untuk melukis kesan pembahagian .
- Paparan antara muka, ini untuk reka bentuk anda sendiri bermain sewenang-wenangnya, bukan keutamaan saya
- klik untuk menyimpan imej, mengikut data piksel topeng, padankan data imej asal, dan kemudian dieksport melalui lukisan kanvas
Logik kod adalah seperti berikut, React TS , lihat kod sumber projek saya untuk butiran, kod sumber terletak dalam src/components/boardOperation/uploadImage/imageSegmentation.tsx
import { useState, useRef, useEffect, useMemo, MouseEvent, FC } daripada 'react'
import {
SamModel,
AutoProcessor,
RawImage,
PreTrainedModel,
pemproses,
Tensor,
SamImageProcessorResult
} daripada '@huggingface/transformers'
import LoadingIcon daripada '@/components/icons/loading.svg?react'
import PositiveIcon daripada '@/components/icons/boardOperation/image-segmentation-positive.svg?react'
import NegativeIcon daripada '@/components/icons/boardOperation/image-segmentation-negative.svg?react'
antara muka MarkPoint {
kedudukan: nombor[]
label: nombor
}
const SEGMENTATION_STATUS = {
MEMBUAT: 0,
NO_SUPPORT_WEBGPU: 1,
LOAD_ERROR: 2,
LOAD_SUCCESS: 3,
PEMPROSESAN: 4,
MEMPROSES_KEJAYAAN: 5
}
taip SegmentationStatusType =
(jenis SEGMENTATION_STATUS)[kunci jenis SEGMENTATION_STATUS]
const ImageSegmentation: FC = ({ url }) => {
const [markPoints, setMarkPoints] = useState<markpoint>([])
const [Status segmentasi, setStatusSegmentation] =
useState<segmentationstatustype>()
const [pointStatus, setPointStatus] = useState<boolean>(true)
const maskCanvasRef = useRef<htmlcanvaselement>(null) // Topeng pembahagian
const modelRef = useRef<pretrainedmodel>() // model
const processorRef = useRef<processor>() // pemproses
const imageInputRef = useRef<rawimage>() // imej asal
const imageProcessed = useRef<samimageprocessorresult>() // Imej yang diproses
const imageEmbeddings = useRef<tensor>() // Membenamkan data
const segmentationTip = useMemo(() => {
suis (Status pembahagian) {
kes SEGMENTATION_STATUS.LOADING:
kembalikan 'Fungsi Segmentasi Imej Memuatkan'
kes SEGMENTATION_STATUS.NO_SUPPORT_WEBGPU:
kembali 'WebGPU tidak disokong dalam penyemak imbas ini, untuk menggunakan fungsi pembahagian imej, sila gunakan versi terkini Google Chrome.'
kes SEGMENTATION_STATUS.LOAD_ERROR:
kembalikan 'Fungsi Segmentasi Imej gagal dimuatkan'
kes SEGMENTATION_STATUS.LOAD_SUCCESS:
kembalikan 'Fungsi Segmentasi Imej berjaya dimuatkan'
kes SEGMENTATION_STATUS.PROCESSING:
kembalikan 'Pemprosesan Imej...'
kes SEGMENTATION_STATUS.PROCESSING_SUCCESS:
return 'Imej telah berjaya diproses, anda boleh klik pada imej untuk menandakannya, kawasan topeng hijau ialah kawasan segmentasi.'
lalai:
kembalikan ''
}
}, [Status segmentasi])
// 1. model beban dan pemproses
useEffect(() => {
;(async () => {
cuba {
jika (segmentationStatus === SEGMENTATION_STATUS.LOADING) {
kembali
}
setSegmentationStatus(SEGMENTATION_STATUS.LOADING)
jika (!navigator?.gpu) {
setSegmentationStatus(SEGMENTATION_STATUS.NO_SUPPORT_WEBGPU)
kembali
}const model_id = 'Xenova/slimsam-77-uniform'
modelRef.current ??= tunggu SamModel.from_pretrained(model_id, {
dtype: 'fp16', // atau "fp32"
peranti: 'webgpu'
})
processorRef.current ??= tunggu AutoProcessor.from_pretrained(model_id)
setSegmentationStatus(SEGMENTATION_STATUS.LOAD_SUCCESS)
} tangkap (err) {
console.log('err', err)
setSegmentationStatus(SEGMENTATION_STATUS.LOAD_ERROR)
}
})()
}, [])
// 2. proses imej
useEffect(() => {
;(async () => {
cuba {
jika (
!modelRef.current ||
!processorRef.current ||
!url ||
segmentationStatus === SEGMENTATION_STATUS.PROCESSING
) {
kembali
}
setSegmentationStatus(SEGMENTATION_STATUS.PROCESSING)
clearPoints()
imageInputRef.current = menunggu RawImage.fromURL(url)
imageProcessed.current = menunggu processorRef.current(
imageInputRef.current
)
imageEmbeddings.current = menunggu (
modelRef.semasa seperti mana-mana
).get_image_embeddings(imageProcessed.current)
setSegmentationStatus(SEGMENTATION_STATUS.PROCESSING_SUCCESS)
} tangkap (err) {
console.log('err', err)
}
})()
}, [url, modelRef.current, processorRef.current])
// Mengemas kini kesan topeng
function updateMaskOverlay(topeng: RawImage, markah: Float32Array) {
const maskCanvas = maskCanvasRef.current
jika (!maskCanvas) {
kembali
}
const maskContext = maskCanvas.getContext('2d') sebagai CanvasRenderingContext2D
// Kemas kini dimensi kanvas (jika berbeza)
jika (maskCanvas.width !== mask.width || maskCanvas.height !== mask.height) {
maskCanvas.width = mask.width
maskCanvas.height = mask.height
}
// Peruntukkan penimbal untuk data piksel
const imageData = maskContext.createImageData(
maskCanvas.width,
topengKanvas.tinggi
)
// Pilih topeng terbaik
const numMasks = scores.length // 3
biarkan bestIndex = 0
untuk (biar i = 1; i markah[bestIndex]) {
BestIndex = i
}
}
// Isi topeng dengan warna
const pixelData = imageData.data
untuk (biar i = 0; i {
jika (
!modelRef.current ||
!imageEmbeddings.current ||
!processorRef.current ||
!imageProcessed.current
) {
kembali
}// Tiada klik pada data secara langsung mengosongkan kesan pembahagian
jika (!markPoints.length && maskCanvasRef.current) {
const maskContext = maskCanvasRef.current.getContext(
'2h'
) sebagai CanvasRenderingContext2D
maskContext.clearRect(
0,
0,
maskCanvasRef.current.width,
maskCanvasRef.current.height
)
kembali
}
// Sediakan input untuk penyahkodan
const reshaped = imageProcessed.current.reshaped_input_sizes[0]
mata const = markPoints
.map((x) => [x.kedudukan[0] * bentuk semula[1], x.kedudukan[1] * bentuk semula[0]])
.flat(Infiniti)
label const = markPoints.map((x) => BigInt(x.label)).flat(Infinity)
const num_points = markPoints.length
const input_points = Tensor baharu('float32', mata, [1, 1, num_points, 2])
const input_labels = Tensor baharu('int64', labels, [1, 1, num_points])
// Hasilkan topeng
const { pred_masks, iou_scores } = tunggu modelRef.current({
...imageEmbeddings.current,
input_points,
input_labels
})
// Proses pasca topeng
const masks = menunggu (processorRef.current as any).post_process_masks(
pred_masks,
imageProcessed.current.original_sizes,
imageProcessed.current.reshaped_input_sizes
)
updateMaskOverlay(RawImage.fromTensor(topeng[0][0]), iou_scores.data)
}
pengapit const = (x: nombor, min = 0, maks = 1) => {
kembalikan Math.max(Math.min(x, max), min)
}
const clickImage = (e: MouseEvent) => {
jika (Status segmentasi !== STATUS_SEGMENTASI.KEJAYAAN_PROSES) {
kembali
}
const { clientX, clientY, currentTarget } = e
const { kiri, atas } = currentTarget.getBoundingClientRect()
const x = pengapit(
(clientX - left currentTarget.scrollLeft) / currentTarget.scrollWidth
)
const y = pengapit(
(clientY - atas currentTarget.scrollTop) / currentTarget.scrollHeight
)
const existingPointIndex = markPoints.findIndex(
(titik) =>
Matematik.abs(titik.kedudukan[0] - x) {
setMarkPoints([])
nyahkod([])
}
kembali (
<div classname="card shadow-xl overflow-auto">
<div classname="flex items-center gap-x-3">
<button classname="btn btn-primary btn-sm" onclick="{clearPoints}">
Jelas Mata
<butang classname="btn btn-primary btn-sm" onclick="{()"> setPointStatus(benar)}
>
{pointStatus ? 'Positif' : 'Negatif'}
</butang>
</button>
</div>
<div classname="text-xs text-base-content mt-2">{segmentationTip}</div>
<div>
<h2>
Kesimpulan
</h2>
<p>Terima kasih kerana membaca. Ini adalah keseluruhan kandungan artikel ini, saya harap artikel ini berguna kepada anda, dialu-alukan untuk menyukai dan kegemaran. Jika anda mempunyai sebarang pertanyaan, sila berbincang di ruangan komen!</p>
</div>
</div></tensor></samimageprocessorresult></rawimage></processor></pretrainedmodel></htmlcanvaselement></boolean></segmentationstatustype></markpoint>Atas ialah kandungan terperinci Meneroka Siri Kanvas: digabungkan dengan Transformers.js untuk mencapai pemprosesan imej pintar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 JavaScript in Action: Contoh dan projek dunia nyataApr 19, 2025 am 12:13 AM
JavaScript in Action: Contoh dan projek dunia nyataApr 19, 2025 am 12:13 AMAplikasi JavaScript di dunia nyata termasuk pembangunan depan dan back-end. 1) Memaparkan aplikasi front-end dengan membina aplikasi senarai TODO, yang melibatkan operasi DOM dan pemprosesan acara. 2) Membina Restfulapi melalui Node.js dan menyatakan untuk menunjukkan aplikasi back-end.
 JavaScript dan Web: Fungsi teras dan kes penggunaanApr 18, 2025 am 12:19 AM
JavaScript dan Web: Fungsi teras dan kes penggunaanApr 18, 2025 am 12:19 AMPenggunaan utama JavaScript dalam pembangunan web termasuk interaksi klien, pengesahan bentuk dan komunikasi tak segerak. 1) kemas kini kandungan dinamik dan interaksi pengguna melalui operasi DOM; 2) pengesahan pelanggan dijalankan sebelum pengguna mengemukakan data untuk meningkatkan pengalaman pengguna; 3) Komunikasi yang tidak bersesuaian dengan pelayan dicapai melalui teknologi Ajax.
 Memahami Enjin JavaScript: Butiran PelaksanaanApr 17, 2025 am 12:05 AM
Memahami Enjin JavaScript: Butiran PelaksanaanApr 17, 2025 am 12:05 AMMemahami bagaimana enjin JavaScript berfungsi secara dalaman adalah penting kepada pemaju kerana ia membantu menulis kod yang lebih cekap dan memahami kesesakan prestasi dan strategi pengoptimuman. 1) aliran kerja enjin termasuk tiga peringkat: parsing, penyusun dan pelaksanaan; 2) Semasa proses pelaksanaan, enjin akan melakukan pengoptimuman dinamik, seperti cache dalam talian dan kelas tersembunyi; 3) Amalan terbaik termasuk mengelakkan pembolehubah global, mengoptimumkan gelung, menggunakan const dan membiarkan, dan mengelakkan penggunaan penutupan yang berlebihan.
 Python vs JavaScript: Keluk Pembelajaran dan Kemudahan PenggunaanApr 16, 2025 am 12:12 AM
Python vs JavaScript: Keluk Pembelajaran dan Kemudahan PenggunaanApr 16, 2025 am 12:12 AMPython lebih sesuai untuk pemula, dengan lengkung pembelajaran yang lancar dan sintaks ringkas; JavaScript sesuai untuk pembangunan front-end, dengan lengkung pembelajaran yang curam dan sintaks yang fleksibel. 1. Sintaks Python adalah intuitif dan sesuai untuk sains data dan pembangunan back-end. 2. JavaScript adalah fleksibel dan digunakan secara meluas dalam pengaturcaraan depan dan pelayan.
 Python vs JavaScript: Komuniti, Perpustakaan, dan SumberApr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan SumberApr 15, 2025 am 12:16 AMPython dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Dari C/C ke JavaScript: Bagaimana semuanya berfungsiApr 14, 2025 am 12:05 AM
Dari C/C ke JavaScript: Bagaimana semuanya berfungsiApr 14, 2025 am 12:05 AMPeralihan dari C/C ke JavaScript memerlukan menyesuaikan diri dengan menaip dinamik, pengumpulan sampah dan pengaturcaraan asynchronous. 1) C/C adalah bahasa yang ditaip secara statik yang memerlukan pengurusan memori manual, manakala JavaScript ditaip secara dinamik dan pengumpulan sampah diproses secara automatik. 2) C/C perlu dikumpulkan ke dalam kod mesin, manakala JavaScript adalah bahasa yang ditafsirkan. 3) JavaScript memperkenalkan konsep seperti penutupan, rantaian prototaip dan janji, yang meningkatkan keupayaan pengaturcaraan fleksibiliti dan asynchronous.
 Enjin JavaScript: Membandingkan PelaksanaanApr 13, 2025 am 12:05 AM
Enjin JavaScript: Membandingkan PelaksanaanApr 13, 2025 am 12:05 AMEnjin JavaScript yang berbeza mempunyai kesan yang berbeza apabila menguraikan dan melaksanakan kod JavaScript, kerana prinsip pelaksanaan dan strategi pengoptimuman setiap enjin berbeza. 1. Analisis leksikal: Menukar kod sumber ke dalam unit leksikal. 2. Analisis Tatabahasa: Menjana pokok sintaks abstrak. 3. Pengoptimuman dan Penyusunan: Menjana kod mesin melalui pengkompil JIT. 4. Jalankan: Jalankan kod mesin. Enjin V8 mengoptimumkan melalui kompilasi segera dan kelas tersembunyi, Spidermonkey menggunakan sistem kesimpulan jenis, menghasilkan prestasi prestasi yang berbeza pada kod yang sama.
 Beyond the Browser: JavaScript di dunia nyataApr 12, 2025 am 12:06 AM
Beyond the Browser: JavaScript di dunia nyataApr 12, 2025 am 12:06 AMAplikasi JavaScript di dunia nyata termasuk pengaturcaraan sisi pelayan, pembangunan aplikasi mudah alih dan Internet of Things Control: 1. Pengaturcaraan sisi pelayan direalisasikan melalui node.js, sesuai untuk pemprosesan permintaan serentak yang tinggi. 2. Pembangunan aplikasi mudah alih dijalankan melalui reaktnatif dan menyokong penggunaan silang platform. 3. Digunakan untuk kawalan peranti IoT melalui Perpustakaan Johnny-Five, sesuai untuk interaksi perkakasan.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

