
Rumah >pembangunan bahagian belakang >Tutorial Python >Saya membuat apl semakan kiraan token menggunakan Streamlit in Snowflake (SiS)
Saya membuat apl semakan kiraan token menggunakan Streamlit in Snowflake (SiS)

- DDDasal
- 2024-09-14 12:15:10999semak imbas
pengenalan
Helo, saya seorang Jurutera Jualan di Snowflake. Saya ingin berkongsi beberapa pengalaman dan percubaan saya dengan anda melalui pelbagai siaran. Dalam artikel ini, saya akan menunjukkan kepada anda cara membuat apl menggunakan Streamlit in Snowflake untuk menyemak kiraan token dan menganggarkan kos untuk Cortex LLM.
Nota: Catatan ini mewakili pandangan peribadi saya dan bukan pandangan Snowflake.
Apakah Streamlit dalam Snowflake (SiS)?
Streamlit ialah perpustakaan Python yang membolehkan anda mencipta UI web dengan kod Python yang mudah, menghapuskan keperluan untuk HTML/CSS/JavaScript. Anda boleh melihat contoh dalam Galeri Apl.
Streamlit dalam Snowflake membolehkan anda membangunkan dan menjalankan apl web Streamlit secara langsung pada Snowflake. Ia mudah digunakan hanya dengan akaun Snowflake dan bagus untuk menyepadukan data jadual Snowflake ke dalam apl web.
Mengenai Streamlit dalam Snowflake (Dokumentasi Rasmi Snowflake)
Apakah Snowflake Cortex?
Snowflake Cortex ialah set ciri AI generatif dalam Snowflake. Cortex LLM membolehkan anda memanggil model bahasa besar yang dijalankan pada Snowflake menggunakan fungsi mudah dalam SQL atau Python.
Fungsi Model Bahasa Besar (LLM) (Korteks Kepingan Salji) (Dokumentasi Kepingan Salji Rasmi)
Gambaran Keseluruhan Ciri
Imej
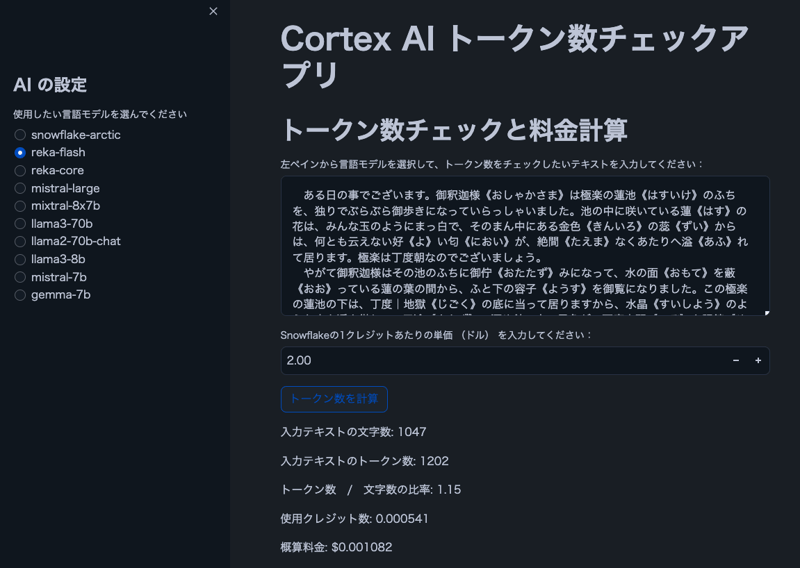
Nota: Teks dalam imej adalah daripada "The Spider's Thread" oleh Ryunosuke Akutagawa.
Ciri-ciri
- Pengguna boleh memilih model Cortex LLM
- Paparkan watak dan kiraan token untuk teks input pengguna
- Tunjukkan nisbah token kepada aksara
- Kira anggaran kos berdasarkan harga kredit Snowflake
Nota: Jadual harga Cortex LLM (PDF)
Prasyarat
- Akaun Snowflake dengan akses Cortex LLM
- snowflake-ml-python 1.1.2 atau lebih baru
Nota: ketersediaan rantau Cortex LLM (Dokumentasi Kepingan Salji Rasmi)
Kod Sumber
import streamlit as st
from snowflake.snowpark.context import get_active_session
import snowflake.snowpark.functions as F
# Get current session
session = get_active_session()
# Application title
st.title("Cortex AI Token Count Checker")
# AI settings
st.sidebar.title("AI Settings")
lang_model = st.sidebar.radio("Select the language model you want to use",
("snowflake-arctic", "reka-core", "reka-flash",
"mistral-large2", "mistral-large", "mixtral-8x7b", "mistral-7b",
"llama3.1-405b", "llama3.1-70b", "llama3.1-8b",
"llama3-70b", "llama3-8b", "llama2-70b-chat",
"jamba-instruct", "gemma-7b")
)
# Function to count tokens (using Cortex's token counting function)
def count_tokens(model, text):
result = session.sql(f"SELECT SNOWFLAKE.CORTEX.COUNT_TOKENS('{model}', '{text}') as token_count").collect()
return result[0]['TOKEN_COUNT']
# Token count check and cost calculation
st.header("Token Count Check and Cost Calculation")
input_text = st.text_area("Select a language model from the left pane and enter the text you want to check for token count:", height=200)
# Let user input the price per credit
credit_price = st.number_input("Enter the price per Snowflake credit (in dollars):", min_value=0.0, value=2.0, step=0.01)
# Credits per 1M tokens for each model (as of 2024/8/30, mistral-large2 is not supported)
model_credits = {
"snowflake-arctic": 0.84,
"reka-core": 5.5,
"reka-flash": 0.45,
"mistral-large2": 1.95,
"mistral-large": 5.1,
"mixtral-8x7b": 0.22,
"mistral-7b": 0.12,
"llama3.1-405b": 3,
"llama3.1-70b": 1.21,
"llama3.1-8b": 0.19,
"llama3-70b": 1.21,
"llama3-8b": 0.19,
"llama2-70b-chat": 0.45,
"jamba-instruct": 0.83,
"gemma-7b": 0.12
}
if st.button("Calculate Token Count"):
if input_text:
# Calculate character count
char_count = len(input_text)
st.write(f"Character count of input text: {char_count}")
if lang_model in model_credits:
# Calculate token count
token_count = count_tokens(lang_model, input_text)
st.write(f"Token count of input text: {token_count}")
# Ratio of tokens to characters
ratio = token_count / char_count if char_count > 0 else 0
st.write(f"Token count / Character count ratio: {ratio:.2f}")
# Cost calculation
credits_used = (token_count / 1000000) * model_credits[lang_model]
cost = credits_used * credit_price
st.write(f"Credits used: {credits_used:.6f}")
st.write(f"Estimated cost: ${cost:.6f}")
else:
st.warning("The selected model is not supported by Snowflake's token counting feature.")
else:
st.warning("Please enter some text.")
Kesimpulan
Apl ini memudahkan untuk menganggarkan kos untuk beban kerja LLM, terutamanya apabila berurusan dengan bahasa seperti Jepun yang selalunya terdapat jurang antara kiraan aksara dan kiraan token. Saya harap anda dapati ia berguna!
Pengumuman
Kepingan Salji Apakah Kemas Kini Baharu pada X
Saya berkongsi kemas kini Snowflake's What's New pada X. Sila ikuti jika anda berminat!
Versi Bahasa Inggeris
Snowflake What's New Bot (Versi Bahasa Inggeris)
https://x.com/snow_new_en
Versi Jepun
Bot Baharu Kepingan Salji (Versi Jepun)
https://x.com/snow_new_jp
Sejarah Perubahan
(20240914) Catatan awal
Artikel Asal Jepun
https://zenn.dev/tsubasa_tech/articles/4dd80c91508ec4
Atas ialah kandungan terperinci Saya membuat apl semakan kiraan token menggunakan Streamlit in Snowflake (SiS). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!