
Rumah >pembangunan bahagian belakang >Tutorial Python >Jambatan AI/ML dengan penyelesaian Analitis Adaptif anda
Jambatan AI/ML dengan penyelesaian Analitis Adaptif anda

- DDDasal
- 2024-09-13 06:27:07811semak imbas
Dalam landskap data hari ini, perniagaan menghadapi beberapa cabaran yang berbeza. Salah satunya ialah melakukan analitik di atas lapisan data bersatu dan harmoni yang tersedia untuk semua pengguna. Lapisan yang boleh memberikan jawapan yang sama kepada soalan yang sama tidak berkaitan dengan dialek atau alat yang digunakan.
Platform Data IRIS InterSystems menjawabnya dengan dan tambahan Analitis Adaptif yang boleh menyampaikan lapisan semantik bersatu ini. Terdapat banyak artikel dalam DevCommunity tentang menggunakannya melalui alat BI. Artikel ini akan membincangkan bahagian cara menggunakannya dengan AI dan juga cara mengembalikan beberapa cerapan.
Jom selangkah demi selangkah...
Apakah itu Analitis Adaptif?
Anda boleh menemui beberapa definisi dengan mudah dalam tapak web komuniti pembangun
Dalam beberapa perkataan, ia boleh menyampaikan data dalam bentuk berstruktur dan harmoni kepada pelbagai alat pilihan anda untuk penggunaan dan analisis selanjutnya. Ia menyampaikan struktur data yang sama kepada pelbagai alat BI. Tetapi... ia juga boleh menghantar struktur data yang sama kepada alatan AI/ML anda!
Analitis Adaptif mempunyai dan komponen tambahan yang dipanggil AI-Link yang membina jambatan ini daripada AI kepada BI.
Apakah sebenarnya AI-Link ?
Ia ialah komponen Python yang direka bentuk untuk membolehkan interaksi program dengan lapisan semantik bagi tujuan memperkemas peringkat utama aliran kerja pembelajaran mesin (ML) (contohnya, kejuruteraan ciri).
Dengan AI-Link anda boleh:
- mengakses ciri model data analisis anda secara pemrograman;
- buat pertanyaan, teroka dimensi dan ukuran;
- saluran paip suapan ML; ... dan menyampaikan hasil kembali ke lapisan semantik anda untuk digunakan semula oleh orang lain (cth. melalui Tableau atau Excel).
Memandangkan ini adalah perpustakaan Python, ia boleh digunakan dalam mana-mana persekitaran Python. Termasuk Buku Nota.
Dan dalam artikel ini saya akan memberikan contoh mudah untuk mencapai penyelesaian Analitis Adaptif daripada Jupyter Notebook dengan bantuan AI-Link.
Berikut ialah repositori git yang akan mempunyai Buku Nota lengkap sebagai contoh: https://github.com/v23ent/aa-hands-on
Pra-syarat
Langkah selanjutnya andaikan anda telah melengkapkan pra-syarat berikut:
- Penyelesaian Analitis Adaptif sedang dijalankan (dengan Platform Data IRIS sebagai Gudang Data)
- Buku Nota Jupyter sedang berjalan
- Sambungan antara 1. dan 2. boleh diwujudkan
Langkah 1: Persediaan
Pertama, mari kita pasang komponen yang diperlukan dalam persekitaran kita. Itu akan memuat turun beberapa pakej yang diperlukan untuk langkah selanjutnya untuk berfungsi.
'atscale' - ini adalah pakej utama kami untuk menyambung
'nabi' - pakej yang kita perlukan untuk melakukan ramalan
pip install atscale prophet
Kemudian kami perlu mengimport kelas utama yang mewakili beberapa konsep utama lapisan semantik kami.
Pelanggan - kelas yang akan kami gunakan untuk mewujudkan sambungan kepada Analitis Adaptif;
Projek - kelas untuk mewakili projek dalam Analitis Adaptif;
DataModel - kelas yang akan mewakili kiub maya kami;
from atscale.client import Client from atscale.data_model import DataModel from atscale.project import Project from prophet import Prophet import pandas as pd
Langkah 2: Sambungan
Sekarang kita sepatutnya bersedia untuk mewujudkan sambungan kepada sumber data kita.
client = Client(server='http://adaptive.analytics.server', username='sample') client.connect()
Teruskan dan nyatakan butiran sambungan bagi tika Analitis Adaptif anda. Sebaik sahaja anda diminta untuk organisasi membalas dalam kotak dialog dan kemudian sila masukkan kata laluan anda daripada contoh AtScale.
Dengan sambungan yang telah ditetapkan, anda kemudiannya perlu memilih projek anda daripada senarai projek yang diterbitkan pada pelayan. Anda akan mendapat senarai projek sebagai gesaan interaktif dan jawapannya mestilah ID integer projek. Dan kemudian model data dipilih secara automatik jika ia adalah satu-satunya.
project = client.select_project() data_model = project.select_data_model()
Langkah 3: Teroka set data anda
Terdapat beberapa kaedah yang disediakan oleh AtScale dalam perpustakaan komponen AI-Link. Mereka membenarkan untuk meneroka katalog data yang anda miliki, data pertanyaan, dan juga menelan beberapa data kembali. Dokumentasi AtScale mempunyai rujukan API yang luas yang menerangkan semua yang tersedia.
Mari kita lihat dahulu apakah set data kita dengan memanggil beberapa kaedah model_data:
data_model.get_features() data_model.get_all_categorical_feature_names() data_model.get_all_numeric_feature_names()
Output sepatutnya kelihatan seperti ini
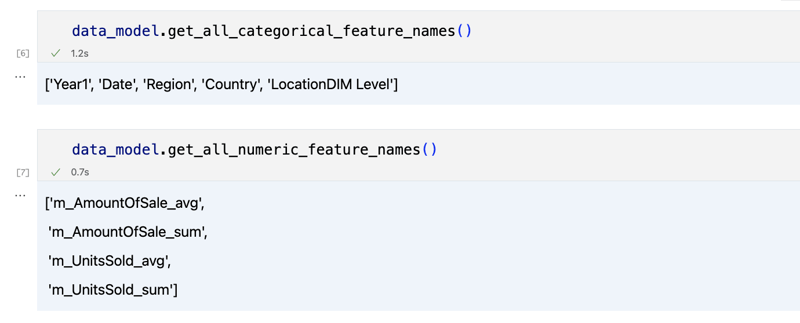
Sebaik sahaja kami melihat sekeliling, kami boleh menanyakan data sebenar yang kami berminat untuk menggunakan kaedah 'get_data'. Ia akan mengembalikan semula DataFrame panda yang mengandungi hasil pertanyaan.
df = data_model.get_data(feature_list = ['Country','Region','m_AmountOfSale_sum']) df = df.sort_values(by='m_AmountOfSale_sum') df.head()
Yang akan menunjukkan datadrame anda:
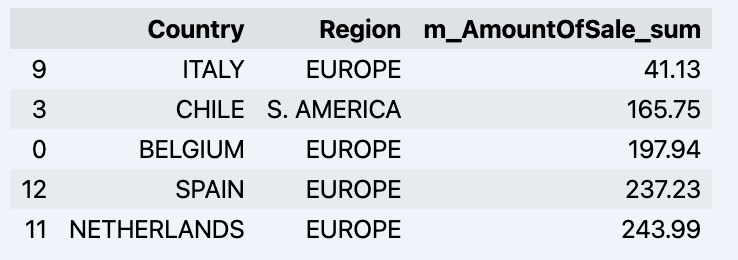
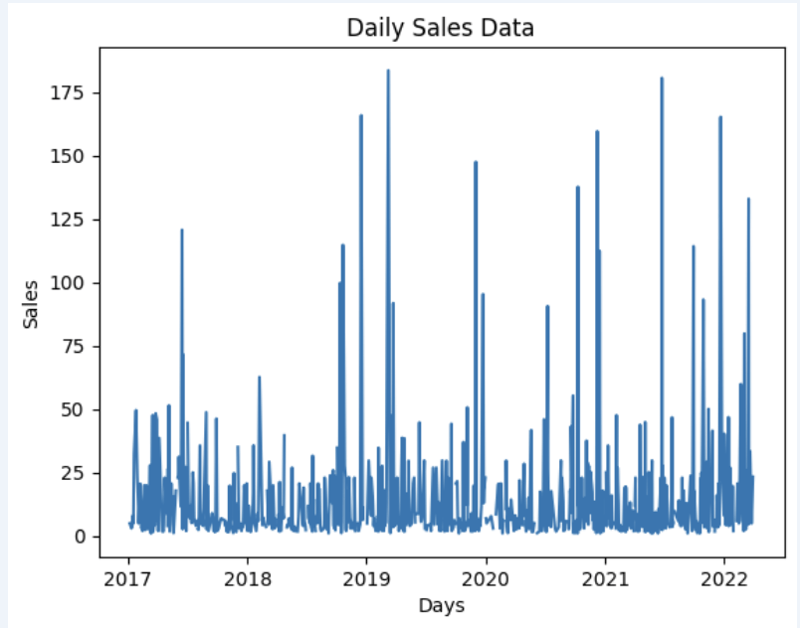
Mari sediakan beberapa set data dan tunjukkan dengan cepat pada graf
import matplotlib.pyplot as plt
# We're taking sales for each date
dataframe = data_model.get_data(feature_list = ['Date','m_AmountOfSale_sum'])
# Create a line chart
plt.plot(dataframe['Date'], dataframe['m_AmountOfSale_sum'])
# Add labels and a title
plt.xlabel('Days')
plt.ylabel('Sales')
plt.title('Daily Sales Data')
# Display the chart
plt.show()
Output:
Step 4: Prediction
The next step would be to actually get some value out of AI-Link bridge - let's do some simple prediction!
# Load the historical data to train the model
data_train = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_less = {'Date':'2021-01-01'}
)
data_test = data_model.get_data(
feature_list = ['Date','m_AmountOfSale_sum'],
filter_greater = {'Date':'2021-01-01'}
)
We get 2 different datasets here: to train our model and to test it.
# For the tool we've chosen to do the prediction 'Prophet', we'll need to specify 2 columns: 'ds' and 'y'
data_train['ds'] = pd.to_datetime(data_train['Date'])
data_train.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
data_test['ds'] = pd.to_datetime(data_test['Date'])
data_test.rename(columns={'m_AmountOfSale_sum': 'y'}, inplace=True)
# Initialize and fit the Prophet model
model = Prophet()
model.fit(data_train)
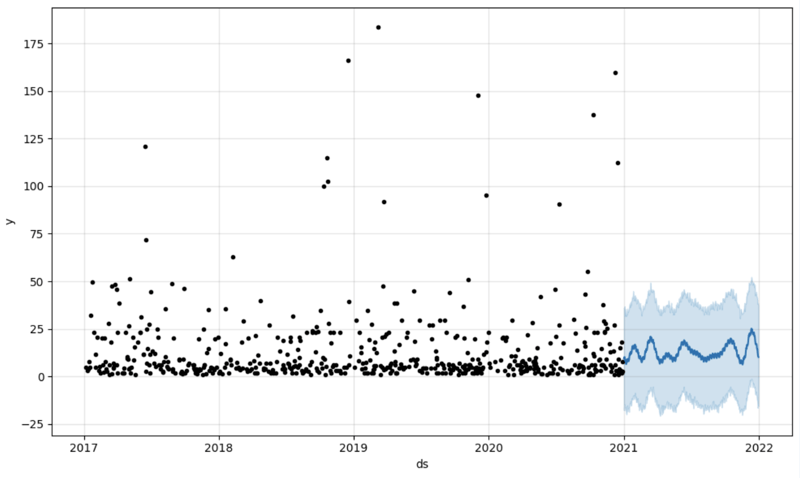
And then we create another dataframe to accomodate our prediction and display it on the graph
# Create a future dataframe for forecasting future = pd.DataFrame() future['ds'] = pd.date_range(start='2021-01-01', end='2021-12-31', freq='D') # Make predictions forecast = model.predict(future) fig = model.plot(forecast) fig.show()
Output:
Step 5: Writeback
Once we've got our prediction in place we can then put it back to the data warehouse and add an aggregate to our semantic model to reflect it for other consumers. The prediction would be available through any other BI tool for BI analysts and business users.
The prediction itself will be placed into our data warehouse and stored there.
from atscale.db.connections import Iris<br>
db = Iris(<br>
username,<br>
host,<br>
namespace,<br>
driver,<br>
schema, <br>
port=1972,<br>
password=None, <br>
warehouse_id=None<br>
)
<p>data_model.writeback(dbconn=db,<br>
table_name= 'SalesPrediction',<br>
DataFrame = forecast)</p>
<p>data_model.create_aggregate_feature(dataset_name='SalesPrediction',<br>
column_name='SalesForecasted',<br>
name='sum_sales_forecasted',<br>
aggregation_type='SUM')<br>
</p>
Fin
That is it!
Good luck with your predictions!
Atas ialah kandungan terperinci Jambatan AI/ML dengan penyelesaian Analitis Adaptif anda. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!