
Rumah >pembangunan bahagian belakang >Tutorial Python >Penerokaan dan Visualisasi Set Data Filem
Penerokaan dan Visualisasi Set Data Filem

- PHPzasal
- 2024-09-11 16:15:081255semak imbas
Pengenalan
Amalan menjadikan sempurna.
Sesuatu yang mempunyai banyak persamaan dengan menjadi saintis data. Teori hanyalah satu aspek persamaan; aspek yang paling penting ialah mempraktikkan teori. Saya akan berusaha untuk merekodkan keseluruhan proses hari ini untuk membangunkan projek batu penjuru saya, yang akan melibatkan kajian set data filem.
Ini adalah objektifnya:
Objektif:
- Muat turun set data filem daripada Kaggle atau dapatkan semula menggunakan API TMDb.
- Terokai pelbagai aspek seperti genre filem, rating, populariti pengarah dan trend tahun keluaran.
- Buat papan pemuka yang menggambarkan arah aliran ini dan secara pilihan mengesyorkan filem berdasarkan pilihan pengguna.
1. Pengumpulan Data
Saya memutuskan untuk menggunakan Kaggle untuk mencari set data saya. Adalah penting untuk mengingati pembolehubah penting yang anda inginkan untuk set data yang anda gunakan. Yang penting, set data saya harus termasuk yang berikut: arah aliran dalam tahun keluaran, populariti pengarah, penilaian dan genre filem. Akibatnya, saya mesti memastikan set data yang saya pilih mempunyai perkara berikut, sekurang-kurangnya.
Set data saya terletak di Kaggle dan saya akan memberikan pautan di bawah. Anda boleh mendapatkan versi CSV fail dengan memuat turun set data, menyahzipnya dan mengekstraknya. Anda boleh menyemaknya untuk memahami perkara yang telah anda miliki dan untuk benar-benar menyedari jenis cerapan yang anda harap dapat peroleh daripada data yang akan anda periksa.
2. Menghuraikan data
Pertama, kita mesti mengimport perpustakaan yang diperlukan dan memuatkan data yang diperlukan. Saya menggunakan bahasa pengaturcaraan Python dan Buku Nota Jupyter untuk projek saya supaya saya boleh menulis dan melihat kod saya dengan lebih cekap.
Anda akan mengimport perpustakaan yang akan kami gunakan dan memuatkan data seperti yang ditunjukkan di bawah.
Kami kemudian akan menjalankan perintah berikut untuk mendapatkan butiran lanjut tentang set data kami.
data.head() # dispalys the first rows of the dataset. data.tail() # displays the last rows of the dataset. data.shape # Shows the total number of rows and columns. len(data.columns) # Shows the total number of columns. data.columns # Describes different column names. data.dtypes # Describes different data types.
Kini kami tahu kandungan set data dan cerapan yang kami harap dapat diekstrak selepas mendapat semua huraian yang kami perlukan. Contoh: Menggunakan set data saya, saya ingin menyiasat corak dalam populariti pengarah, pengedaran rating dan genre filem. Saya juga ingin mencadangkan filem bergantung pada pilihan pengguna, seperti pengarah dan genre pilihan.
3. Pembersihan Data
Fasa ini melibatkan mencari sebarang nilai nol dan mengalih keluarnya. Untuk meneruskan dengan visualisasi data, kami juga akan memeriksa set data kami untuk pendua dan mengalih keluar mana-mana yang kami temui. Untuk melakukan ini, kami akan menjalankan kod yang berikut:
1. data['show_id'].value_counts().sum() # Checks for the total number of rows in my dataset 2. data.isna().sum() # Checks for null values(I found null values in director, cast and country columns) 3. data[['director', 'cast', 'country']] = data[['director', 'cast', 'country']].replace(np.nan, "Unknown ") # Fill null values with unknown.
Kami kemudian akan menggugurkan baris dengan nilai yang tidak diketahui dan mengesahkan kami telah menggugurkan kesemuanya. Kami juga akan menyemak bilangan baris yang tinggal yang telah membersihkan data.
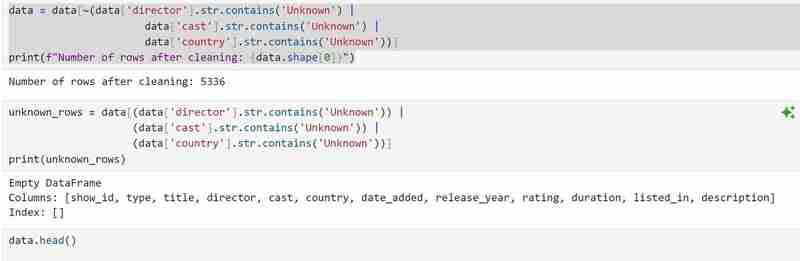
Kod yang berikut mencari ciri unik dan pendua. Walaupun tiada pendua dalam set data saya, anda mungkin masih perlu menggunakannya sekiranya set data akan datang melakukannya.
data.duplicated().sum() # Checks for duplicates data.nunique() # Checks for unique features data.info # Confirms if nan values are present and also shows datatypes.
Jenis data tarikh/masa saya ialah objek dan saya ingin ia berada dalam format tarikh/masa yang betul jadi saya gunakan
data['date_added']=data['date_added'].astype('datetime64[ms]')untuk menukarnya kepada format yang betul.
4. Visualisasi Data
Data data saya mempunyai dua jenis pembolehubah iaitu rancangan TV dan Filem dalam jenis dan saya menggunakan graf bar untuk membentangkan data kategori dengan nilai yang diwakilinya.

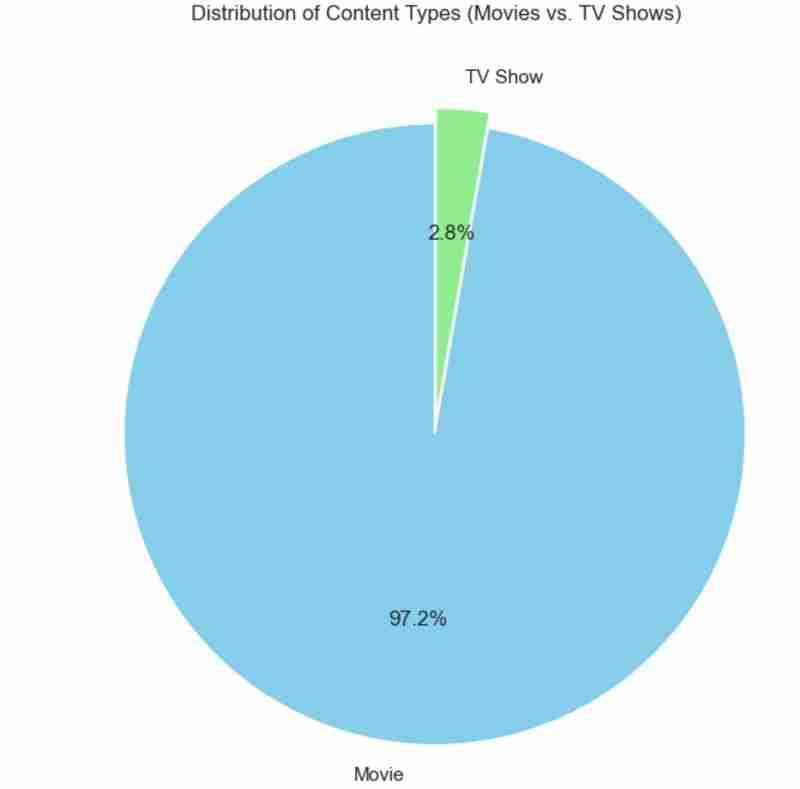
Saya juga menggunakan carta pai untuk mewakili perkara yang sama seperti di atas. Kod yang digunakan adalah seperti berikut dan keputusan dijangka ditunjukkan di bawah.
## Pie chart display
plt.figure(figsize=(8, 8))
data['type'].value_counts().plot(
kind='pie',
autopct='%1.1f%%',
colors=['skyblue', 'lightgreen'],
startangle=90,
explode=(0.05, 0)
)
plt.title('Distribution of Content Types (Movies vs. TV Shows)')
plt.ylabel('')
plt.show()
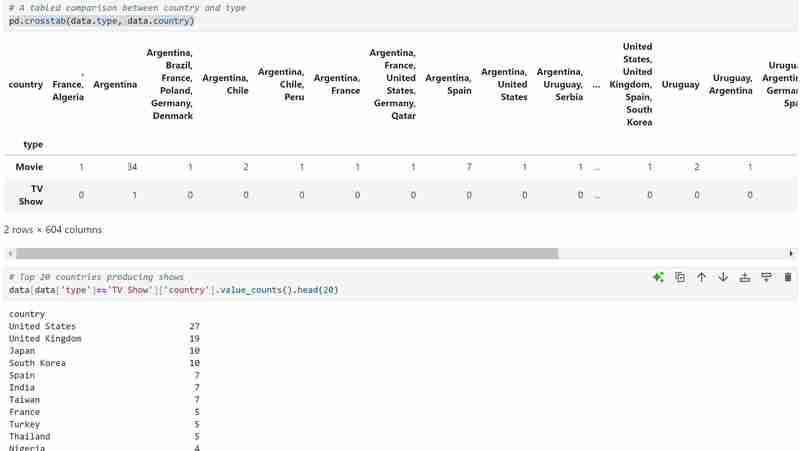
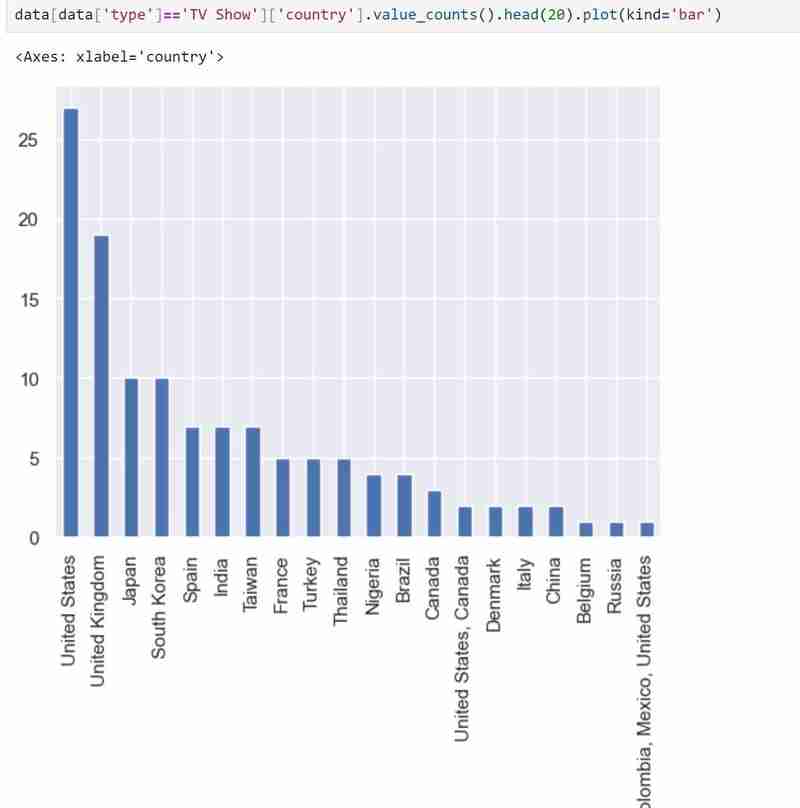
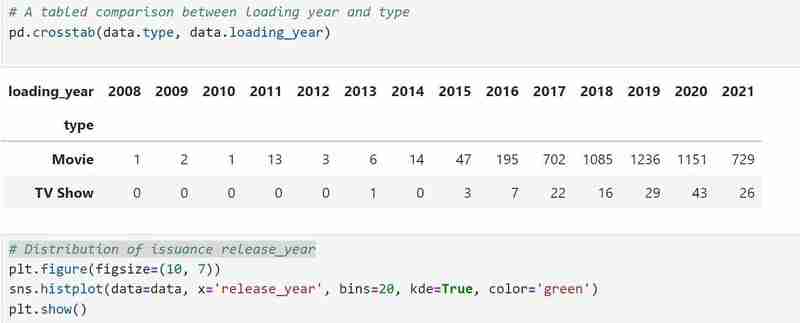
- Saya kemudian melakukan perbandingan dibentangkan menggunakan pd.crosstab(data.type, data.country) untuk membuat perbandingan dibentangkan jenis berdasarkan tarikh keluaran, negara dan faktor lain (anda boleh cuba menukar lajur dalam kod secara bebas). Di bawah ialah kod untuk digunakan dan perbandingan yang dijangkakan. Saya juga menyemak 20 negara pertama yang terkemuka dalam pengeluaran Rancangan Tv dan memvisualisasikannya dalam graf bar. Anda boleh menyalin kod dalam imej dan memastikan hasilnya hampir serupa dengan saya.
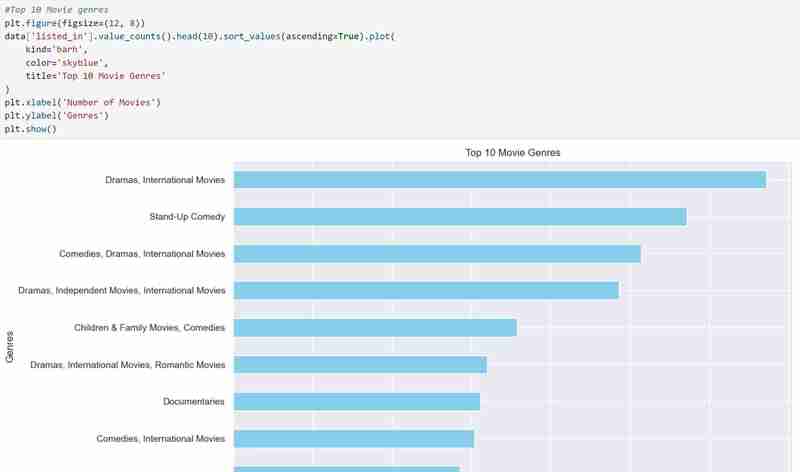
- I then checked for the top 10 movie genre as shown below. You can also use the code to check for TV shows. Just substitute with proper variable names.
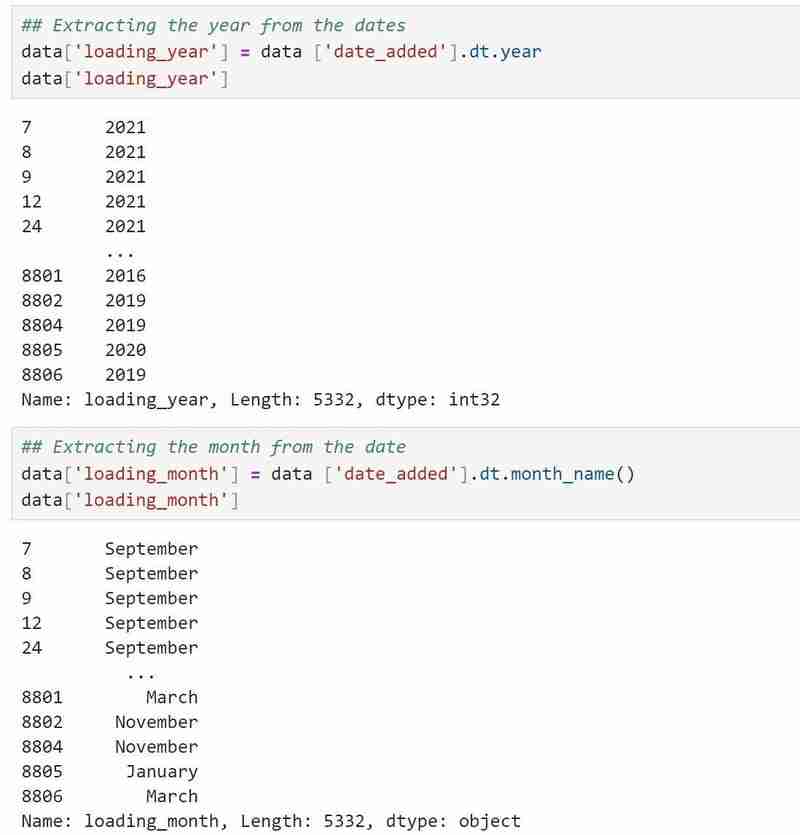
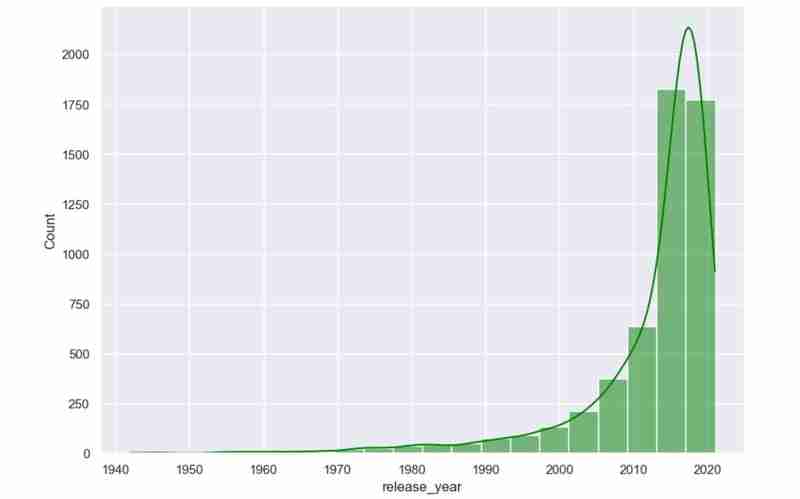
- I extracted months and years separately from the dates provided so that I could visualize some histogram plots over the years.
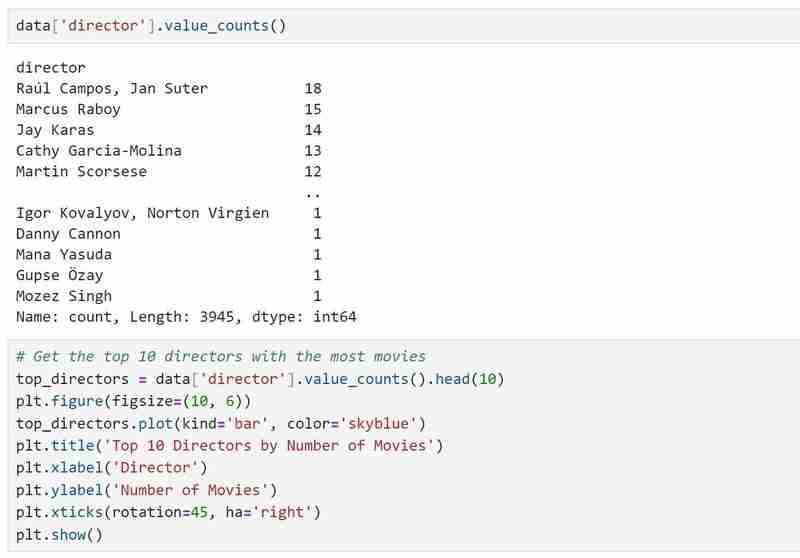
- Checked for the top 10 directors with the most movies and compared them using a bar graph.
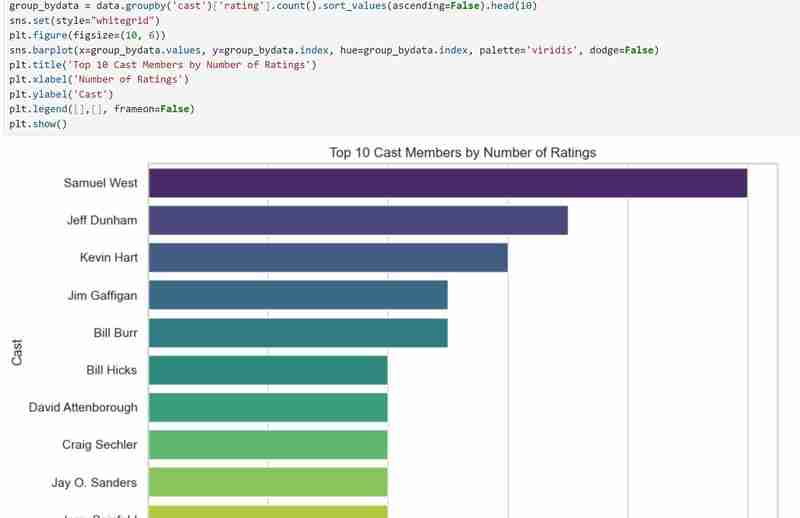
- Checked for the cast with the highest rating and visualized them.
5. Recommendation System
I then built a recommendation system that takes in genre or director's name as input and produces a list of movies as per the user's preference. If the input cannot be matched by the algorithm then the user is notified.

The code for the above is as follows:
def recommend_movies(genre=None, director=None):
recommendations = data
if genre:
recommendations = recommendations[recommendations['listed_in'].str.contains(genre, case=False, na=False)]
if director:
recommendations = recommendations[recommendations['director'].str.contains(director, case=False, na=False)]
if not recommendations.empty:
return recommendations[['title', 'director', 'listed_in', 'release_year', 'rating']].head(10)
else:
return "No movies found matching your preferences."
print("Welcome to the Movie Recommendation System!")
print("You can filter movies by Genre or Director (or both).")
user_genre = input("Enter your preferred genre (or press Enter to skip): ")
user_director = input("Enter your preferred director (or press Enter to skip): ")
recommendations = recommend_movies(genre=user_genre, director=user_director)
print("\nRecommended Movies:")
print(recommendations)
Conclusion
My goals were achieved, and I had a great time taking on this challenge since it helped me realize that, even though learning is a process, there are days when I succeed and fail. This was definitely a success. Here, we celebrate victories as well as defeats since, in the end, each teach us something. Do let me know if you attempt this.
Till next time!
Note!!
The code is in my GitHub:
https://github.com/MichelleNjeri-scientist/Movie-Dataset-Exploration-and-Visualization
The Kaggle dataset is:
https://www.kaggle.com/datasets/shivamb/netflix-shows
Atas ialah kandungan terperinci Penerokaan dan Visualisasi Set Data Filem. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!