
Rumah >hujung hadapan web >tutorial js >Membina aplikasi RAG dengan LlamaIndex.ts dan Azure OpenAI: Bermula!
Membina aplikasi RAG dengan LlamaIndex.ts dan Azure OpenAI: Bermula!

- WBOYasal
- 2024-09-10 18:30:30779semak imbas
Memandangkan AI terus membentuk cara kita bekerja dan berinteraksi dengan teknologi, banyak perniagaan sedang mencari cara untuk memanfaatkan data mereka sendiri dalam aplikasi pintar. Jika anda telah menggunakan alatan seperti ChatGPT atau Azure OpenAI, anda sudah biasa dengan cara AI generatif boleh meningkatkan proses dan meningkatkan pengalaman pengguna. Walau bagaimanapun, untuk respons yang benar-benar disesuaikan dan berkaitan, aplikasi anda perlu memasukkan data proprietari anda.
Di sinilah Retrieval-Augmented Generation (RAG) masuk, menyediakan pendekatan berstruktur untuk menyepadukan pengambilan data dengan respons dikuasakan AI. Dengan rangka kerja seperti LlamaIndex, anda boleh membina keupayaan ini ke dalam penyelesaian anda dengan mudah, membuka kunci potensi penuh data perniagaan anda.
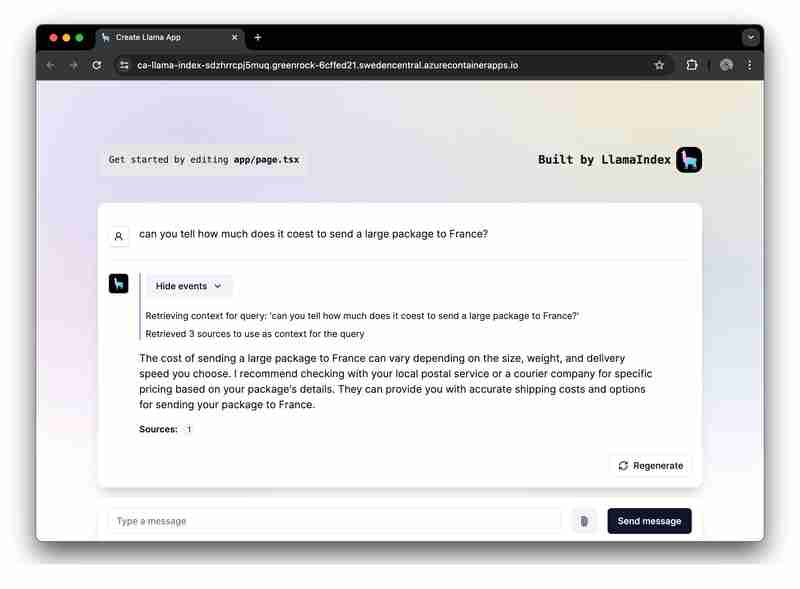
Mahu menjalankan dan meneroka apl dengan pantas? Klik di sini.
Apakah itu RAG - Penjanaan Pertambahan Pendapatan?
Retrieval-Augmented Generation (RAG) ialah rangka kerja rangkaian saraf yang meningkatkan penjanaan teks AI dengan memasukkan komponen perolehan untuk mengakses maklumat yang berkaitan dan menyepadukan data anda sendiri. Ia terdiri daripada dua bahagian utama:
- Retriever: Model retriever padat (cth., berdasarkan BERT) yang mencari korpus besar dokumen untuk mencari petikan atau maklumat yang berkaitan yang berkaitan dengan pertanyaan yang diberikan.
- Penjana: Model jujukan-ke-jujukan (cth., berdasarkan BART atau T5) yang mengambil pertanyaan dan teks yang diambil sebagai input dan menjana respons yang koheren dan diperkaya secara kontekstual.
Retriever mencari dokumen yang berkaitan, dan penjana menggunakannya untuk mencipta respons yang lebih tepat dan bermaklumat. Gabungan ini membolehkan model RAG memanfaatkan pengetahuan luaran dengan berkesan, meningkatkan kualiti dan kaitan teks yang dijana.
Bagaimanakah LlamaIndex melaksanakan RAG?
Untuk melaksanakan sistem RAG menggunakan LlamaIndex, ikut langkah umum ini:
Pengingesan Data:
- Muatkan dokumen anda ke dalam LlamaIndex.ts menggunakan pemuat dokumen seperti SimpleDirectoryReader, yang membantu dalam mengimport data daripada pelbagai sumber seperti PDF, API atau pangkalan data SQL.
- Pecahkan dokumen besar kepada bahagian yang lebih kecil dan boleh diurus menggunakan SentenceSplitter.
Penciptaan Indeks:
- Buat indeks vektor bagi ketulan dokumen ini menggunakan VectorStoreIndex, membenarkan carian persamaan yang cekap berdasarkan pembenaman.
- Secara pilihan, untuk set data kompleks, gunakan teknik perolehan semula rekursif untuk mengurus data berstruktur hierarki dan dapatkan semula bahagian yang berkaitan berdasarkan pertanyaan pengguna.
Persediaan Enjin Pertanyaan:
- Tukar indeks vektor kepada enjin pertanyaan menggunakan asQueryEngine dengan parameter seperti similarityTopK untuk menentukan bilangan dokumen teratas yang perlu diambil.
- Untuk persediaan yang lebih maju, cipta sistem berbilang ejen di mana setiap ejen bertanggungjawab untuk dokumen tertentu dan ejen peringkat atas menyelaraskan proses mendapatkan semula keseluruhan.
Pengambilan dan Penjanaan:
- Laksanakan saluran paip RAG dengan mentakrifkan fungsi objektif yang mendapatkan semula ketulan dokumen yang berkaitan berdasarkan pertanyaan pengguna.
- Gunakan RetrieverQueryEngine untuk melaksanakan perolehan semula dan pemprosesan pertanyaan yang sebenar, dengan langkah pasca pemprosesan pilihan seperti menyusun semula dokumen yang diambil menggunakan alatan seperti CohereRerank.
Untuk contoh praktikal, kami telah menyediakan contoh aplikasi untuk menunjukkan pelaksanaan RAG yang lengkap menggunakan Azure OpenAI.
Aplikasi Contoh RAG Praktikal
Kami kini akan menumpukan pada membina aplikasi RAG menggunakan LlamaIndex.ts (pelaksanaan TypeScipt LlamaIndex) dan Azure OpenAI, dan menggunakan padanya sebagai Apl Web tanpa pelayan pada Apl Kontena Azure.
Keperluan untuk Menjalankan Sampel
- CLI Pembangun Azure (azd): Alat baris perintah untuk menggunakan keseluruhan apl anda dengan mudah, termasuk bahagian belakang, bahagian hadapan dan pangkalan data.
- Akaun Azure: Anda memerlukan akaun Azure untuk menggunakan aplikasi. Dapatkan akaun Azure percuma dengan beberapa kredit untuk bermula.
Anda akan menemui projek permulaan di GitHub. Kami mengesyorkan anda untuk memotong templat ini supaya anda boleh mengeditnya dengan bebas apabila diperlukan:

Seni Bina Aras Tinggi
Aplikasi projek permulaan dibina berdasarkan seni bina berikut:
- Azure OpenAI:處理使用者查詢的 AI 提供者。
- LlamaIndex.ts:幫助擷取、轉換和向量化內容 (PDF) 以及建立搜尋索引的框架。
- Azure 容器應用程式:託管無伺服器應用程式的容器環境。
- Azure 託管身分:確保一流的安全性並消除處理憑證和 API 金鑰的需要。

有關部署哪些資源的更多詳細信息,請檢查我們所有範例中可用的 infra 資料夾。
使用者工作流程範例
範例應用程式包含兩個工作流程的邏輯:
-
資料攝取:取得資料、向量化資料並建立搜尋索引。如果您想要新增更多文件,例如 PDF 或 Word 文件,您應該在此處新增它們。
npm run generate
服務提示請求:應用程式接收使用者提示,將其傳送至 Azure OpenAI,並使用向量索引作為擷取器來增強這些提示。
運行範例
執行範例之前,請確保您已預配必要的 Azure 資源。
要在 GitHub Codespace 中執行 GitHub 模板,只需按一下
在您的 Codespaces 實例中,從終端機登入您的 Azure 帳戶:
azd auth login
使用單一命令配置、打包範例應用程式並將其部署到 Azure:
azd up
要在本地運行並嘗試應用程序,請安裝 npm 依賴項並運行應用程式:
npm install npm run dev
應用程式將在您的 Codespaces 實例中的連接埠 3000 或瀏覽器中的 http://localhost:3000 上執行。
結論
本指南示範如何使用 LlamaIndex.ts 和 Azure OpenAI 建置部署在 Microsoft Azure 上的無伺服器 RAG(擷取增強產生)應用程式。透過遵循本指南,您可以利用 Azure 的基礎架構和 LlamaIndex 的功能來建立強大的 AI 應用程序,這些應用程式可根據您的資料提供上下文豐富的回應。
我們很高興看到您使用這個入門應用程式建立的內容。請隨意 fork 它並喜歡 GitHub 存儲庫以接收最新的更新和功能。
Atas ialah kandungan terperinci Membina aplikasi RAG dengan LlamaIndex.ts dan Azure OpenAI: Bermula!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Analisis mendalam bagi komponen kumpulan senarai Bootstrap
- Penjelasan terperinci tentang fungsi JavaScript kari
- Contoh lengkap penjanaan kata laluan JS dan pengesanan kekuatan (dengan muat turun kod sumber demo)
- Angularjs menyepadukan UI WeChat (weui)
- Cara cepat bertukar antara Cina Tradisional dan Cina Ringkas dengan JavaScript dan helah untuk tapak web menyokong pertukaran antara kemahiran_javascript Cina Ringkas dan Tradisional