
Rumah >Peranti teknologi >AI >Model besar multi-modal MoE yang dibangunkan sendiri pertama di China mendedahkan pemahaman multi-modal elemen campuran Tencent
Model besar multi-modal MoE yang dibangunkan sendiri pertama di China mendedahkan pemahaman multi-modal elemen campuran Tencent

- 王林asal
- 2024-08-22 22:38:25645semak imbas

AIxivコラムは、当サイトが学術的・技術的な内容を掲載するコラムです。過去数年間で、このサイトの AIxiv コラムには 2,000 件を超えるレポートが寄せられ、世界中の主要な大学や企業のトップ研究室がカバーされ、学術交流と普及を効果的に促進しています。共有したい優れた作品がある場合は、お気軽に寄稿するか、報告のために当社までご連絡ください。提出メール: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

手法の紹介: MoE アーキテクチャ
Tencent の大規模混合言語モデルは、中国で初めて混合エキスパート モデル (MoE) アーキテクチャを採用しており、モデルの全体的なパフォーマンスは、MoE アーキテクチャよりも 50% 優れています。 GPT-4o と連携し、数学、推論、その他の能力だけでなく、「現在」の質問に答えるパフォーマンスも大幅に向上しました。今年の初めには、Tencent Hunyuan がこのモデルを Tencent Yuanbao に適用しました。
Mudah dan berskala besar
- Menggunakan penyesuai MLP ringkas: Berbanding dengan penyesuai Q-bekas arus perdana sebelumnya, penyesuai MLP kurang kehilangan semasa penghantaran maklumat.
SuperClue-V menduduki tempat pertama dalam senarai domestik
Dalam penilaian ini, sistem pemahaman multi-modal Hunyuan hunyuan-vision mencapai markah 71.95, kedua selepas GPT-4o. Dari segi aplikasi berbilang modal, hunyuan-vision mendahului Claude3.5-Sonnet dan Gemini-1.5-Pro. 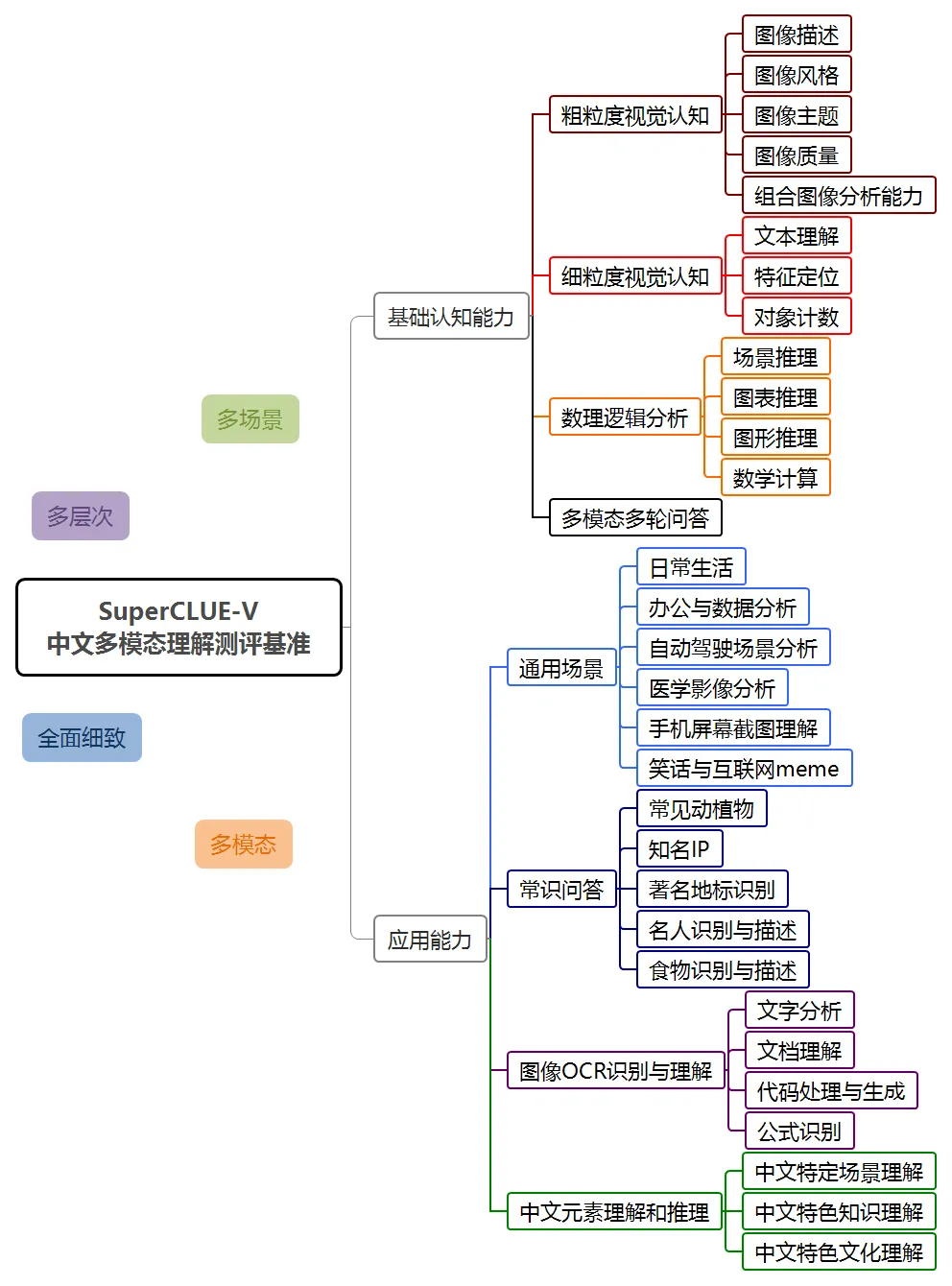
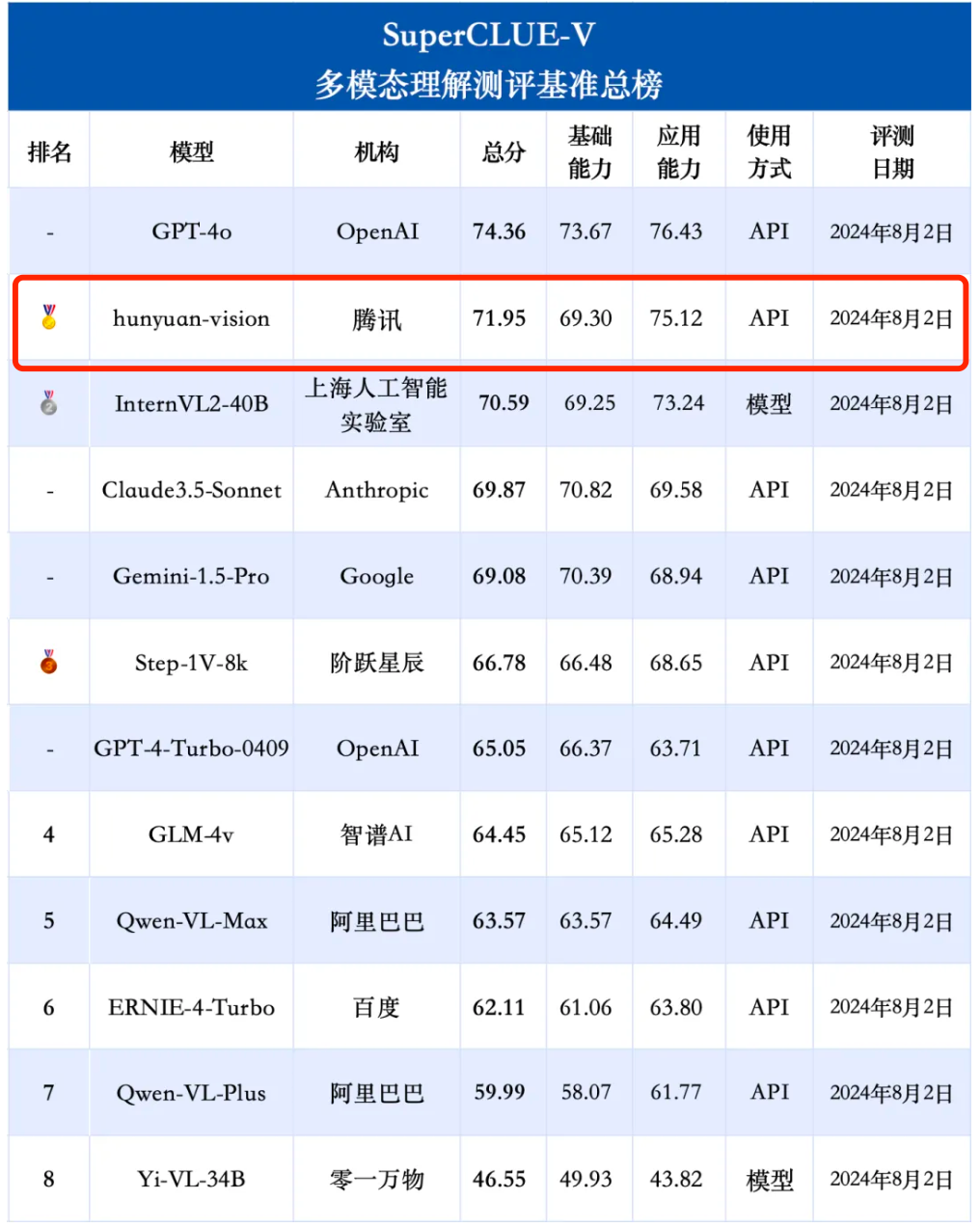
Tencent Hunyuan Graphics and Text Large Model menunjukkan prestasi yang baik dalam pelbagai dimensi seperti adegan umum, pengecaman dan pemahaman OCR imej, dan pemahaman dan penaakulan unsur Cina, dan juga mencerminkan potensi model dalam aplikasi masa hadapan . 
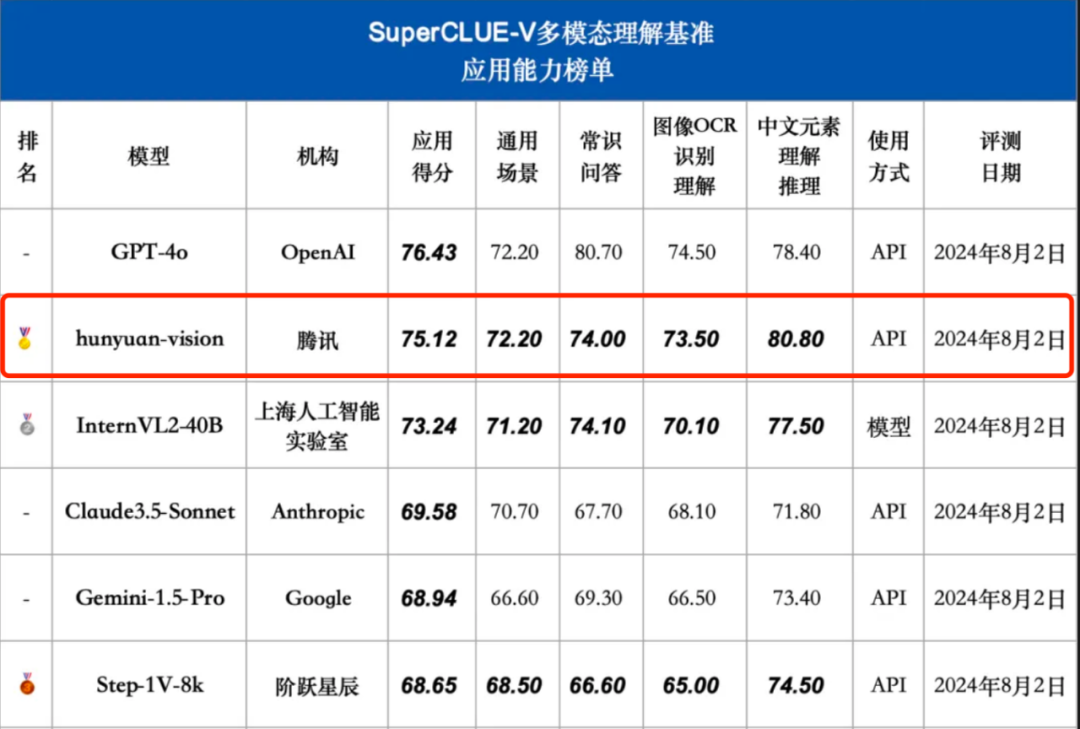 Ditujukan untuk senario aplikasi umum
Ditujukan untuk senario aplikasi umum
Di sini ada contoh yang lebih tipikal: 
plain sekeping kod: 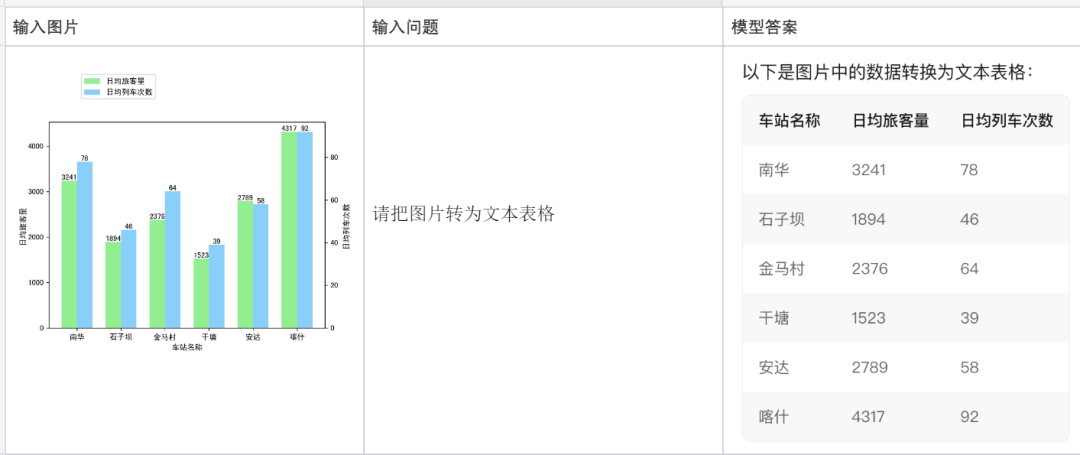
Analyze rang undang -undang: 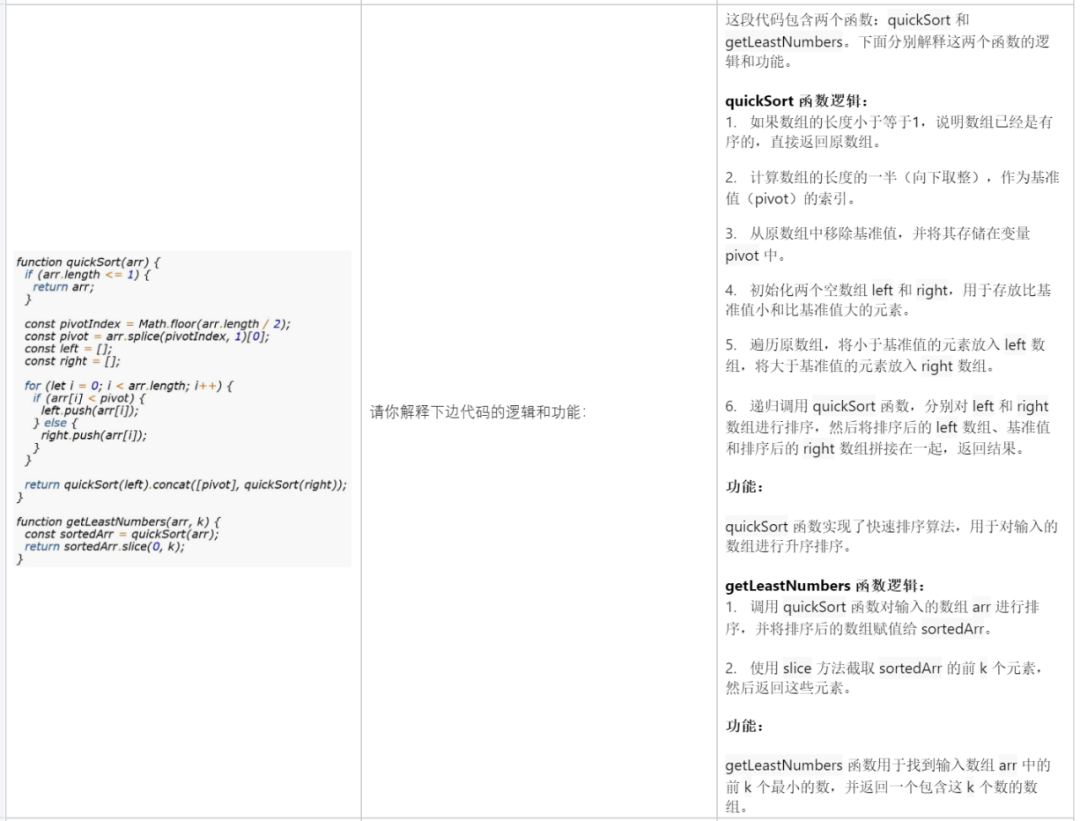
description Kandungan gambar: 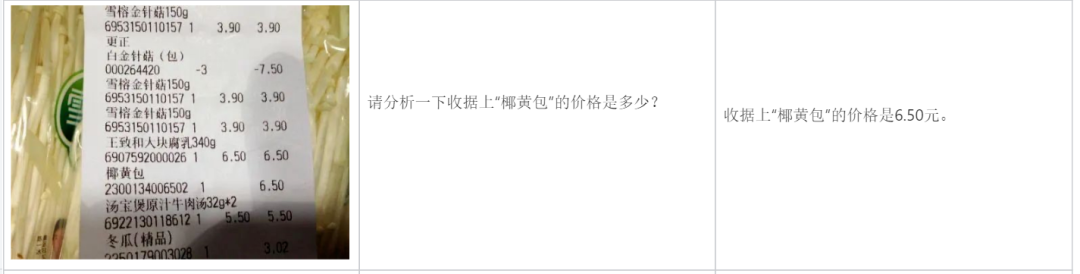
Buat masalah matematik: 
Analisis berdasarkan kandungan gambar: 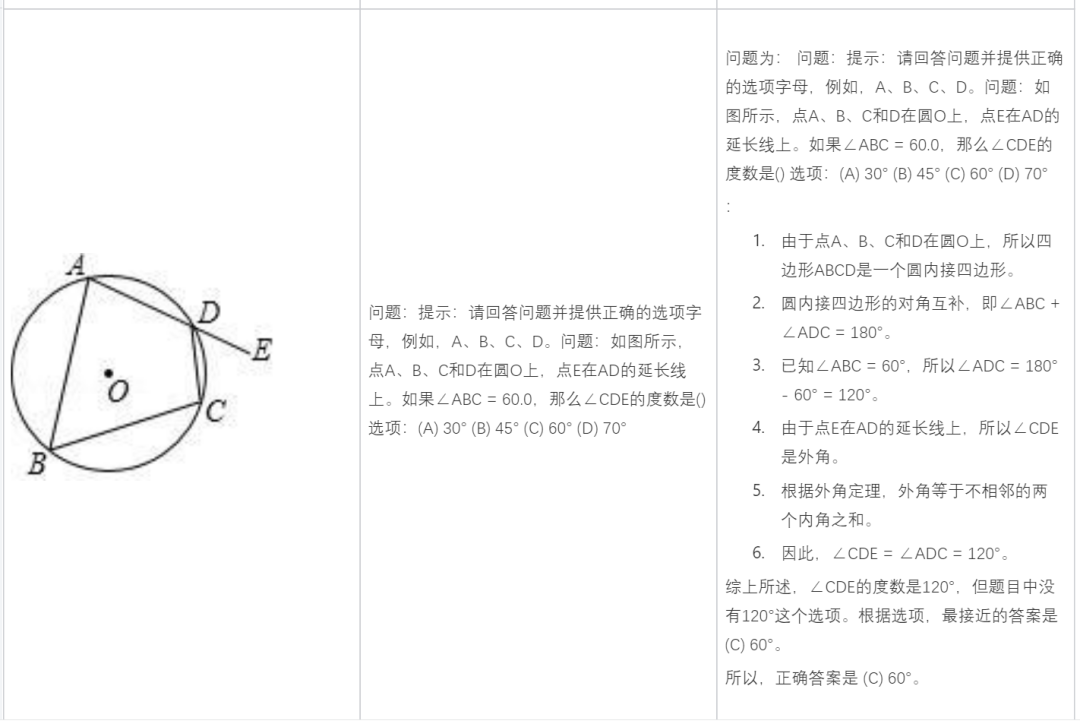
Bantu anda menulis salinan: 
Pada masa ini, model besar pemahaman pelbagai mod Hunyuan Tencent telah dilancarkan dalam produk pembantu AI Tencent Yuanbao, dan terbuka kepada perusahaan dan pembangun individu melalui Tencent Cloud.
Alamat Tencent Yuanbao: https://yuanbao.tencent.com/chat
Atas ialah kandungan terperinci Model besar multi-modal MoE yang dibangunkan sendiri pertama di China mendedahkan pemahaman multi-modal elemen campuran Tencent. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI