
Rumah >pangkalan data >tutorial mysql >Panduan lengkap SQL untuk Temuduga
Panduan lengkap SQL untuk Temuduga

- PHPzasal
- 2024-08-22 14:49:321457semak imbas
Bahasa Pertanyaan Berstruktur atau SQL ialah bahasa pangkalan data standard yang digunakan untuk mencipta, menyelenggara, memusnahkan, mengemas kini dan mendapatkan semula data daripada pangkalan data hubungan seperti MySQL, Oracle, SQL Server, PostgreSQL, dll.
Model Perhubungan Entiti (ER)
Ia ialah rangka kerja konsep yang digunakan untuk menerangkan struktur data dalam pangkalan data. Ia direka bentuk untuk mewakili entiti dunia sebenar dan hubungan antara mereka dengan cara yang lebih abstrak. Ia serupa dengan pengaturcaraan Berorientasikan Objek untuk bahasa pengaturcaraan.
Entiti: Ini ialah objek atau "benda" di dunia nyata yang mempunyai kewujudan yang berbeza, seperti pelanggan, produk atau pesanan.
Perhubungan: Ini mentakrifkan cara entiti berkaitan antara satu sama lain. Contohnya, entiti "Pelanggan" mungkin mempunyai hubungan dengan entiti "Pesanan"
Arahan:
Cipta Pangkalan Data
create database <database_name>;
Senaraikan Pangkalan Data
show databases;
Gunakan Pangkalan Data
use <database_name>
Paparan struktur jadual
DESCRIBE table_name;
Sub-bahasa SQL
Bahasa Pertanyaan Data (DQL):
Bahasa yang digunakan untuk melakukan pertanyaan pada data. Perintah ini digunakan untuk mendapatkan semula data daripada pangkalan data.
Arahan:
1) Pilih:
select * from table_name; select column1,column2 from table_name; select * from table_name where column1 = "value";
Bahasa Definisi Data (DDL):
Bahasa yang digunakan untuk mentakrifkan skema pangkalan data. Perintah ini digunakan untuk mencipta, mengubah suai dan memadam pangkalan data tetapi bukan data.
Arahan
1) Cipta:
create table table_name( column_name data_type(size) constraint, column_name data_type(size) constraint column_name data_type(size) constraint );
2) Gugur:
Perintah ini mengalih keluar jadual/pangkalan data sepenuhnya.
drop table table_name; drop database database_name;
3) Pangkas:
Perintah ini mengalih keluar data sahaja.
truncate table table_name;
4) Ubah:
Perintah ini boleh menambah, memadam atau mengemas kini lajur jadual.
Tambah
alter table table_name add column_name datatype;
Ubah suai
alter table table_name modify column column_name datatype; --ALTER TABLE employees --MODIFY COLUMN salary DECIMAL(10,2);
Jatuhkan
alter table table_name drop column_name datatype;
Bahasa Manipulasi Data (DML):
Bahasa yang digunakan untuk memanipulasi data yang terdapat dalam pangkalan data.
1) Sisipkan:
Perintah ini digunakan untuk memasukkan nilai baharu sahaja.
insert into table_name values (val1,val2,val3,val4); //4 columns
2) Kemas kini:
update table_name set col1=val1, col2=val2 where col3 = val3;
3) Padam:
delete from table_name where col1=val1;
Bahasa Kawalan Data (DCL):
GRANT: benarkan pengguna tertentu melakukan tugasan tertentu.
BATALKAN: batalkan kebenaran yang diberikan atau dinafikan sebelum ini.
Bahasa Kawalan Transaksi (TCL):
Ia digunakan mengurus transaksi dalam pangkalan data. Ia mengurus perubahan yang dilakukan oleh arahan DML.
1) Komited
Ia digunakan untuk menyimpan semua perubahan yang dibuat semasa transaksi semasa ke pangkalan data
BEGIN TRANSACTION; UPDATE employees SET salary = salary * 1.1 WHERE department = 'Sales'; COMMIT;
2) Balik semula
Ia digunakan untuk membuat asal semua perubahan yang dibuat semasa transaksi semasa
BEGIN TRANSACTION; UPDATE employees SET salary = salary * 1.1 WHERE department = 'Sales'; ROLLBACK;
3) Savepoint
begin transaction; update customers set first_name= 'one' WHERE customer_id=4; SAVEPOINT one; update customers set first_name= 'two' WHERE customer_id=4; ROLLBACK TO SAVEPOINT one; COMMIT;
Mempunyai:
Arahan ini digunakan untuk menapis hasil berdasarkan fungsi agregat." Kami tidak boleh menggunakan fungsi agregat dalam pernyataan WHERE supaya kami boleh gunakan dalam arahan ini"
Nota: Ini boleh digunakan apabila kita perlu membandingkan menggunakan lajur yang dibuat manakala arahan WHERE boleh digunakan untuk membandingkan menggunakan lajur sedia ada
select Department, sum(Salary) as Salary from employee group by department having sum(Salary) >= 50000;
Dalam
Arahan ini digunakan apabila mereka meminta untuk mengecualikan mana-mana dua/lebih item tertentu
select * from table_name
where colname not in ('Germany', 'France', 'UK');
Berbeza:
Arahan ini digunakan untuk mendapatkan semula data unik sahaja berdasarkan medan yang dipilih.
Select distinct field from table;
SELECT COUNT(DISTINCT salesman_id) FROM orders;
Pertanyaan Berkorelasi
Ia ialah subkueri (pertanyaan bersarang di dalam pertanyaan lain) yang merujuk lajur daripada pertanyaan luar
SELECT EmployeeName, Salary
FROM Employees e1
WHERE Salary > (
SELECT AVG(Salary)
FROM Employees e2
WHERE e1.DepartmentID = e2.DepartmentID
);
Normalisasi
Normalisasi ialah teknik reka bentuk pangkalan data yang digunakan untuk menyusun jadual dengan cara yang mengurangkan lebihan dan meningkatkan integriti data. Matlamat utama normalisasi adalah untuk membahagikan jadual besar kepada bahagian yang lebih kecil dan lebih mudah diurus sambil mengekalkan hubungan antara data
Borang Biasa Pertama (1NF)
Semua nilai dalam lajur adalah atom (tidak boleh dibahagikan).
Setiap lajur mengandungi hanya satu jenis data.
EmployeeID | EmployeeName | Department | PhoneNumbers ---------------------------------------------------- 1 | Alice | HR | 123456, 789012 2 | Bob | IT | 345678
Selepas 1NF:
EmployeeID | EmployeeName | Department | PhoneNumber ---------------------------------------------------- 1 | Alice | HR | 123456 1 | Alice | HR | 789012 2 | Bob | IT | 345678
Borang Biasa Kedua (2NF)
Ia berada dalam 1NF.
Semua atribut bukan kunci bergantung sepenuhnya pada kunci primer (tiada kebergantungan separa).
EmployeeID | EmployeeName | DepartmentID | DepartmentName --------------------------------------------------------- 1 | Alice | 1 | HR 2 | Bob | 2 | IT
Selepas 2NF:
EmployeeID | EmployeeName | DepartmentID --------------------------------------- 1 | Alice | 1 2 | Bob | 2 DepartmentID | DepartmentName ------------------------------ 1 | HR 2 | IT
Bentuk Normal Ketiga (3NF)
Ia berada dalam 2NF.
Semua atribut bergantung secara fungsi hanya pada kunci utama (tiada kebergantungan transitif).
EmployeeID | EmployeeN | DepartmentID | Department | DepartmentLocation -------------------------------------------------------------------------- 1 | Alice | 1 | HR | New York 2 | Bob | 2 | IT | Los Angeles
Selepas 3NF:
EmployeeID | EmployeeN | DepartmentID ---------------------------------------- 1 | Alice | 1 2 | Bob | 2 DepartmentID | DepartmentName | DepartmentLocation ----------------------------------------------- 1 | HR | New York 2 | IT | Los Angeles
Kesatuan:
Arahan ini digunakan untuk menggabungkan hasil dua atau lebih pernyataan SELECT
Select * from table_name WHERE (subject = 'Physics' AND year = 1970) UNION (SELECT * FROM nobel_win WHERE (subject = 'Economics' AND year = 1971));
Had:
Arahan ini digunakan untuk mengehadkan jumlah data yang diambil daripada pertanyaan.
select Department, sum(Salary) as Salary from employee limit 2;
Offset:
Arahan ini digunakan untuk melangkau bilangan baris sebelum mengembalikan hasil.
select Department, sum(Salary) as Salary from employee limit 2 offset 2;
Order By:
This command is used to sort the data based on the field in ascending or descending order.
Data:
create table employees (
id int primary key,
first_name varchar(50),
last_name varchar(50),
salary decimal(10, 2),
department varchar(50)
);
insert into employees (first_name, last_name, salary, department)
values
('John', 'Doe', 50000.00, 'Sales'),
('Jane', 'Smith', 60000.00, 'Marketing'),
('Jim', 'Brown', 60000.00, 'Sales'),
('Alice', 'Johnson', 70000.00, 'Marketing');
select * from employees order by department; select * from employees order by salary desc
Null
This command is used to test for empty values
select * from tablename where colname IS NULL;
Group By
This command is used to arrange similar data into groups using a function.
select department, avg(salary) AS avg_salary from employees group by department;
Like:
This command is used to search a particular pattern in a column.

SELECT * FROM employees WHERE first_name LIKE 'a%';
SELECT * FROM salesman WHERE name BETWEEN 'A' AND 'L';
Wildcard:
Characters used with the LIKE operator to perform pattern matching in string searches.
% - Percent
_ - Underscore
How to print Wildcard characters?
SELECT 'It\'s a beautiful day';
SELECT * FROM table_name WHERE column_name LIKE '%50!%%' ESCAPE '!';
Case
The CASE statement in SQL is used to add conditional logic to queries. It allows you to return different values based on different conditions.
SELECT first_name, last_name, salary,
CASE salary
WHEN 50000 THEN 'Low'
WHEN 60000 THEN 'Medium'
WHEN 70000 THEN 'High'
ELSE 'Unknown'
END AS salary_category
FROM employees;
Display Text
1) Print something
Select "message";
select ' For', ord_date, ',there are', COUNT(ord_no) group by colname;
2) Print numbers in each column
Select 1,2,3;
3) Print some calculation
Select 6x2-1;
4) Print wildcard characters
select colname1,'%',colname2 from tablename;
5) Connect two colnames
select first_name || ' ' || last_name AS colname from employees
6) Use the nth field
select * from orders group by colname order by 2 desc;
Constraints
1) Not Null:
This constraint is used to tell the field that it cannot have null value in a column.
create table employees(
id int(6) not null
);
2) Unique:
This constraint is used to tell the field that it cannot have duplicate value. It can accept NULL values and multiple unique constraints are allowed per table.
create table employees (
id int primary key,
first_name varchar(50) unique
);
3) Primary Key:
This constraint is used to tell the field that uniquely identifies in the table. It cannot accept NULL values and it can have only one primary key per table.
create table employees (
id int primary key
);
4) Foreign Key:
This constraint is used to refer the unique row of another table.
create table employees (
id int primary key
foreign key (id) references owner(id)
);
5) Check:
This constraint is used to check a particular condition for data to be stored.
create table employees (
id int primary key,
age int check (age >= 18)
);
6) Default:
This constraint is used to provide default value for a field.
create table employees (
id int primary key,
age int default 28
);
Aggregate functions
1)Count:
select count(*) as members from employees;
2)Sum:
select sum(salary) as total_amount FROM employees;
3)Average:
select avg(salary) as average_amount FROM employees;
4)Maximum:
select max(salary) as highest_amount FROM employees;
5)Minimum:
select min(salary) as lowest_amount FROM employees;
6)Round:
select round(123.4567, -2) as rounded_value;
Date Functions
1) datediff
select a.id from weather a join weather b on datediff(a.recordDate,b.recordDate)=1 where a.temperature > b.temperature;
2) date_add
select date_add("2017-06-15", interval 10 day);
SECOND
MINUTE
HOUR
DAY
WEEK
MONTH
QUARTER
YEAR
3) date_sub
SELECT DATE_SUB("2017-06-15", INTERVAL 10 DAY);
Joins
Inner Join
This is used to combine two tables based on one common column.
It returns only the rows where there is a match between both tables.
Data
create table employees( employee_id int(2) primary key, first_name varchar(30), last_name varchar(30), department_id int(2) ); create table department( department_id int(2) primary key, department_name varchar(30) ); insert into employees values (1,"John","Dow",10); insert into employees values (2,"Jane","Smith",20); insert into employees values (3,"Jim","Brown",10); insert into employees values (4,"Alice","Johnson",30); insert into department values (10,"Sales"); insert into department values (20,"Marketing"); insert into department values (30,"IT");
select e.employee_id,e.first_name,e.last_name,d.department_name from employees e inner join department d on e.department_id=d.department_id;
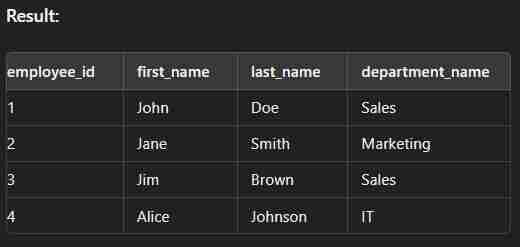
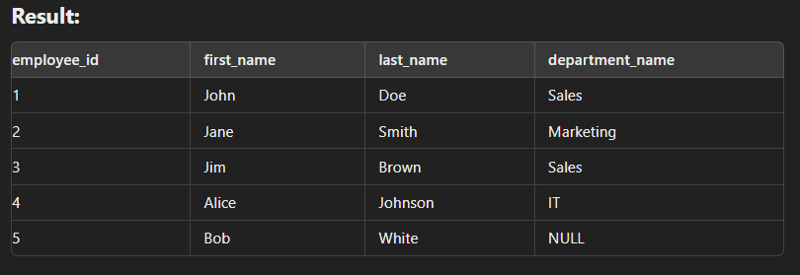
Left Join
This type of join returns all rows from the left table along with the matching rows from the right table. Note: If there are no matching rows in the right side, it return null.
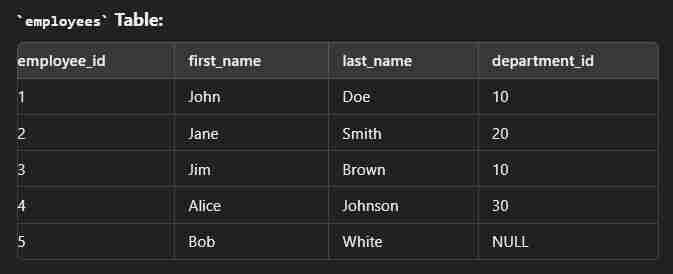
select e.employee_id, e.first_name, e.last_name, d.department_name from employees e left join departments d on e.department_id = d.department_id;
Right Join
This type of join returns all rows from the right table along with the matching rows from the left table. Note: If there are no matching rows in the left side, it returns null.
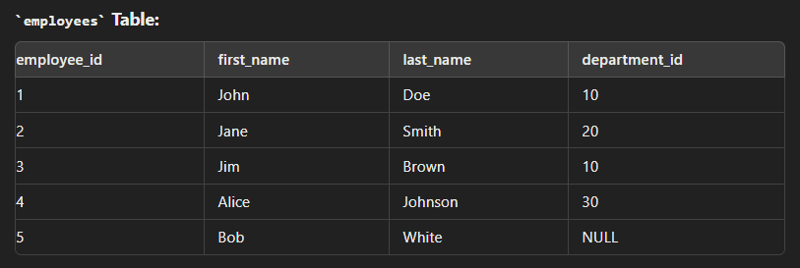
SELECT e.employee_id, e.first_name, e.last_name, d.department_name FROM employees e RIGHT JOIN departments d ON e.department_id = d.department_id;
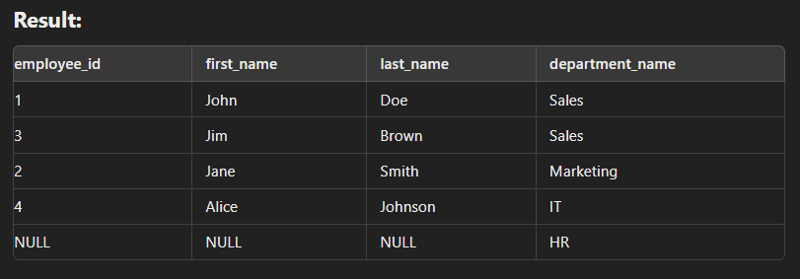
Self Join
This type of join is used to combine with itself especially for creation of new column of same data.
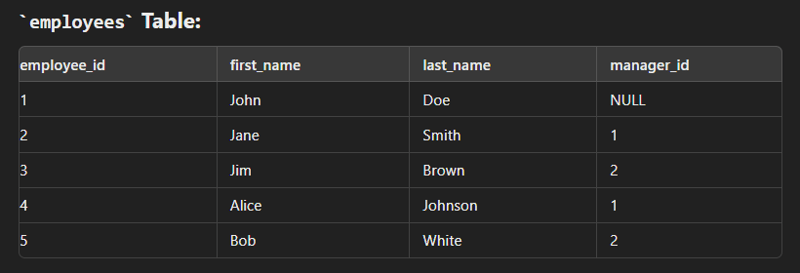
SELECT e.employee_id AS employee_id,
e.first_name AS employee_first_name,
e.last_name AS employee_last_name,
m.first_name AS manager_first_name,
m.last_name AS manager_last_name
FROM employees e
LEFT JOIN employees m ON e.manager_id = m.employee_id;
Full Join/ Full outer join
This type of join is used to combine the result of both left and right join.
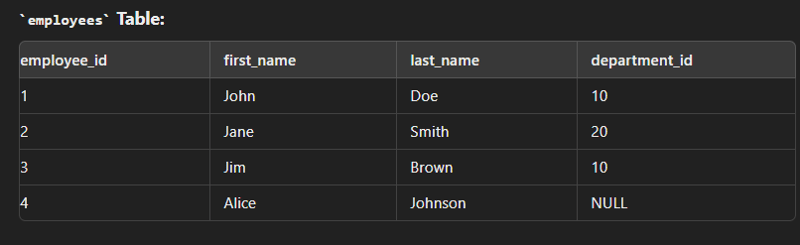
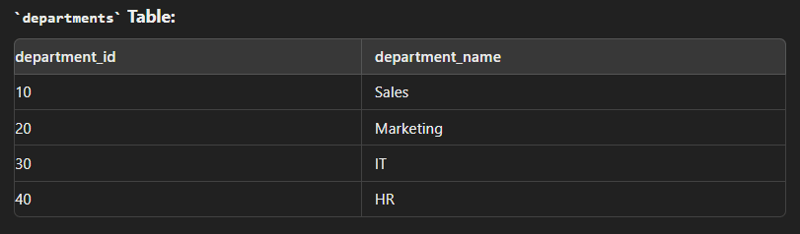
SELECT e.employee_id, e.first_name, e.last_name, d.department_name FROM employees e FULL JOIN departments d ON e.department_id = d.department_id;
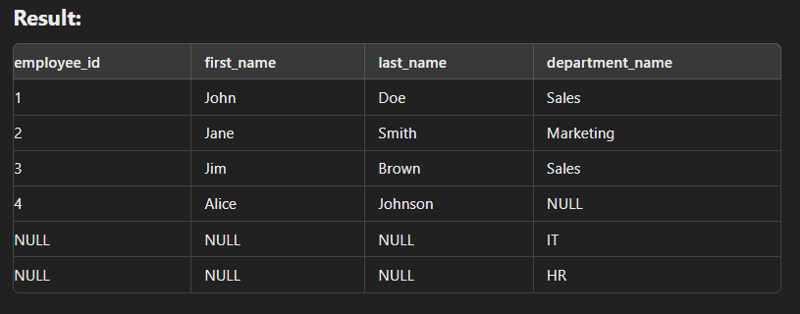
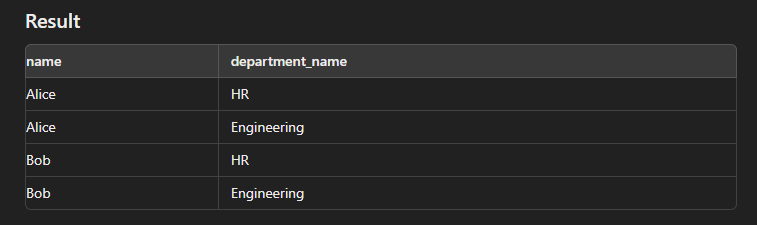
Cross Join
This type of join is used to generate a Cartesian product of two tables.
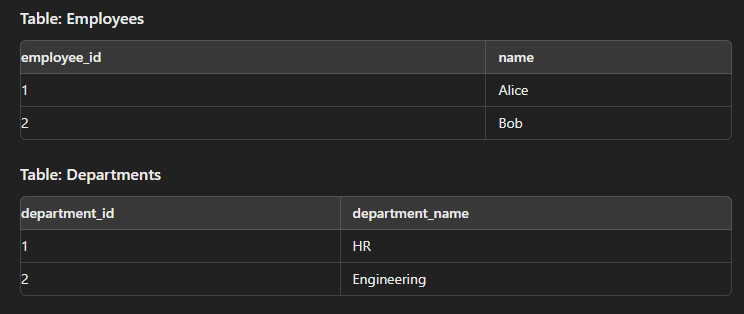
SELECT e.name, d.department_name FROM Employees e CROSS JOIN Departments d;
Nested Query
A nested query, also known as a subquery, is a query within another SQL query. The nested query is executed first, and its result is used by the outer query.
Subqueries can be used in various parts of a SQL statement, including the SELECT clause, FROM clause, WHERE clause, and HAVING clause.
1) Nested Query in SELECT Clause:
SELECT e.first_name, e.last_name,
(SELECT d.department_name
FROM departments d
WHERE d.id = e.department_id) AS department_name
FROM employees e;
2) Nested Query in WHERE Clause:
SELECT first_name, last_name, salary FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
SELECT pro_name, pro_price FROM item_mast WHERE pro_price = (SELECT MIN(pro_price) FROM item_mast);
3) Nested Query in FROM Clause:
SELECT department_id, AVG(salary) AS avg_salary FROM employees GROUP BY department_id;
4) Nested Query with EXISTS:
SELECT customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
Exists
This command is used to test the existence of a particular record. Note: When using EXISTS query, actual data returned by subquery does not matter.
SELECT customer_name
FROM customers c
WHERE EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
SELECT customer_name
FROM customers c
WHERE NOT EXISTS (
SELECT 1
FROM orders o
WHERE o.customer_id = c.customer_id
);
COALESCE
The COALESCE function in SQL is used to return the first non-null expression among its arguments. It is particularly useful for handling NULL values and providing default values when dealing with potentially missing or undefined data.
CREATE TABLE employees (
first_name VARCHAR(50),
middle_name VARCHAR(50),
last_name VARCHAR(50)
);
INSERT INTO employees (first_name, middle_name, last_name) VALUES
('John', NULL, 'Doe'),
('Jane', 'Marie', 'Smith'),
('Emily', NULL, 'Johnson');
SELECT
first_name,
COALESCE(middle_name, 'No Middle Name') AS middle_name,
last_name
FROM
employees;
PL/SQL(Procedural Language/Structured Query Language)
It is Oracle's procedural extension to SQL. If multiple SELECT statements are issued, the network traffic increases significantly very fast. For example, four SELECT statements cause eight network trips. If these statements are part of the PL/SQL block, they are sent to the server as a single unit.
Blocks
They are the fundamental units of execution and organization.
1) Named block
Named blocks are used when creating subroutines. These subroutines are procedures, functions, and packages. The subroutines can be stored in the database and referenced by their names later on.
Ex.
CREATE OR REPLACE PROCEDURE procedure_name (param1 IN datatype, param2 OUT datatype) AS BEGIN -- Executable statements END procedure_name;
2) Anonymous
They are blocks do not have names. As a result, they cannot be stored in the database and referenced later.
DECLARE -- Declarations (optional) BEGIN -- Executable statements EXCEPTION -- Exception handling (optional) END;
Declaration
It contains identifiers such as variables, constants, cursors etc
Ex.
declare v_first_name varchar2(35) ; v_last_name varchar2(35) ; v_counter number := 0 ; v_lname students.lname%TYPE; // takes field datatype from column
Rowtype
DECLARE v_student students%rowtype; BEGIN select * into v_student from students where sid='123456'; DBMS_OUTPUT.PUT_LINE(v_student.lname); DBMS_OUTPUT.PUT_LINE(v_student.major); DBMS_OUTPUT.PUT_LINE(v_student.gpa); END;
Execution
It contains executable statements that allow you to manipulate the variables.
declare v_regno number; v_variable number:=0; begin select regno into v_regno from student where regno=1; dbms_output.put_line(v_regno || ' '|| v_variable); end
Input of text
DECLARE v_inv_value number(8,2); v_price number(8,2); v_quantity number(8,0) := 400; BEGIN v_price := :p_price; v_inv_value := v_price * v_quantity; dbms_output.put_line(v_inv_value); END;
If-else loop
IF rating > 7 THEN
v_message := 'You are great';
ELSIF rating >= 5 THEN
v_message := 'Not bad';
ELSE
v_message := 'Pretty bad';
END IF;
Loops
Simple Loop
declare
begin
for i in 1..5 loop
dbms_output.put_line('Value of i: ' || i);
end loop;
end;
While Loop
declare
counter number := 1;
begin
while counter <= 5 LOOP
dbms_output.put_line('Value of counter: ' || counter);
counter := counter + 1;
end loop;
end;
Loop with Exit
declare
counter number := 1;
begin
loop
exit when counter > 5;
dbms_output.put_line('Value of counter: ' || counter);
counter := counter + 1;
end loop;
end;
Procedure
A series of statements accepting and/or returning
zero variables.
--creating a procedure create or replace procedure proc (var in number) as begin dbms_output.put_line(var); end --calling of procedure begin proc(3); end
Function
A series of statements accepting zero or more variables that returns one value.
create or replace function func(var in number) return number is res number; begin select regno into res from student where regno=var; return res; end --function calling declare var number; begin var :=func(1); dbms_output.put_line(var); end
All types of I/O
p_name IN VARCHAR2 p_lname OUT VARCHAR2 p_salary IN OUT NUMBER
Triggers
DML (Data Manipulation Language) triggers are fired in response to INSERT, UPDATE, or DELETE operations on a table or view.
BEFORE Triggers:
Execute before the DML operation is performed.
AFTER Triggers:
Execute after the DML operation is performed.
INSTEAD OF Triggers:
Execute in place of the DML operation, typically used for views.
Note: :new represents the cid of the new row in the orders table that was just inserted.
create or replace trigger t_name after update on student for each row begin dbms_output.put_line(:NEW.regno); end --after updation update student set name='name' where regno=1;
Window function
SELECT
id,name,gender,
ROW_NUMBER() OVER(
PARTITION BY name
order by gender
) AS row_number
FROM student;
SELECT
employee_id,
department_id,
salary,
RANK() OVER(
PARTITION BY department_id
ORDER BY salary DESC
) AS salary_rank
FROM employees;
ACID Properties:
Atomicity:
All operations within a transaction are treated as a single unit.
Ex. Consider a bank transfer where money is being transferred from one account to another. Atomicity ensures that if the debit from one account succeeds, the credit to the other account will also succeed. If either operation fails, the entire transaction is rolled back to maintain consistency.
Ketekalan:
Konsistensi memastikan bahawa pangkalan data kekal dalam keadaan konsisten sebelum dan selepas transaksi.
Cth. Jika transaksi pemindahan mengurangkan baki satu akaun, ia juga harus meningkatkan baki akaun penerima. Ini mengekalkan keseimbangan keseluruhan sistem.
Pengasingan:
Pengasingan memastikan bahawa pelaksanaan urus niaga serentak menghasilkan keadaan sistem yang akan diperoleh jika urus niaga dilaksanakan secara bersiri, iaitu, satu demi satu.
Cth. Pertimbangkan dua transaksi T1 dan T2. Jika T1 memindahkan wang dari akaun A ke akaun B, dan T2 menyemak baki akaun A, pengasingan memastikan bahawa T2 akan sama ada melihat baki akaun A sebelum pemindahan (jika T1 belum melakukan lagi) atau selepas pemindahan (jika T1 telah melakukan), tetapi bukan keadaan pertengahan.
Ketahanan:
Ketahanan menjamin bahawa sebaik sahaja transaksi dilakukan, kesannya adalah kekal dan bertahan daripada kegagalan sistem. Walaupun sistem ranap atau dimulakan semula, perubahan yang dibuat oleh transaksi tidak hilang.
Jenis Data
1) Jenis Data Berangka
int
perpuluhan(p,q) - p ialah saiz, q ialah ketepatan
2) Jenis Data Rentetan
char(nilai) - maks(8000) && tidak berubah
varchar(nilai) - maks(8000)
teks - saiz terbesar
3) Jenis Data Tarikh
tarikh
masa
masa tarikh
Atas ialah kandungan terperinci Panduan lengkap SQL untuk Temuduga. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!