
Rumah >Peranti teknologi >AI >Rangka kerja penilaian model multimodal lmms-eval dikeluarkan! Liputan komprehensif, kos rendah, pencemaran sifar
Rangka kerja penilaian model multimodal lmms-eval dikeluarkan! Liputan komprehensif, kos rendah, pencemaran sifar

- 王林asal
- 2024-08-21 16:38:07523semak imbas

Lajur AIxiv ialah lajur di mana kandungan akademik dan teknikal diterbitkan di laman web ini. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Dengan penyelidikan yang mendalam tentang model besar, cara mempromosikannya kepada lebih banyak modaliti telah menjadi topik hangat dalam akademik dan industri. Model sumber tertutup besar yang dikeluarkan baru-baru ini seperti GPT-4o dan Claude 3.5 sudah mempunyai keupayaan pemahaman imej yang kukuh, dan model medan sumber terbuka seperti LLaVA-NeXT, MiniCPM dan InternVL juga telah menunjukkan prestasi yang semakin hampir kepada sumber tertutup .
Dalam era "80,000 kilogram per mu" dan "satu SoTA setiap 10 hari", rangka kerja penilaian pelbagai modal yang mudah digunakan, mempunyai piawaian yang telus dan boleh dihasilkan semula telah menjadi semakin penting, dan ini bukan mudah.
Untuk menyelesaikan masalah di atas, penyelidik dari LMMs-Lab Universiti Teknologi Nanyang bersama-sama sumber terbuka LMMs-Eval, yang merupakan rangka kerja penilaian yang direka khas untuk model berskala besar berbilang modal dan menyediakan penilaian model berbilang modal (LMMs). ). Penyelesaian sehenti dan cekap.

Repositori kod: https://github.com/EvolvingLMMs-Lab/lmms-eval
Alamat laman web rasmi: https://lmms-lab.github.io/
- : https://arxiv.org/abs/2407.12772
- Alamat senarai: https://huggingface.co/spaces/lmms-lab/LiveBench

Pelancaran Satu Klik: LMMs-Eval menganjurkan lebih 80 set data (dan semakin berkembang) pada HuggingFace, diubah dengan teliti daripada sumber asal, termasuk semua varian, versi dan pembahagian. Pengguna tidak perlu membuat sebarang persediaan Dengan hanya satu arahan, beberapa set data dan model akan dimuat turun dan diuji secara automatik, dan hasilnya akan tersedia dalam beberapa minit.
Telus dan boleh dihasilkan semula: LMMs-Eval mempunyai alat pengelogan bersatu terbina dalam Setiap soalan yang dijawab oleh model dan sama ada ia betul atau tidak akan direkodkan, memastikan kebolehulangan dan ketelusan. Ia juga memudahkan perbandingan kelebihan dan kekurangan model yang berbeza.
Visi LMMs-Eval ialah model berbilang modal masa hadapan tidak lagi perlu menulis pemprosesan data, inferens dan kod penyerahan mereka sendiri. Dalam persekitaran hari ini di mana set ujian berbilang modal sangat tertumpu, pendekatan ini tidak realistik, dan skor yang diukur sukar untuk dibandingkan secara langsung dengan model lain. Dengan mengakses LMMs-Eval, jurulatih model boleh lebih menumpukan pada menambah baik dan mengoptimumkan model itu sendiri, daripada menghabiskan masa untuk penilaian dan hasil penjajaran.
- "Segitiga Mustahil" Penilaian Matlamat utama LMMs-Eval adalah untuk mencari 1. liputan luas 2. kos rendah 3. kaedah kebocoran data sifar untuk menilai LMM. Walau bagaimanapun, walaupun dengan LMMs-Eval, pasukan pengarang mendapati sukar atau bahkan mustahil untuk melakukan ketiga-tiga pada masa yang sama.
Seperti yang ditunjukkan dalam rajah di bawah, apabila mereka mengembangkan set data penilaian kepada lebih daripada 50, ia menjadi sangat memakan masa untuk melaksanakan penilaian komprehensif set data ini. Tambahan pula, penanda aras ini juga terdedah kepada pencemaran semasa latihan. Untuk tujuan ini, LMMs-Eval mencadangkan LMMs-Eval-Lite untuk mengambil kira liputan luas dan kos rendah. Mereka juga mereka bentuk LiveBench dengan kos rendah dan dengan kebocoran data sifar.
LMMs-Eval-Lite: Penilaian ringan liputan luas
在评测大模型时,往往庞大的参数量和测试任务会使得评测任务的时间和成本急剧上升,因此大家往往会选择使用较小的数据集或是使用特定的数据集进行评测。然而,有限的评测往往会使得对于模型能力的理解有所缺失,为了同时兼顾评测的多样性和评测的成本,LMMs-Eval 推出了LMMs-Eval-Lite

LMMs-Eval-Lite 旨在构建一个简化的基准测试集,以在模型开发过程中提供有用且快速的信号,从而避免现在测试的臃肿问题。如果我们能够找到现有测试集的一个子集,在这上面的模型之间的绝对分数和相对排名与全集保持相似,那么我们可以认为修剪这些数据集是安全的。
为了找到数据集中的数据显着点,LMMs-Eval 首先使用 CLIP 和 BGE 模型将多模态评测数据集转换为向量嵌入的形式并使用 k-greedy 聚类的方法找到了数据显着点。在测试中,这些规模较小的数据集仍然展现出与全集相似的评测能力。

随后LMMs-Eval 使用了相同的方法制作了涵盖更多数据集的Lite 版本,这些数据集旨在帮助人们节省开发中的评测成本,以便快速判断模型性能

LiveBench: LMMs 动态测试
传统基准侧重于使用固定问题和答案的静态评估。随着多模态研究的进展,开源模型在分数比较往往优于商用模型,如 GPT-4V,但在实际用户体验中却有所不及。动态的、用户导向的 Chatbot Arenas 和 WildVision 在模型评估中越来越受欢迎,但是它们需要收集成千上万的用户偏好,评估成本极高。
LiveBench 的核心思想是在一个不断更新的数据集上评估模型的性能,以实现零污染且保持低成本。作者团队从网络上收集评估数据,并构建了一条 pipeline,自动从新闻和社区论坛等网站收集最新的全球信息。为了确保信息的及时性和真实性,作者团队从包括 CNN、BBC、日本朝日新闻和中国新华社等 60 多个新闻媒体,以及 Reddit 等论坛中选择来源。具体步骤如下:
捕捉主页截图并去除广告和非新闻元素。
使用当前最强大的多模态模型(如 GPT4-V、Claude-3-Opus 和 Gemini-1.5-Pro)设计问题和答案集。由另一模型审查和修订
问题,确保准确性和相关性。
人工审查最终的问答集,每月收集约 500 个问题,保留 100-300 个作为最终的 livebench 问题集。
采用 LLaVA-Wilder 和 Vibe-Eval 的评分标准 -- 评分模型根据提供的标准答案评分,得分范围为 [1, 10]。默认评分模型为 GPT-4o,还包括 Claude-3-Opus 和 Gemini 1.5 Pro 作为备选。最终的报告结果将基于得分转换为 0 到 100 的准确率指标。
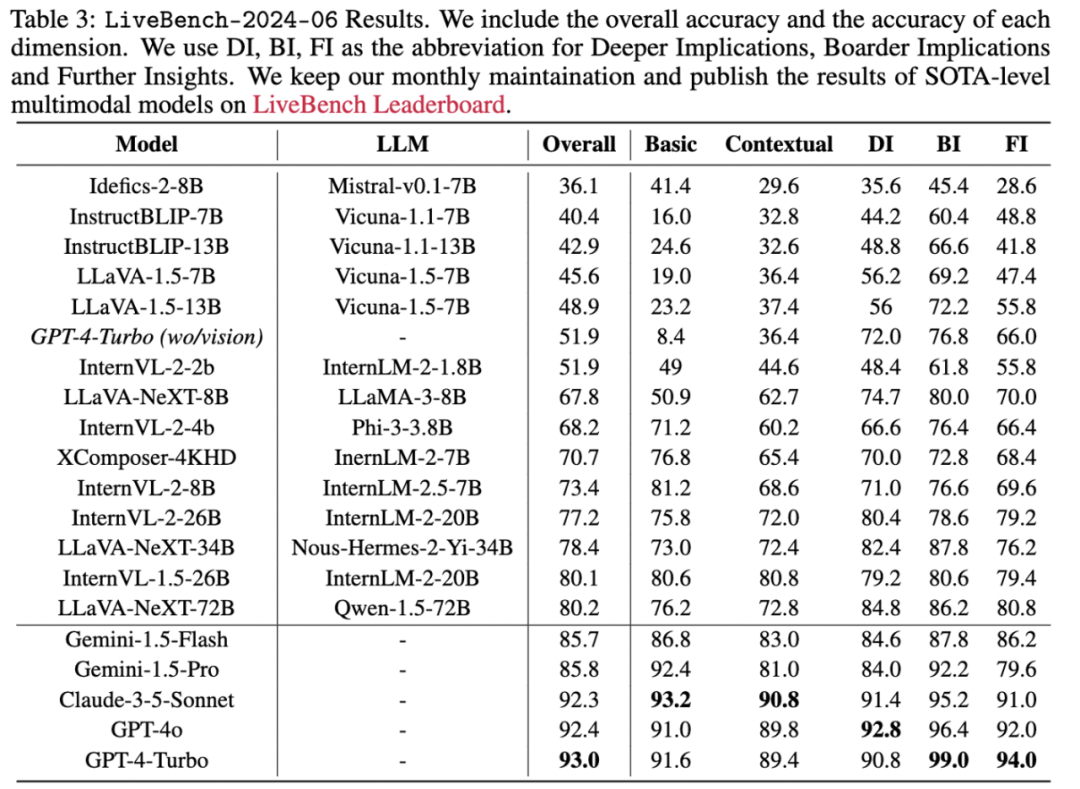
未来也可以在我们动态更新的榜单里查看多模态模型在每个月动态更新的最新评测数据,以及在榜单上的最新评测的结果。
Atas ialah kandungan terperinci Rangka kerja penilaian model multimodal lmms-eval dikeluarkan! Liputan komprehensif, kos rendah, pencemaran sifar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI